一种图像的半监督语义分割方法、装置、设备及存储介质
- 国知局
- 2024-08-22 14:58:16
本发明属于计算机视觉领域,具体涉及一种图像的半监督语义分割方法、装置、设备及存储介质。
背景技术:
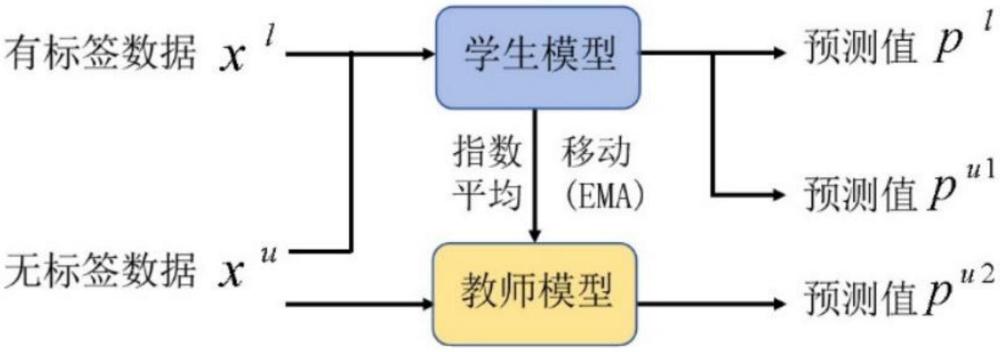
1、近年来,语义分割在自动驾驶领域的应用越来越广泛。在完全监督的语义分割中,对大量像素级注释的需求导致了时间、精力和资金的巨大投资。因此,在现代自动驾驶研究中,由于其能够利用较小的标记数据集,观察到了向半监督语义分割的明显转变。在半监督语义分割领域中存在各种范式,包括伪标记、一致性正则化、基于对比度的方法、对抗性方法等。
2、mean-teacher模型是典型的基于一致性正则化的方法。后面基于一致性正则化的方法都是基于mean-teacher的模型框架来设计的。一致性正则化主要通过两个维度进行操作:数据和特征。通过结合输入图像的强变化和弱变化来增强数据扰动,而特征扰动涉及在模型处理输入图像时在编码器和解码器中引入dropout和t-vat。然而,上述模型主要侧重于增强教师模型,而忽略了学生模型的设计考虑。
3、而学生模型中由于有标签数据数量有限及其分布不均匀,存在容易识别的类数量多,难识别的类反而数量少的问题,经过训练,难识别的类精度得不到太大提升,从而导致最终模型的分割结果不够准确。
技术实现思路
1、为了解决现有技术中由于有标签数据数量有限及其分布不均匀,存在容易识别的类数量多,难识别的类反而数量少的问题,经过训练,难识别的类精度得不到太大提升,从而导致模型的分割结果不够准确的问题,本发明提供了一种图像的半监督语义分割方法、装置、设备及存储介质。
2、为了实现上述目的,本发明提供如下技术方案:
3、一种图像的半监督语义分割方法,包括如下步骤:
4、将图像数据集分为有标签数据集和无标签数据集;
5、将有标签数据输入到学生模型进行语义分割后,根据分割后的数据构建第一预测标签数据集;根据第一预测标签数据集中标签预测值与对应的有标签数据的标签真实值进行对比计算,得到混淆矩阵和标签预测值的置信度;根据置信度的大小判断语义分割结果中表现没有达到设定目标的类,根据混淆矩阵中的没有达到设定目标的类的索引值找到容易混淆的类别,将容易混淆的类别进行弱数据增强得到增强数据集,将增强数据集输入学生模型中进行语义分割后,根据分割后的数据构建第二预测标签数据集;
6、根据第一预测标签数据集对每个标签预测值与对应的标签真实值进行像素级交叉熵损失后得到标签预测值与标签真实值的第一损失值,对每个第一损失值求和获得第一损失函数;根据第二预测标签数据集对每个标签预测值与与对应的标签真实值进行像素级交叉熵损失后得到标签预测值与标签真实值的第二损失值,对每个第二损失值求和获得第二损失函数;将无标签数据集输入至学生模型中进行语义分割后,输出得到第一伪标签预测值,将无标签数据集输入至教师模型中进行语义分割后,输出得到第二伪标签预测值,通过第一和第二伪标签预测值进行像素级交叉熵损失后得到两个伪标签预测值的第三损失值,对每个第三损失值求和获得第三损失函数;
7、将第一损失函数、第二损失函数和第三损失函数求和后获得模型总损失函数;通过总损失函数对学生模型和教师模型的网络参数进行优化更新;
8、将待分割图像输入到优化后的教师模型中进行语义分割后,输出得到语义分割结果。
9、进一步地,所述根据第一预测标签数据集中标签预测值与对应的有标签数据的标签真实值进行对比计算得到混淆矩阵的步骤包括:
10、将有标签数据输入到学生模型中,经过分割网络,得到第一预测标签数据集的预测值矩阵y,矩阵y和真实值矩阵g的大小是类别数c*图片高度h*图片宽度w,首先将y和g展平成大小为c*(h*w)的二维矩阵,公式如下:
11、yflat=reshape(y,(c,h*w)) (1)
12、gflat=reshape(g,(c,h*w)) (2)
13、其中reshape为展平操作,将第一维和第二维合并成一个维度;yflat和gflat分别表示展平后的预测值和真实值;之后计算y矩阵每行中的索引最大值,公式如下:
14、
15、其中argmax为取最大值的索引操作,yindex[i,j]表示当前的像素(i,j)的最大的概率被预测成的类别;然后根据yindex以及gflat将y和g变成大小为类别数c*像素数h*w的one-hot向量,公式如下:
16、
17、
18、如果当前像素(i,j)值是当前列的最大值,则置1,反之,则置0;最后将yone-hot和gone-hot的转置相乘即得到混淆矩阵cm[i,j],代表类别i被预测成类别j的次数;其中混淆矩阵的对角cm[i,i]置成0且cm[i,j]=cm[j,i],公式如下:
19、cm[i,j]=yone-hot[i]*gone-hot[j]t (6)
20、其中t为取转置操作,最后对cm[i,j]取最大值索引,得到最终大小为类别数c*1的混淆矩阵cm[i],公式如下:
21、
22、其中argmax为取最大值索引操作,cm[i]代表类别i最容易被识别成的类别。
23、进一步地,所述根据第一预测标签数据集中标签预测值与对应的有标签数据的标签真实值进行对比计算得到标签预测值的置信度的步骤包括:
24、初始化一个和第一预测标签数据集的预测结果矩阵y大小相同的置信度向量conf,并将其所有元素初始化为0,对于每个类别c,计算其在真实标签下的预测置信度:
25、遍历每个像素位置,将属于该类别的像素位置上的预测概率相加,然后除以属于该类别的像素数量,公式如下:
26、
27、其中,π(·)为指示函数,gt为真实标签值矩阵,y为预测值矩阵,ξ为非0常数。
28、进一步地,所述根据根据置信度的大小判断语义分割结果中表现没有达到设定目标的类,根据混淆矩阵中的没有达到设定目标的类的索引值找到容易混淆的类别,将容易混淆的类别进行弱数据增强得到增强数据集的步骤包括:
29、根据预测标签数据的置信度得到每次训练之后每个类别的表现情况,将置信度小于预先设定的阈值的类划分为表现不好的类;
30、取出第一预测标签数据集图像中表现不好的α类,并根据混淆矩阵找到这α类最容易混淆的β类,在原图中抠去表现不好的α类,留下背景,并在数据集中随机挑选含有β类的数据,抠除背景,只保留这β类,最后将背景与β类数据进行结合,得到新的伪数据,再进行弱数据增强,得到所述增强图像。
31、进一步地,所述弱数据增强的步骤包括在一个数据增强池中随机选择连续的若干个数据增强方式,进行弱数据增强,数据增强池中包括随机裁剪、翻转、模糊和灰度数据增强方式。
32、进一步地,所述总损失函数的关系表达式为:
33、l=ls+λlc+αlu
34、
35、
36、
37、其中,lc是第一交叉熵损失函数,ls是第二交叉熵损失函数,lu是第三交叉熵损失函数,λ表示自适应模糊对比度(aoc)数据增强的贡献值,而α表示无标签数据部分的损失的贡献值,pl1_ij是第二预测标签数据集中第i个有标签数据的第j个像素的预测值,pl2_ij是第一预测标签数据集中第i个有标签数据的第j个像素的预测值,pu_ij是第二伪标签预测值中第i个无标签图像的第j个像素的预测值,是第一伪标签预测值中第i个无标签图像的第j个像素的预测值,yij是第i个有标签图像中第j个像素的真实值,nl和nu表示批量训练中有标签数据和无标签数据的数量,w和h表输入数据图像的宽度和高度,lce表示标准的像素级交叉熵损失。
38、一种图像的半监督语义分割装置,包括:
39、数据集模块,用于将图像数据集分为有标签数据集和无标签数据集;
40、第一处理模块,用于将有标签数据输入到学生模型进行语义分割后,根据分割后的数据构建第一预测标签数据集;根据第一预测标签数据集中标签预测值与对应的有标签数据的标签真实值进行对比计算,得到混淆矩阵和标签预测值的置信度;根据置信度的大小判断语义分割结果中表现没有达到设定目标的类,根据混淆矩阵中的没有达到设定目标的类的索引值找到容易混淆的类别,将容易混淆的类别进行弱数据增强得到增强数据集,将增强数据集输入学生模型中进行语义分割后,根据分割后的数据构建第二预测标签数据集;
41、第二处理模块,用于根据第一预测标签数据集对每个标签预测值与对应的标签真实值进行像素级交叉熵损失后得到标签预测值与标签真实值的第一损失值,对每个第一损失值求和获得第一损失函数;根据第二预测标签数据集对每个标签预测值与与对应的标签真实值进行像素级交叉熵损失后得到标签预测值与标签真实值的第二损失值,对每个第二损失值求和获得第二损失函数;将无标签数据集输入至学生模型中进行语义分割后,输出得到第一伪标签预测值,将无标签数据集输入至教师模型中进行语义分割后,输出得到第二伪标签预测值,通过第一和第二伪标签预测值进行像素级交叉熵损失后得到两个伪标签预测值的第三损失值,对每个第三损失值求和获得第三损失函数;
42、第三处理模块,用于将第一损失函数、第二损失函数和第三损失函数求和后获得模型总损失函数;通过总损失函数对学生模型和教师模型的网络参数进行优化更新;
43、结果获取模块,用于将待分割图像输入到优化后的教师模型中进行语义分割后,输出得到语义分割结果。
44、一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机执行指令,所述处理器执行所述存储器存储的计算机执行指令,以实现如上所述的一种图像的半监督语义分割方法。
45、一种计算机可读存储介质,所述计算机可读存储介质用于储存计算机执行指令,所述计算机执行指令被处理器执行时用于实现如上所述的一种图像的半监督语义分割方法。
46、本发明提供的图像的半监督语义分割方法具有以下有益效果:
47、本发明将有标签数据输入到学生模型中,获得第一预测标签数据集;根据第一预测标签数据集的分割结果计算得到混淆矩阵和置信度,根据置信度和混淆矩阵获得分割结果中表现没有达到设定目标的类并进行弱数据增强得到增强数据集,将增强数据集输入学生模型中得到第二预测标签数据集;根据第一预测标签数据集与对应的标签真实值获得第一损失函数;根据第二预测标签数据集与对应的标签真实值获得第二损失函数;将无标签数据集输入至学生模型,得到第一伪标签预测值,将无标签数据集输入至教师模型,得到第二伪标签预测值,通过第一和第二伪标签预测值获得第三损失函数;根据三个损失函数获得总损失函数;通过总损失函数实现学生模型和教师模型的网络参数的更新优化;通过优化后的教师模型实现对待处理图像的语义分割。
48、由于有标签数据数量有限及其分布不均匀,存在容易识别的类数量多,难识别的类反而数量少的问题,经过训练,难识别的类精度得不到太大提升。针对此类问题,本发明的增强数据集是将表现没有达到设定目标的类及其容易混淆的类作为新的数据放进学生模型中进行训练,加强对其的训练强度,这样做的目的是为了使表现弱的类以及其容易混淆的类放在一起训练,使模型更能深刻理解到这些类的区别,以此来提升模型的分割精度。本方案通过将增强数据集和有标签数据集分别输入到学生模型中,构建对应的损失函数,再将无标签数据分别输入到学生模型和教师模型中并获得对应的损失函数,通过得到的所有损失函数,来对分割模型的参数进行优化,在整体上提升了模型分割结果准确性。
本文地址:https://www.jishuxx.com/zhuanli/20240822/280630.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表