一种低样本多语种的合成语音克隆方法及系统与流程
- 国知局
- 2024-08-22 15:05:14
本发明属于语音合成,尤其涉及一种低样本多语种的合成语音克隆方法及系统。
背景技术:
1、目前,语音合成技术主要基于深度学习算法,特别是生成对抗网络(gans)和自编码器结构,这些技术能够从大量语音数据中学习并模拟特定说话人的音色。尽管在处理大量数据集时表现良好,能够生成自然流畅的语音,但现有技术存在一些显著的局限性。
2、首先,现有技术高度依赖于大量的语音样本,这限制了其在数据稀缺的语种或方言上的应用。其一,数据的收集、处理和训练过程不仅耗费时间,而且成本高昂,这在资源有限的情况下尤为突出。其二,传统技术难以根据用户的个性化需求快速调整语音合成的音色,限制了其在个性化服务领域的应用。其三,在需要快速响应的应用场景中,现有技术可能无法及时完成音色的提取和合成。其四,现有技术在生成具有丰富表现力和多样性的音色方面仍有局限,且大多数技术专注于单一语种的语音合成,缺乏对多语种的广泛适应性,鉴于此,我们提出了一种低样本多语种的合成语音克隆方法及系统。
技术实现思路
1、本发明的目的在于提供一种低样本多语种的合成语音克隆方法及系统,以解决上述背景技术中提出的问题。
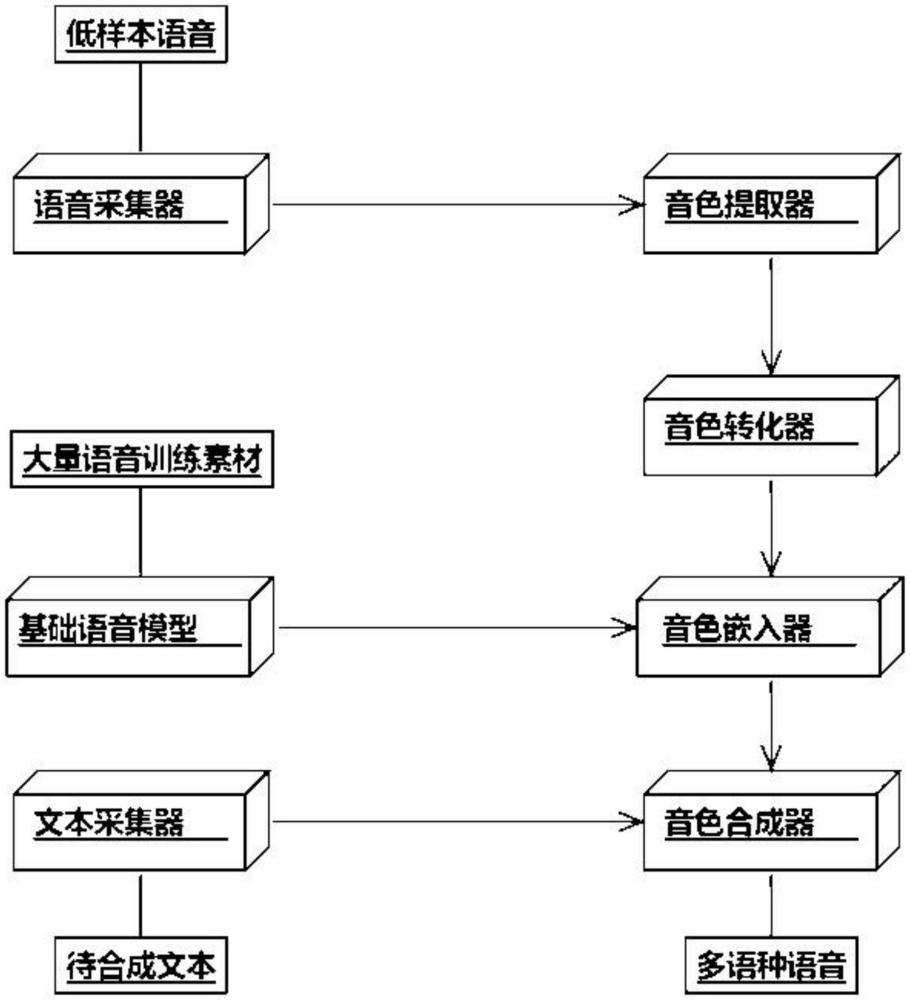
2、有鉴于此,本发明提供一种低样本多语种的合成语音克隆系统,包括:
3、语音采集器:整个语音克隆合成系统的前端部分,负责从用户那里实时地收集语音样本;该设备能够捕捉用户的语音信号,包括语调和发音特征,并将这些信号转换成数字格式,以便于后续的处理和分析,高质量的语音采集对于确保合成语音的自然度和准确性至关重要;
4、音色提取器:从采集到的语音样本中分析和提取关键的音色特征;这些特征包括音高、音色、强度等,它们共同决定了一个人语音的独特性,音色提取器利用先进的语音分析技术,如傅里叶变换或深度学习算法,来识别和提取这些特征,为音色的转换和嵌入打下基础;
5、音色转化器:音色转化器负责将提取的音色特征转换为标准化特征向量,这一转换过程是音色嵌入前的关键步骤,通过采用信号处理技术和机器学习算法,音色转化器确保了音色特征的准确性和可用性,为生成具有个性化音色特征的语音提供了基础;
6、音色嵌入器:音色嵌入器将转换后的音色特征应用到基础语音模型中,以生成具有目标音色特征的语音输出,该服务通过深度学习技术,将音色特征嵌入到语音合成模型的参数中,从而生成与目标音色相匹配的语音信号;
7、基础语音模型:基础语音模型是语音合成系统的核心组件,主要负责将文本转换为语音;该模型利用生成对抗网络(gans)在大量语音数据上进行训练,以生成高质量的语音输出,它不仅能够处理多种语言和方言,还适应于不同的语调和情感表达,从而提供灵活且自然的语音合成能力;
8、文本采集器:文本采集器作为语音合成系统的输入模块,负责接收并处理用户的文本数据;它提供一个用户友好的界面,允许用户输入或上传希望转换成语音的文本内容;此外,文本采集器还可以集成自然语言处理(nlp)技术,以优化文本的理解和预处理,确保语音合成的准确性和流畅性;
9、音色合成器:音色合成器是语音合成过程的最终阶段,它将嵌入了音色特征的语音模型输出转换为最终的语音信号,该服务结合了音色嵌入器的输出和基础语音模型的文本到语音转换能力,生成最终的合成语音,音色合成器还需要确保合成语音的流畅性和自然度,以提供高质量的语音输出。
10、一种低样本多语种的合成语音克隆方法,包括以下步骤:
11、步骤s1、语音采集器采集低样本语音;
12、步骤s2、语音采集器将数据提供给音色提取器:采集的语音样本通过数字信号处理技术进行预处理,包括去噪和归一化,然后传输给音色提取器,这一步骤保证了音色提取的准确性,为后续的音色转换提供了高质量的输入;
13、步骤s3、音色提取器将数据提供给音色转化器:音色提取器运用声学特征分析技术,如梅尔频率倒谱系数(mfccs)提取,识别出语音中的关键音色特征,这些特征随后被传递给音色转化器,进行进一步的处理;
14、步骤4、音色转化器将数据提供给音色嵌入器;
15、步骤s5、通过对抗生成网络(gans)训练出基础语音模型;
16、步骤s6、基础语音模型将模型特征提供给音色嵌入器;
17、步骤s7、音色嵌入器将数据提供给音色合成器:音色嵌入器将嵌入了音色特征的语音数据,通过深度学习框架,如长短时记忆网络(lstm),传递给音色合成器,lstm在此过程中用于处理语音信号的时间依赖性,确保合成语音的连贯性和自然度;
18、步骤s8、文本采集器采集待合成文本:文本采集器不仅支持常规文本输入,还集成了自然语言理解(nlu)模块,以解析用户的文本输入,理解其语义内容和语境,从而为语音合成提供更丰富的信息;
19、步骤s9、文本采集器将文本数据处理后给音色合成器;
20、步骤s10、音色合成器合成与低样本语音一样音色的多语种语音:音色合成器综合了文本信息、音色特征和基础语音模型的输出,通过声码器技术,如wavenet,生成最终的语音信号,合成的语音不仅保留了原始样本的音色特征,还能够适应多语种环境,实现高质量的语音输出。
21、在上述技术方案中,进一步的,所述步骤s1中语音采集器采用高保真麦克风阵列,以高采样率捕获用户的语音样本,采集过程考虑了环境噪声抑制和声音信号的清晰度,确保了样本的质量,为音色的准确提取奠定了基础。
22、在上述技术方案中,进一步的,所述步骤s4中音色转化器利用机器学习算法,如支持向量回归(svr),将音色特征映射到一个高维空间,以便于音色嵌入器进行音色的个性化调整。
23、在上述技术方案中,进一步的,所述步骤s5中基础语音模型的构建基于gans,其中包括生成器和判别器的对抗过程,生成器负责产生逼真的语音信号,而判别器则评估生成语音的真实性,通过这种对抗训练,模型能够学习到语音的复杂结构,并生成自然流畅的语音。
24、在上述技术方案中,进一步的,所述步骤s6中基础语音模型生成的通用语音特征,如音素和语调模式,被传递给音色嵌入器,这些特征与音色转化器提供的特征相结合,以生成具有特定音色特征的语音信号。
25、在上述技术方案中,进一步的,所述步骤s9中文本数据经过文本采集器的预处理,包括分词、词性标注和句法解析,然后将文本的语义信息和结构化表示传递给音色合成器。
26、本发明的有益效果是:
27、1.该低样本多语种的合成语音克隆方法及系统,通过对音色提取、音色转换、音色嵌入和音色合成等步骤进行重新调整和改进,提供一个低样本、多语种的语音克隆合成系统。该系统能够利用少量语音样本实现高质量的语音合成,同时具备良好的实时性和广泛的语种适应性,克服了现有技术的局限性,满足了实时应用场景的需求,并拓宽了语音合成技术的应用范围。
28、2.该低样本多语种的合成语音克隆方法及系统,语音采集器、音色提取器、音色转化器、音色嵌入器、基础语音模型以及音色合成器的配合最终将嵌入了音色特征的语音模型输出转换为最终的语音信号,该服务结合了音色嵌入器的输出和基础语音模型的文本到语音转换能力,生成最终的合成语音,音色合成器还需要确保合成语音的流畅性和自然度,以提供高质量的语音输出。
本文地址:https://www.jishuxx.com/zhuanli/20240822/281080.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
一种辅助钢琴作曲设备
下一篇
返回列表