三维粗粒度可重构计算阵列芯片
- 国知局
- 2024-09-05 14:25:06
本发明涉及数字芯片架构设计,具体地,涉及一种三维粗粒度可重构计算阵列芯片。
背景技术:
1、自从20世纪五十年代集成电路技术诞生以来,集成电路芯片已经成为电子系统的核心部件,成为人们日常生活中不可或缺的一部分。随着微电子集成制造工艺技术的不断发展,集成电路芯片面临功能不断增多、功耗不断增大、集成度不断提升的要求,研究人员采用了高k金属栅极、多栅极晶体管等新型技术来降低半导体芯片的能耗,使得集成电路技术始终跟随摩尔定律的趋势发展。
2、在半导体工艺随摩尔定律发展五十多年后,先进的半导体产业技术节点已进入7nm制程,最新的手机芯片已达到3nm制程,逐步接近半导体晶体管器件结构的物理极限。在新的先进工艺节点下,通过工艺技术更新换代获得的集成电路性能提升相对于付出的昂贵工艺代价而言,已经没有明显的性能性价比优势。业界普遍认为,摩尔定律即将终结,这种情况下,以三维集成电路技术为代表的新型技术应运而生,以三维系统级技术为核心的先进封装技术将引领集成电路技术进入超越摩尔定律(more than moore)时代。
3、三维集成电路(3d ic)技术是一种在传统平面集成技术的基础上,将不同类型、不同工艺、不同功能的芯片,采用堆叠的方式集成在同一个封装体上的新兴设计方法,它在垂直方向上整合了多层芯片,为电子设备的高性能和低功耗提供了新的可能性。与传统的二维芯片设计不同,三维芯片设计可以实现更高的器件密度、更短的信号传输路径,以及更高的运算性能,从而为多种应用场景提供了更优越的解决方案。典型的三维集成技术为基于tsv的三维封装和倒装芯片封装的结合。首先通过芯片倒装技术,将上层芯片倒装与下层芯片的微凸点焊球直接连接,这样可以避免连接点引入的高频寄生参数,提高了集成度。接着在下层芯片中制作垂直硅通孔实现芯片信号的垂直互连,再通过rdl实现信号水平互连,实现整个芯片的封装。
4、粗粒度可重构阵列(coarse-grained reconfigurable architecture,cgra)是一种高层次的可重构技术,将计算部分集成为可配置的处理单元,通过指令或配置包对可编程的执行阵列进行配置,可以达到很高的配置速度,并且可重构的数据位宽较大,可重构自由度较高。而传统的二维cgra需要大量的片上存储器面积,无法适应日益增长的算力需求,通过设计三维cgra则能很好解决算力瓶颈,提高整体性能。
5、专利文献cn117076384a公开了本发明提供了一种计算装置、存内计算加速系统,计算装置包括多个计算核模块,计算核模块包括:核内控制器单元、开关阵列单元、存算单元组、第一驱动单元组、第一计算单元组、第二驱动单元组以及第二计算单元组,核内控制器单元用于根据配置信息,向开关阵列单元发送第一连接指令,向存算单元组发送第二连接指令,开关阵列单元用于执行第一连接指令,第一驱动单元组和第二驱动单元组用于按列或行驱动存算单元组,存算单元组用于执行第二连接指令,并执行存内计算得到存内计算结果,第一计算单元组和第二计算单元组用于对存内计算结果执行预设计算操作得到计算结果,可支持多种算法和神经网络算子。然而该专利无法完全解决目前存在的技术问题,也无法满足本发明的需求。
技术实现思路
1、针对现有技术中的缺陷,本发明的目的是提供一种三维粗粒度可重构计算阵列芯片。
2、根据本发明提供的三维粗粒度可重构计算阵列芯片,包括:控制系统、粗粒度可重构单元和存储系统;
3、所述控制系统包括riscv核、axi总线和dma模块;riscv控制核负责启动整个芯片、控制计算阵列的执行与交互,针对risc-v主处理器和计算核心组成的异构架构系统,riscv控制核负责两种架构之间的任务管理以及计算核心上运行任务的调度;axi总线用于将各外设模块连接至riscv控制核,并完成riscv控制核和外设模块之间的通讯及数据传输;dma模块负责将外部存储中数据搬运至片上存储,实现高速、高带宽的异步数据传输;
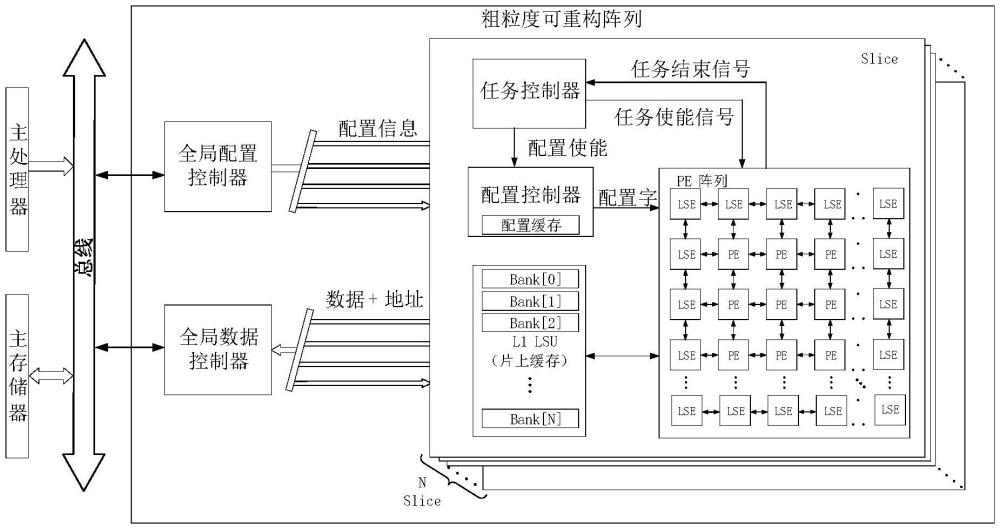
4、所述粗粒度可重构单元包括算术逻辑单元、配置寄存器和数据寄存器,通过对算术逻辑单元配置不同的操作码实现可重构计算,各个算术逻辑单元通过拓扑结构完成连接,用户通过编译器控制数据流向从而流经整个系统,通过多路选择器决定算术逻辑单元操作数的来源完成不同的运算进而实现可重构计算;配置寄存器负责将程序代码中的静态特征映射为pe阵列中的alu配置以及数据通路;配置寄存器中保存一个pe的配置码,该配置码中的一位或多位作为pe中的各个多路选择器的选择端,从而改变数据通路;
5、所述存储系统采用分布式存储架构,包含多个与粗粒度可重构单元匹配的存储阵列,存储阵列中包含多组数据阵列和标签阵列,直接与计算阵列进行数据交互。
6、优选地,三维堆叠芯片通过三维堆叠的方式进行设计与制造,三维堆叠芯片由多层裸芯组成,至少包括一层计算层芯片和多层存储层芯片;
7、计算层包括多个定点计算阵列和浮点计算阵列、一个risc-v控制核、一个pll模块和一个ddrmc模块;定点计算阵列由多个定点数计算单元组成,用于执行各种算术和逻辑运算;浮点计算阵列由多个浮点数计算单元组成,用于执行各种算术和逻辑运算;risc-v控制核用于控制整个soc系统的启动、运行及数据调度;pll模块负责生成具有期望频率和相位的稳定的时钟信号;ddrmc模块负责管理和控制片外ddr模块,完成ddr模块的初始化、数据传输以及系统通信;
8、存储层包含多个存储阵列及相关控制单元。
9、优选地,定点计算阵列和浮点计算阵列内部包含多个负责完成数据计算的计算单元,负责管理访存的访存单元,负责平衡各条数据路径的延时模块以及负责转发控制信号的仲裁模块。
10、优选地,三维堆叠芯片多层之间,通过混合连接和贯穿正面金属层的长硅通孔tsv进行互连,上层芯片供电及关键信号传输依靠不同芯片层的tsv,底层芯片背面金属层通过c4凸点与印刷电路板pcb相连。
11、优选地,三维堆叠芯片的第一层芯片在顶层有重布线层,采用倒装封装的方式与下层芯片相连;其他层芯片包括顶层和底层两层重布线层。
12、优选地,主处理器、主存储器、粗粒度可重构计算阵列cgra均挂载在总线下,采用risc-v isa设计的主处理器负责控制计算阵列的执行与交互;
13、主存储器负责给计算阵列提供原始数据并存储最终的计算结果;
14、cgra为计算密集型应用提供高算力,以协处理器的形式挂载在总线下,cgra内部包含全局配置控制器、全局数据控制器、直接存储访问dma和多个独立的相同的切片slice计算阵列;全局配置控制器负责从主存中读取配置信息并进行第一步解码,根据配置信息中的标号将配置包分发给对应的slice;全局数据控制器管理不同slice发送的访存请求;对读写请求分别进行仲裁并将仲裁的结果记录在两个独立的请求队列中,同时对相同的读请求进行合并与记录,来自不同slice的相同读请求在数据返回的时候同时广播到不同slice;通过接口转换模块将来自配置控制器和数据控制器的请求转换成满足总线协议的交互信号;每个slice包括本地的配置控制器、片上缓存以及可重构片上阵列;配置控制器负责配置包的二次解析以及任务的调度,配置完成之后任务由数据流驱动,在片上阵列中自主完成;片上缓存使用sram搭建,负责处理来自阵列的访存请求;计算阵列基于内部的计算单元形成对应的数据流,通过系统内核的配置,数据流在经过计算单元时完成特定算法的加速。
15、优选地,主处理器依据多级的高级微控制器总线架构amba总线进行划区设计,包括axi子系统、ahb子系统以及apb子系统;
16、axi子系统为处理器的核心,由一个六级流水risc-v内核提供系统控制,并搭配粗粒度可重构阵列提供片上算力,axi子系统还提供片上的高速存储空间,其中,内核系统拥有一级指令缓存以及数据缓存,同时还设有紧耦合的本地存储空间;计算阵列为其运算单元pe阵列配备存储空间,以缓存在推理运算过程产生的中间数据;内核与cgra在axi总线上有一个二级缓存;
17、axi子系统、ahb子系统为soc提供额外功能,包括大容量低速存储、交互外设以及系统控制;对于ahb子系统,rom模块提供片上的非易失性存储空间用以存储片上系统的启动代码,外设qspi被预期连接片外板级的flash芯片组,以此为片上系统拓展大容量的存储空间,这些存储空间被计划为系统存储复杂的推理代码、推理配置信息以及权重数据;
18、apb子系统通过外设uart完成与外界的信息交互,为内核提供系统控制的对象。
19、优选地,计算阵列在执行计算密集型应用时,将应用拆分成多个子任务执行,设计基于risc-v的任务管理机制,整体的机制框架运行在异构架构系统上,异构系统的设计包括主处理器、异构计算核心、两种架构之间的任务管理机制以及主处理器上运行的任务调度系统;其中,任务调度系统包括描述任务间关系的任务模型、异构计算核心的异构模型以及结合两种模型设计的任务调度算法;任务管理机制包括对任务信息整合的模块、任务队列的管理模块以及两种架构互联的主机接口。
20、优选地,单个slice阵列包含计算单元pe、访存单元lse、fifo存储器和arb单元;pe负责核心计算,包括逻辑运算、算术运算;lse负责管理访存需求,使得处理器向存储器发出访问请求同时存储器给予回复,lse频繁与片上存储器和片外存储器进行交互;fifo在计算路径中加入延时,消除pe在数据传输过程中因为循环控制、访存、数据流成环原因产生的路径不平衡现象,如果需要提供预设长延时,则将多个fifo串接起来以满足对缓存容量的需求;arb负责转发控制信号,保持数据流同步,使数据流图解耦为无环图。
21、优选地,计算单元包括数据寄存器、配置寄存器和算术逻辑单元alu;
22、数据寄存器负责在空间流水化执行的过程中提供用于切流水的寄存器并实现操作数匹配的控制;数据寄存器划分输入寄存器buffer和输出寄存器,输入寄存器为算术逻辑单元提供数据输入,包含两层的深度用于实现double-buffer,使从上一级pe读取输入和向alu进行输出能够同时进行,当输入端两个数据同时就绪时,输入寄存器将两个数据同时输出到alu的输入,激活alu进行计算,这一操作数对齐功能能够在流水线存在气泡时保证功能正确;输出寄存器用于在alu计算和互连延时之间打一拍从而减少关键路径的延时;
23、配置寄存器负责将程序代码中的静态特征映射为pe阵列中的alu配置以及数据通路,配置寄存器中保存着一个pe的配置码,这个配置码中的一位或多位将作为pe中的各个多路选择器的选择端,从而改变数据通路;
24、算术逻辑单元通过将代表不同算子的操作码opcode在配置期配置到alu中,从而完成不同的计算任务。
25、与现有技术相比,本发明具有如下的有益效果:
26、1、本发明通过可重构的计算形式、多层次的存储结构、高效的传输方法等多维度异构混合型芯片架构设计,通过高能效比的运算、大容量存储以及高带宽通信等方式实现了大规模并行运算和高通量信息处理;
27、2、本发明实现了高速低功耗的数据运算单元,降低了高性能密集计算处理器中数据运算和传输的功耗,同时本发明基于实际设计和工艺需求,改进了整体芯片设计,研究了适用于三维芯片的计算单元设计;
28、3、本发明从架构、算法、电路多层次研究了单精度浮点乘加运算的浮点流水实现方式,实现了较低的功耗,同时研究了片上高速、大容量、高密度静态存储器的设计方法,实现了高可靠性、高性能的片上大容量存储器集成;
29、4、本发明实现了三维堆叠的计算阵列芯片架构设计,通过将计算阵列和存储阵列分配至不同的裸芯,并针对性设计三维互连架构,大幅度降低了二维平面的面积,实现了性能的大幅度提升。
本文地址:https://www.jishuxx.com/zhuanli/20240905/286346.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表