具有低密度奇偶校验旋转器的通信装置及其方法与流程
- 国知局
- 2024-09-05 15:06:22
本发明的领域涉及一种用于低密度奇偶校验(ldpc)编码和解码的ldpc旋转器电路、通信装置以及用于ldpc编码器或解码器中ldpc旋转的计算的方法。本发明的领域适用于但不限于用于当前和未来几代通信标准的信道编码。
背景技术:
1、ldpc编码
2、如图1所示,低密度奇偶校验(ldpc)码可以用于保护数据免受在不可靠传输或存储期间强加的错误。数据通常由包含k个数据符号的向量表示,每个数据符号都可以取“0”到“m-1”范围内的值,其中m是代码的基数。虽然已对非二进制ldpc码的主题进行了广泛的研究,其中m通常采用集合{4、8、16、...}中的值,但是在实际应用中通常采用m=2的二进制ldpc码。因此,为了简单起见,该背景讨论的其余部分假定数据向量102包括k个位,其中每一位可以取“0”或“1”的值。
3、已知的ldpc码使用两个过程进行操作,其中第一过程包括在不可靠传输或存储之前的ldpc编码,并且第二过程包括之后的ldpc解码。ldpc编码器103和解码器104必须采用兼容的参数化,这可以由具有n’列、n'-k行并填充有二进制值“0”和“1”的奇偶校验矩阵(pcm)指定。
4、ldpc编码使用pcm h将k个数据位的向量x 102转换为n’个编码位的向量y 105,其中n’大于k。这通常通过将编码位向量中的前k位(称为其系统位)设置为等于向量x 102的k个数据位,然后设置剩余的n'-k位(称为奇偶校验位)来实现,使得伽罗华域gf(m)中的y.h=0,其中“0”是包含n'-k个0值位的校正子向量。正如本领域所理解的,“伽罗华域”表示其中m=2意味着具有算术运算的二进制+映射到xor函数的情况。因此,可以说pcm中的前k列对应于向量x 102的数据位,而所有列的集合对应于向量y 105的n个编码位。
5、在不可靠的存储或传输期间,n’个编码位的向量y 105容易出错,并且通常被转换为n’个编码软比特的向量106,这表示向量y 105的n’个编码位中的每一个有多大可能具有“0”或“1”的值。通常,每个软比特都使用对数似然比(llr)表示,其中:
6、
7、因此,为了简单起见,本背景讨论的其余部分假定所有软比特均使用llr表示。
8、ldpc解码104然后可以使用pcm将n’个编码llr的向量106转换成k个解码位107的向量。假设在传输或存储期间引入的错误不太严重,k个解码位107通常是输入到编码器103中的向量x 102的k个数据位的再现。
9、3gpp新无线电ldpc代码
10、返回参考图1,示出了第三代合作伙伴计划(3gpp)新无线电(nr)中的ldpc编码和相关信号处理功能的已知示意图。如图1所示,在用于第五代(5g)移动通信[1]的3gpp nr标准中采用ldpc码来保护数据免受传输错误的影响。在此申请中,102的k个数据位形成为三个独立位向量的级联,其中第一向量包含k'-l个信息位108,第二向量包含由循环冗余校验(crc)编码器109引入的l个位并且第三向量包含由填充位插入110引入的k-k’个位。在ldpc编码103之后,速率匹配111用于将n’个编码位的合成向量105转换为er个速率匹配位112的向量。在不可靠传输之后,降速率匹配113用于将er速率匹配的llr 114的向量转换成n’编码的llr 106的向量,其被输入到ldpc解码器104中。在此,n’个编码的llr 106还可以包括来自在混合自动重复请求(harq)过程中的先前传输期间接收的并使用harq缓冲器115存储的llr的贡献。在ldpc解码之后,填充位移除116可以用于从k个解码位107的向量中移除k-k’个填充位。然后可以使用crc解码器117来检查k’个解码位118的合成向量内的crc,以便确定是否存在任何未校正的传输错误。如果不是,则crc解码器可以移除l个crc位并输出k'-l个解码信息位119。无论哪种方式,crc解码器也可以输出二进制标志120,以指示crc校验是否成功。
11、3gpp新无线电ldpc码是由从两个基图(称为bg1和bg2)导出的pcm指定的。图2和图3分别示出了来自3gpp新无线电的bg1 200和bg2 300的已知表示。每个基图都包含矩阵,其中填充了二进制值“0”和“1”。bg1 200具有n1=nc,1+ne,1=68列,被分成左边的nc,1=26个核心列201和右边的ne,1=42个扩展列202。bg1 200具有m1=mc,1+ne,1=46行,被分成顶部的mc,1=4个核心行203和底部的me,1=ne,1=42个扩展行204。同时,bg2 300具有n2=nc,2+ne,2=52列,被分成左边的nc,2=14个核心列301和和右边的ne,2=38个扩展列302。bg2 300具有m2=mc,2+ne,2=42行,被分成顶部的mc,2=4个核心行303和底部的me,2=ne,2=38个扩展行304。
12、在两个基图中,由核心列201和301以及核心行203和303的交集形成的子矩阵密集地填充有二进制值“1”。实际上,在bg1 200中的每个核心行203中,nc,1=26个核心列201中有19个具有二进制值“1”。同时,图3中的nc,2=14个核心列301中多达10个在bg2 300中的每个核心行303中具有二进制值“1”。除了被称为删余核心列的前两列之外,由核心列201和301与扩展行204和304的交集形成的子矩阵被稀疏地填充有二进制值“1”,并且它们被密集地填充有二进制值“1”。实际上,在bg1 200中的任何扩展行204中,nc,1=26个核心列201中不超过9个具有二进制值“1”。同时,在bg2 300中的任何扩展行304中,nc,2=14个核心列301中不超过5个具有二进制值“1”。
13、通过在基图bg1 200和bg2 300中都填充上二进制值0来完成由扩展列202和302与核心行203和303的交集形成的子矩阵。除了位于从矩阵的左上角到右下角的对角线上的元素之外,由扩展列202和302与扩展行204和304的交集形成的方形子矩阵被大部分填充二进制值“0”,其在基图bg1 200和bg2 300中均采用二进制值“1”。应注意,在两个基图中,一些扩展行204和304与其相邻扩展行中的一个或两个正交。在此,如果两行(或两列)的逻辑“与(and)”是仅包含二进制值“0”的向量,则可以认为它们彼此正交。
14、应注意,根据速率匹配的作用,一些扩展列202和302以及对应的扩展行204和304可以在运行时从基图中删除,然后再用于生成pcm。在此,对应于特定扩展列202和302的扩展行204和304是与其共享二进制值1的一个行。该删除将bg1 200中的扩展列202和行204的数量从ne,1减少到n'e,1,并且将bg2 300中的扩展列302和行304的数量从ne,2减少到n'e,2。因此,对于bg1 200和bg2 300,列数分别变为n'1=nc,1+n'e,1和n'2=nc,2+n'e,2,而分别对于bg1200和bg2 300,行数变为m'1=mc,1+n'e,1和m'2=mc,2+n'e,2。
15、在运行时用于特定ldpc编码和解码过程的pcm是通过选择基图bg1 200和bg2 300中的一个或另一个基图并使用提升因子z提升它来获得的,针对其在3gpp新无线电中支持高达z最大=384的51个值。在此,基图bg1 200和bg2300中的每个二进制元素都被具有z x z维度的子矩阵替换。因此,基图bg1 200和bg2 300中的每一行或列对应于pcm中的一组z行(称为块行)或一组z列(称为块列)。此外,源自bg1 200的pcm包括n'=n'1z列和n'-k=m'1z行,而源自bg2 300的pcm包括n'=n'2z列和n'-k=m'2z行。在bg1 200的情况下,k=22z并且前22个块列对应于数据位x 102。同时,在bg2 300的情况下,k=10z,其中前10个块列对应于数据位102。在3gpp新无线电中,根据一组规则选择k和z的值,这取决于k’的值。
16、基图中具有值“0”的二进制元素被替换为填充有二进制值“0”的z x z子矩阵。相比之下,基图中值为“1”的二进制元素被替换为子矩阵,其中z元素采用二进制值“1”,并且其余z x(z-1)个元素采用二进制值“0”。在扩展块列中,这些z1值二进制元素位于从z x z子矩阵401的左上角到右下角延伸的对角线上。相反,在核心块列中,这些z1值二进制元素根据该对角线的圆形旋转402定位,如图4中所示。更具体地,图4展示了应用示例提升因子z的各种示例性旋转的已知矩阵解释,以便在变量的自然排序和旋转排序之间转换。用于核心块列中每个1值二进制元素的对角线在“0”到“z-1”范围内旋转不同数量的位置,这取决于运行时选择的特定基图和z的值。
17、常规的ldpc解码器实施方式
18、虽然之前已经提出了许多ldpc解码器实施方式,但是本背景讨论集中在行并行分层置信传播实施方式[2]上,如图5所示。图5展示了ldpc解码器的已知行并行分层置信传播实施方式,其中应用了3gpp新无线电ldpc码。通常,这种类型的实施方式可以被设计为在运行时支持任意数量的基图,具有任意维度和支持的提升因子z的集合。然而,为了简单起见,本背景讨论考虑了一种专门设计用于为3gpp新无线电基图和所有对应的提升因子z提供运行时支持的实施方式。[2]500的实施方式包括nc,最大=max(nc,1,nc,2)个核心变量节点(vn)存储器、一个扩展vn存储器502、nc,最大个旋转器505和一个校验节点(cn)处理器,它们都在控制器506的控制下运行。nc,最大个核心vn存储器503中的每一个经由nc,最大个旋转器505中的对应一个连接到cn处理器501的输入-输出(i-o)端口504。同时,扩展vn存储器502直接连接到cn处理器501的i-o端口504。因此,cn处理器501经由对应的旋转器505或直接连接到总共nc,最大+1个vn存储器502和503。vn存储器502和503、旋转器505和cn处理器501可以被设计为采用p个平行度,使得每个连接一次可以传输p数量个llr。因此,不同的存储器配置是已知的。
19、在所考虑的行并行架构中,pcm中的每个nc,1或nc,2核心块列被映射到不同的一个核心vn存储器503,并且n'e,1或n'e,2扩展块列的集合被映射到扩展vn存储器502。在此,扩展vn存储器502包括n'e,1或n'e,2个子存储器,每个子存储器被映射到不同的一个扩展块列。应注意,在图2和图3的基图的每个扩展块列202和302中分别只有单个二进制值“1”。本发明的发明人已经认识到并认识到,扩展vn存储器502中的每个子存储器被同等地映射到对应于容纳此二进制值“1”的基图的行的m'e,1或m'e,2个扩展块行之一。ldpc解码过程通过将来自n’个编码的llr 106的向量的每个连续的z个llr集合加载到对应于pcm中的每个连续块列的vn存储器或子存储器中来初始化。应注意,加载到对应于前两个块列(被称为删余块列)的核心vn存储器503中的llr在3gpp新无线电ldpc码中通常采用0值。同时,对应于k-k’个填充位的llr通常采用较大的正llr值。
20、常规的ldpc解码器实施方式使用多次迭代执行ldpc解码过程,其中每次迭代完成pcm上的一遍处理。每次迭代都包含对pcm的每个块行执行的处理,其中块行在每次迭代中的处理顺序由分层置信传播计划决定。pcm的每个块行的处理由多个ldpc解码函数组成,其中每个函数对块行内的一组p行执行处理。每个ldpc解码函数包括第一子步骤和第二子步骤。在每个子步骤期间执行多个过程,并且这些过程可以分布在多个连续的时钟周期上。
21、更具体地,ldpc解码过程是通过多个步骤完成的。每个步骤处理与pcm的同一块行内的p行相关联的llr,其中这些行通常是连续的。通常,在一组ceil(z/p)连续步骤期间处理块行内的完整行集合,其中每个连续步骤通常按顺序处理连续的p行的集合。更具体地,在其中z不能被p整除的情况下,在floor(z/p)个连续步骤中每个步骤期间处理p行,而在剩余步骤期间处理mod(z,p)行。请注意,“ceil”函数将分数向上取整到具有更大或相等值的最小整数。相比之下,“floor”函数将分数向下取整到具有更小或相等值的最大整数。最后,“mod”函数提供分数的余数部分。
22、此外,块行通常按照调度表规定的顺序进行处理,该调度表可能会在多次迭代中重复处理某些或所有块行。在ldpc解码过程的每个步骤期间,基图的对应行的核心列201和301中的二进制值“1”用于激活图5的相关联的旋转器505、核心vn存储器503和cn处理器i-o端口504。
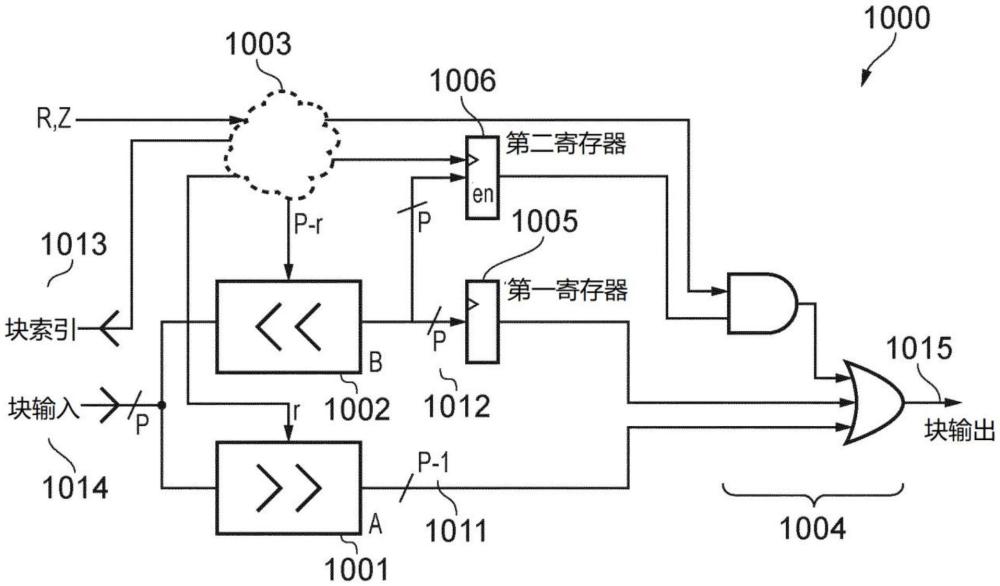
23、在ldpc解码过程的每个步骤的第一子步骤期间,在控制器(如图5中的控制器506)的指导下读取每个激活的核心vn存储器(如图5中的核心vn存储器503),以便提供完成pcm的p行的处理所需的p个llr。此外,激活的旋转器中的每一个(例如图5中的激活的旋转器505)配置成将这些p个llr旋转到完成该处理所需的顺序,该处理是在控制器的指导下并根据用于将基图200和300转换成pcm的的旋转来执行的。每个激活的旋转器将对应的一组p个llr提供给对应的i-o端口(比如图5中的cn处理器501的i-o端口504)的输入。本发明的发明人已经认识到并意识到需要解决为使用ldpc编码和/或解码的实际通信装置实现有效的ldpc旋转器电路的问题。
24、此外,在ldpc解码过程的每个步骤中对应于基图中的扩展行204和304的第一子步骤期间,cn处理器501还提供有从扩展vn存储器(比如图5中的扩展vn存储器502)读取的一组p个llr。更具体地,这些llr由映射到该扩展行204和304的扩展vn存储器中的特定子存储器提供。相比之下,扩展vn存储器在对应于基图中的核心行203和303的ldpc解码过程的每个步骤的第一子步骤期间被停用,结果它不向cn处理器提供任何llr。
25、以上述方式,在ldpc解码过程的每个步骤的第一子步骤中,到cn处理器的i-o端口的输入的连接的激活子集各自为其提供一组p个llr。响应于此,cn处理器针对pcm的p个相关联行并行执行p组计算。这可以使用各种算法[3]来实现,包括例如和积、最小和、归一化最小和、偏移最小和或调整最小和。cn处理器通常采用内部存储器来协助这些计算,使用在处理pcm的p个相关联行的先前迭代期间所获得的结果。这些结果通常会被新结果覆盖,新结果可以用于协助下一次迭代处理pcm的p个相关联行。在ldpc解码过程的每个步骤的第二子步骤中并且在cn处理器执行的所有计算完成之后,它可以使用来自其i-o端口的输出为其每个连接提供一组p个llr,所述连接在ldpc解码过程的当前步骤中被激活。
26、例如,在针对pcm中的一组p行执行的ldpc解码过程的第一子步骤中,cn处理器可以使用最小和算法来组合由输入提供给其a个激活的i-o端口中的每一个的p个llr。在此,我们可以使用符号ai,p表示输入llr,其中i在1到a的范围内并且指示llr被设置在a个激活的i-o端口中的哪一个上,并且p在1到p的范围内并且指示这个llr是被设置在该i-o端口上的p个llr中的哪一个。在第一计算中,cn处理器可以执行对应于每个输入llr ai,p的计算bi,p=ai,p-mi,p,其中mi,p是对应的内部存储值,其在ldpc解码过程开始时被初始化为“0”,并且在pcm中的p个行的处理的每次迭代中更新。在此之后,针对p的每个值识别绝对值|bi,p|的第一和第二最小值,并且索引i的对应值分别称为最小1和最小2。此外,针对p的每个值识别符号sign(bi,p)的乘积并将其称为signp,其中如果x不小于“0”,sign(x)为“+1”,否则为“-1”。
27、在第二子步骤中,cn处理器可以执行计算m最小1,p=sign(b最小1,p)x signp x|b最小2,p|,对应于输入llr ai,p,对于p的每个值,具有等于最小1的索引i。同时,计算mi,p=sign(bi,p)x signp x|b最小1,p|对应于每个p值的所有其他输入llr执行。在此,mi,p的值被写入i和p的每个组合的内部存储值中,使得它可以在p个行的处理的下一次迭代期间使用,如上所述。最后,对应于输入llr ai,p,cn处理器可以执行计算di,p=bi,p+mi,p,以便为在a个激活的i-o端口中的每一个上作为输出提供的p个llr中的每一个获得输出llr di,p。
28、在此之后,第二子步骤,在ldpc解码过程的每个步骤中,继续每个被激活的旋转器配置成将其提供的一组p个llr旋转成适用于存储在对应的激活的核心vn存储器中的顺序。同样,将在下面的章节中描述传统旋转器电路的功能。本发明的发明人已经认识到并理解了下面描述的另一个问题,可以通过本发明来解决该问题。此外,在ldpc解码过程的每个步骤的第二子步骤中,cn处理器还可以计算与pcm的p个相关联行相对应的校正子位。此外,在对应于扩展行(例如图2和图3的基图bg1 200和bg2 300中的204和304)的ldpc解码过程的每个步骤的第二子步骤期间,cn处理器提供给扩展vn存储器的p个llr的集合的可以写入到其映射到该扩展行的子存储器之一。
29、在ldpc解码过程内的解码迭代完成之后,可以通过连接最近存储在vn存储器502和503中的z个llr来获得n’个解码llr的向量。然后可以考虑前k个解码llr的符号来获得k个解码位107的向量,其中正llr可以被转换为二进制值“0”,而负llr可以被转换为二进制值“1”。
30、总之,图5示出了ldpc解码器的行并行设计。这里,cn处理器501在每个步骤中接受来自多个列存储器503的输入llr。这使得在同一步骤中进行对这些列中的每一个的处理,从而实现了高吞吐量。在类似3gpp的准循环ldpc码中,基图指示不同的循环旋转值应当应用于从每个块列ram读取的llr。这导致cn处理器501通过旋转器电路505连接到每个列ram,每个可以以不同的旋转值操作。为了实现高吞吐量,cn处理器501可以在块行的z行内并行操作p行。这意味着cn处理器501在每个步骤中需要来自每个块列的p个llr。因此,ram的输出以及旋转器的输入和输出将必须在每个步骤中传送p个llr。对于ram,这将导致每个地址包含p个llr。旋转器还必须在p个llr上运行,同时面临的额外挑战是旋转值可能与p不对齐。此外,z也可能与p不对齐。应注意,在不同块行的处理期间,将读取列ram。每个块行可以具有不同的旋转值。这防止了对于给定的旋转以特定的方式排列每个列ram中的元素,当在运行时对不同的块行进行操作时,旋转器需要应用不同的旋转。同样,本发明的发明人已经认识到并意识到另一个问题,即使用ldpc编码或解码的实际通信装置实现有效的ldpc旋转器电路的问题,可以通过本发明来解决这个问题。
技术实现思路
1、本发明提供了用于ldpc旋转器的电路和在ldpc编码器或解码器中使用并行处理进行ldpc旋转的方法,例如其减少了操作次数。具体地,本发明的示例详述了硬件部件与算法特征之间的有效映射。在从属权利要求中阐述了本发明的具体示例性实施例。参考下文描述的示例性实施例,本发明的这些和其他方面将变得显而易见并得到阐述。
2、在本发明的第一方面,一种通信装置包括:低密度奇偶校验ldpc旋转器电路,其具有输入端和输出端,其中ldpc旋转器电路配置成具有至少为2的并行度p,并且配置成执行旋转函数,该旋转函数包括将包括第一数量z个数据值的数据序列旋转第二数量r个位置的一系列操作,其中在一系列操作的第一子集期间,通过输入端接受一系列ceil(z/p)个输入块,每个输入块包括p个输入值,并且其中在一系列操作的第二子集期间,通过输出端提供一系列ceil(z/p)个输出块,每个输出块包括p个输出值,其中在第一操作子集完成之前开始第二操作子集;其中ldpc旋转器电路包括控制器或可操作地耦合到控制器,控制器布置成控制由ldpc旋转器电路执行的旋转函数。ldpc旋转器电路包括:第一组一个或多个寄存器,其被写入一个或多个寄存值,一个或多个寄存值是从一个或多个输入值中导出的,一个或多个输入值是在一个或多个先前操作期间由输入端接受的,并且第一组一个或多个寄存器可操作地耦合到控制器;第二组一个或多个寄存器,其可操作地耦合到控制器;至少一个移位电路,其可操作地耦合到控制器,配置成接收可操作地耦合到p个输入值的移位输入值,并且应用左移和右移以便提供移位输出值;以及至少一个组合电路,其可操作地耦合到控制器,并且可操作地耦合到移位输出值、第一组一个或多个寄存器、第二组一个或多个寄存器中的至少一个;并且配置成向输出端提供p个输出值。数量为floor(z/p)的一系列ceil(z/p)个输入块包括由数量为p的z数据值提供的输入值,并且该系列ceil(z/p)个输入块的一个输入块是填充输入块,其包括由z个数据值中的数值mod(z,p)和以及当z不是p的倍数时填充值中的数值p-mod(z,p)提供的输入值。第二组一个或多个寄存器在控制器的指导下被写入一个或多个寄存值,一个或多个寄存值是从一个或多个输入值中导出的,一个或多个输入值是在一系列操作的第二子集开始之前由输入端接受的,并且其中在输入端接受填充输入块之前没有重写一个或多个寄存值,并且输出块中的至少一个输出块中的p个输出值中的至少一个是第二组一个或多个寄存器中的至少一个寄存值的函数。以这种方式,减缓了停滞旋转器电路的需要,从而改善了通信装置的延迟问题、吞吐量和效率。以这种方式,旋转器电路可以基于简单的移位和组合电路有效地生成输出块,提高了通信装置的效率。
3、在可选的示例中,并行度p对于由ldpc旋转电路执行的所有旋转函数是共同的,并且第一数量z个数据值和第二数量r个位置在旋转函数之间变化。以这种方式,通信装置在z和r参数上提供了运行时间灵活性,这使得在ldpc码的标准化应用中在块长度、编码率和基图选择上具有所需的运行时间灵活性。
4、在可选示例中,一系列操作至少包括ceil(z/p)+2次操作,其中一系列操作的第一子集至少包括ceil(z/p)次操作,并且一系列操作的第二子集至少包括ceil(z/p)次操作。以这种方式,旋转器电路的延迟很小,这改善了通信装置的延迟问题、吞吐量和效率。
5、在可选示例中,第一组一个或多个寄存器被写入一个或多个寄存值,寄存值是在ldpc旋转器电路的至少一个操作期间从一个或多个输入值导出的,并且输出块中的至少一个输出块中的p个输出值中的至少一个是第一组一个或多个寄存器中的至少一个寄存值的函数。以这种方式,第一组寄存器可以有效地存储当前输出块不需要但下一个输出块需要的输入值。
6、在可选示例中,填充输入块配置成采用以下方式之一:
7、p-mod(z,p)个填充值占据填充输入块中的最后p-mod(z,p)个位置,并且其中p-mod(z,p)个填充值被设置为零;
8、p-mod(z,p)个填充值占据填充输入块中的第一p-mod(z,p)个位置,并且其中p-mod(z,p)个填充值被设置为零;
9、p-mod(z,p)个填充值占据填充输入块中的最后p-mod(z,p)个位置,并且其中p-mod(z,p)个填充值被设置为等于来自输入块的第一p-mod(z,p)输入值,该输入块在一系列ceil(z/p)个输入块中紧接在填充输入块之后;
10、p-mod(z,p)个填充值占据填充输入块中的最后p-mod(z,p)个位置,并且填充输入块是一系列ceil(z/p)个输入块中的最后输入块,并且其中p-mod(z,p)个填充值被设置为等于来自一系列ceil(z/p)个输入块中的第一输入块的第一p-mod(z,p)输入值;
11、p-mod(z,p)个填充值占据填充输入块中的第一p-mod(z,p)个位置,并且其中
12、p-mod(z,p)个填充值被设置为等于来自输入块的最后p-mod(z,p)输入值,该输入块在一系列ceil(z/p)个输入块中紧接在填充输入块之前;
13、p-mod(z,p)个填充值占据填充输入块中的第一p-mod(z,p)个位置,并且填充输入块是一系列ceil(z/p)个输入块中的第一输入块,并且其中p-mod(z,p)个填充值被设置为等于来自一系列ceil(z/p)个输入块中的最后输入块的最后p-mod(z,p)输入值。
14、以这种方式,旋转器电路可以减轻在处理填充值时停滞旋转器电路的需要,从而改善通信装置的延迟问题、吞吐量和效率。
15、在可选示例中,一系列ceil(z/p)个输入块中的第一输入块包含第mod(r,z)+1个数据值,在第一操作子集中的第一操作期间将该数据值提供给ldpc旋转器电路的输入端,并且其中在第一操作子集中的每个连续操作期间将每个连续输入块提供给ldpc旋转器电路的输入端,其中在第一操作子集中的操作期间,将包含数据序列中第一个数据值的输入块提供给ldpc旋转器电路的输入端,该操作是在将包含数据序列中最后数据值的输入块提供给ldpc旋转器电路的输入端的操作之后。以这种方式,旋转器电路可以减轻在处理填充值时停滞旋转器电路的需要,从而改善通信装置的延迟问题、吞吐量和效率。
16、在可选示例中,至少一个组合电路包括一组或门,并且其中由至少一个移位电路应用的左移和右移使用零填充。以这种方式,组合电路仅包括简单的逻辑门,从而提高了通信装置的效率。
17、在可选示例中,第二组一个或多个寄存器还可操作地耦合到至少一个移位电路,并且布置成向至少一个组合电路提供从以下之一导出的一个或多个移位输出值:填充输入块;在一系列ceil(z/p)个输入块中紧接填充输入块之后的输入块;当填充输入块是一系列ceil(z/p)个输入块中的最后输入块时,该系列ceil(z/p)个输入块中的第一输入块。以这种方式,旋转器电路可以减轻在处理填充值时停滞旋转器电路的需要,从而改善通信装置的延迟问题、吞吐量和效率。
18、在可选示例中,一个或多个屏蔽电路布置成将第二组一个或多个寄存器和至少一个移位电路连接到至少一个组合电路,其中一个或多个屏蔽电路配置成确定组合输入值是从移位输出值导出还是从虚拟值导出。以这种方式,当不需要时,可以有效地禁止向组合电路提供移位输出值。
19、在可选示例中,第一组一个或多个寄存器包括一个寄存器,第二组一个或多个寄存器包括一个寄存器,输入值作为移位输入值被提供给至少一个移位电路,并且其中第一组一个或多个寄存器和第二组一个或多个寄存器的寄存值通过移位输出值来提供,并且其中组合输入值由以下各项提供:经由一个或多个屏蔽电路的第二组一个或多个寄存器的寄存值;和第一组一个或多个寄存器的寄存值;和至少一个移位电路的移位输出值。以这种方式,可以有效地完成旋转函数,同时减轻在处理填充值时停滞旋转器电路的需要,从而改善通信装置的延迟问题、吞吐量和效率。
20、在可选示例中,第一组一个或多个寄存器包括两个寄存器,其中第一组一个或多个寄存器中的第二寄存器的输入端可操作地耦合到第一组一个或多个寄存器中的第一寄存器的输出端,以形成移位寄存器;其中第二组一个或多个寄存器包括两个寄存器,它们被写入一系列ceil(z/p)个输入块中的包含第mod(r,z)+1个数据值的输入块,并且被写入:紧接一系列ceil(z/p)个输入块中的包含第mod(r,z)+1个数据值的输入块之后的一系列ceil(z/p)个输入块中的输入块;或是当一系列ceil(z/p)个输入块中的包含第mod(r,z)+1个数据值的输入块是一系列ceil(z/p)个输入块中的最后输入块时,一系列ceil(z/p)个输入块中的第一输入块;并且其中第二组一个或多个寄存器配置成在第二操作子集结束之前不被重写。以这种方式,可以有效地完成旋转函数,同时减轻在处理填充值时停滞旋转器电路的需要,并且同时使得能够完成两个连续的旋转函数而不需要任何流水线预热和收尾,从而改善通信装置的延迟问题、吞吐量和效率。
21、在可选示例中,至少一个复用电路配置成复用第一和第二组寄存器的寄存值,并为至少一个移位电路提供移位输入值。以这种方式,可以有效地提供组合电路所需的输入。
22、在可选示例中,由ldpc旋转器电路执行的旋转函数包括与第二旋转函数流水线化的第一旋转函数,其中第二旋转函数的第一操作子集中的第一操作在第一旋转函数的第二操作子集中的最后操作之前,并且其中第二旋转函数的第二操作子集中的第一操作紧接在第一旋转函数的第二操作子集中的最后操作之后。以这种方式,需要完成两个连续的旋转函数,而不需要任何流水线预热和收尾,从而改善通信装置的延迟问题、吞吐量和效率。
23、在可选示例中,当执行其中z小于p的旋转函数时,在单次操作中执行旋转函数。以这种方式,可以使用最少数量的操作来处理所描述的特殊情况,从而改善通信装置的延迟问题、吞吐量和效率。
24、在可选示例中,当执行其中z是p的倍数的旋转函数时,该系列操作至少包括ceil(z/p)+1次操作。以这种方式,可以使用最少数量的操作来处理所描述的特殊情况,从而改善通信装置的延迟问题、吞吐量和效率。
25、在本发明的第二方面,描述了一种用于在包括低密度奇偶校验ldpc旋转器电路的ldpc编码器或解码器中计算ldpc旋转的方法,该旋转器电路具有:输入端;输出端;第一组一个或多个寄存器,这些寄存器被写入一个或多个寄存值,这些寄存值是从在一个或多个先前操作期间由输入端接受的一个或多个输入值导出的,该旋转器电路可操作地耦合到控制器;第二组一个或多个寄存器,其可操作地耦合到控制器;以及至少为2的并行度p。该方法包括:由ldpc旋转器电路配置旋转函数,该旋转函数包括将包括第一数量z个数据值的数据序列旋转第二数量r个位置的一系列操作,在该系列操作的第一子集期间通过输入端接受一系列ceil(z/p)个输入块,每个输入块包括p个输入值,以及接收可操作地耦合到p个输入值的移位输入值,并通过至少一个移位电路应用左移和右移以便提供移位输出值;在一系列操作的第二子集期间通过输出端提供一系列ceil(z/p)个输出块,每个输出块包括p个输出值,由可操作地耦合到控制器的至少一个组合电路输出,并且布置成可操作地组合源自以下至少一个的输出:控制器、移位输出值、第一组一个或多个寄存器和第二组一个或多个寄存器,并且向输出端提供p个输出值;其中第二操作子集在第一操作子集完成之前开始。ldpc旋转器电路包括控制器或可操作地耦合到控制器,该控制器布置成控制由ldpc旋转器电路执行的旋转函数。数量为floor(z/p)的一系列ceil(z/p)个输入块包括由数量为p的z数据值提供的输入值,并且该系列ceil(z/p)个输入块的一个输入块是填充输入块,其包括由z个数据值中的数值mod(z,p)和以及当z不是p的倍数时填充值中的数值p-mod(z,p)提供的输入值。该方法还包括:在一系列操作的第二子集开始之前,通过输入端接受一个或多个输入值,从一个或多个输入值导出一个或多个寄存值,以及在控制器的指导下用一个或多个导出的寄存值写入第二组一个或多个寄存器。在输入端接受填充输入块之前,导出的一个或多个寄存值不被重写,并且输出块中的至少一个输出块中的p个输出值中的至少一个是第二组一个或多个寄存器中的至少一个寄存值的函数。以这种方式,减缓了停滞旋转器电路的需要,从而改善了通信装置的延迟问题、吞吐量和效率。
本文地址:https://www.jishuxx.com/zhuanli/20240905/289613.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。