一种基于结构注意力的代码摘要生成方法及装置
- 国知局
- 2024-09-11 14:17:07
本发明涉及代码摘要,更具体的说是涉及一种基于结构注意力的代码摘要生成方法及装置。
背景技术:
1、由于源代码及其摘要的格式是一对序列,因此这项任务最初被视为序列到序列(seq2seq)任务,并配备了mnt(机器翻译)技术。早期,研究人员将源代码视为词元序列,并在此基础上引入了相关方法。因为认为程序序列中可能包含一些可以像自然语言一样学习的模式。于是iyer等人提出了名为code-nn的方法,利用注意力机制和长短时记忆(lstm)来总结c#源代码。而allamanis等人则尝试将卷积神经网络(cnn)与注意力机制相结合,这种方法虽然开启了深度学习技术在代码总结领域的应用,但源代码序列中仍有更多信息有待发现。另一个研究小组hu等人注意到,源代码序列中的api对开发人员的理解很有意义。因此,他们设计了一个tl-cosum框架,将学习到的api知识转移到代码摘要任务中。zheng等人提出了一种利用关键语句信息的新型关注机制。上述的这些方法均采用的是基于递归神经网络的模型,就很难捕捉到长距离的依赖关系。而为了解决这个问题,ahmad等人利用transformer模型来实现这一任务。由于上述所有的研究均缺乏了对非序列信息的建模,因此在模型中加入了相对位置编码。
2、许多研究人员基于ahmad等人注意到的结构信息的稀缺性开始尝试从抽象语法树(ast)中学习信息,ast是一种树状数据结构,用于表示编程语言中代码的语法结构。hu等人探索了从ast中捕获语法信息的方法,并设计了一种基于结构的遍历方法(sbt),以保护结构在序列化时不会因添加括号而受到破坏。而alon等人则将ast表示为从终端节点到另一个终端节点或从根节点到终端节点的路径集,其性能优于iyer等人和allamanis等人的研究成果。这也说明了语法信息在模型解释程序时的重要性。然而,hu等人通过添加特殊字符来线性化ast以保持结构的方法绝对会延长输入长度,而没有其他方法让模型更好地学习这些输入。wu等人指出,由于上述原因,sbt在某些情况下可能无法提高性能。因此,wu等人设计了一种结构诱导transformer(sit),补充了更多关于数据流和控制流的关系,并将其转换为掩码矩阵。该方法是将ast预排序遍历序列作为输入,并使用该掩码诱导transformer关注与模型数据流、控制流和语法相关的词元。tang等人和gong等人以类似的方式实现了这种思想。前者侧重于祖先-后代和同胞关系,后者则引入了一个矩阵来记录ast节点对的相对距离。choi等人考虑了其他ast对相似代码片段序列和相应摘要的预排序,并在解码阶段对它们进行了融合。
3、因此,其他研究人员探索了融合这两种表示或其他更多不同粒度表示的方法。wan等人通过在早期将lstm的注意力分数串联到强化学习框架中,将两种表示结合起来。但有两点需要改进:一个是学习ast的方法,这一直是这项任务的一大挑战;另一个是将两种表征融合在一起的方法。而为了克服这些挑战,shi等人将ast按照层级分成许多子树,并通过rnn对子树的每个节点进行编码。编码后的ast特征和源代码词元由解码器中的交叉注意模块逐一学习。shi等人的方法似乎能在解码时保持层的特征并将两种不同的表征联系起来。gao等人创建了词元(子词元关系)、语句和数据流层次关系矩阵,并在transformer中计算时将其应用于不同的注意头。son等人认为从词元中提取结构特征具有挑战性,建议从程序的语句级表示--程序依赖图(pdg)中学习结构特征。于是son等采用了一种池化技术,将同一语句中的节点嵌入到一个特征中,并将这种方法加入到其他研究者的工作中,如wu等人的sit,在一定程度上改善了结果。这些技术可以检查不同ast结构层次和部分的语义,重点是处理节点集,并与ast序列中的信息和源代码词元建立了一定程度的关联。由于ast具有图的性质,一些研究人员采用图神经网络来学习ast。yang等人提出的mmtrans同时应用了图卷积网络(gcn)和变换器,通过两种风格的神经网络学习不同角度的ast;zhang等人介绍了一种结合图形注意网络(gat)和变换器的简单方法;zhang等人直接利用gat来编码未经特殊处理的ast序列,并利用transformer来捕捉源代码序列。
4、总结上述情况,在生成令人满意的代码摘要方面存在三大挑战:(1)目前使用ast的预排序遍历序列的工作通常会遗漏每个节点的类型,从而会导致学习的特征不充分;(2)许多研究人员通过添加数据流、控制流或其他边来增强ast,并设计矩阵来引导transformer学习这些关系;但却没有考虑到这些边及其周围上下文对整个程序解释的重要性;(3)如何捕捉不同粒度和层次的程序特征,并以更有效的方式将它们混合起来。
技术实现思路
1、有鉴于此,本发明的目的是提供一种基于结构注意力的代码摘要生成方法及装置,以解决上述现有技术存在的问题。
2、为实现上述目的,本发明提供如下技术方案:
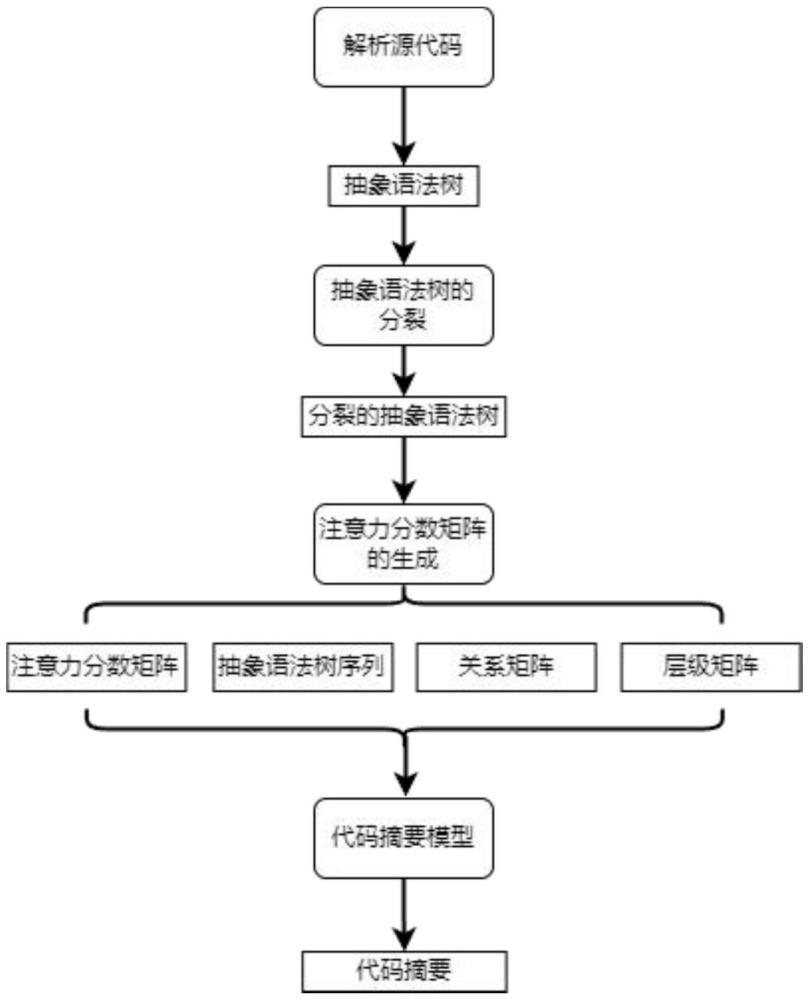
3、一种基于结构注意力的代码摘要生成方法,包括以下步骤:
4、s1、将源代码的代码片段解析为原始抽象语法树,并将原始抽象语法树的节点分裂为类型节点和值节点,得到分裂后的抽象语法树;
5、s2、基于分裂后的抽象语法树,为抽象语法树的终端值节点、类型节点和值节点分别构建连接边,得到原始边;
6、基于抽象语法树中的控制流和数据流,构建控制流边、数据流边,设计原始边的邻接矩阵;
7、为抽象语法树中的叶子节点构建连接边;
8、s3、对原始边的邻接矩阵与控制流以及原始边的邻接矩阵与数据流分别进行联合运算,初步得到origin-control矩阵和origin-dataflow矩阵,并通过分别计算origin-control矩阵和origin-dataflow矩阵的二次幂,最终得到矩阵中每个元素代表从一个节点到另一个节点路径数为2的两个基于结构的注意力分数矩阵;
9、基于原始边、控制流边和数据流边构建边关系矩阵;
10、对抽象语法树中的所有节点进行前序遍历,并为抽象语法树中的所有节点创建one-hot矩阵;
11、s4、利用基于结构的注意力得分矩阵、前序遍历的序列、边的关系矩阵和层级矩阵,构建基于结构注意力的代码摘要模型;所述代码摘要模型包括graphsage编码器、transformer编码器和融合解码器;
12、基于graphsage编码器学习前序遍历的抽象语法树序列中局部视角的特征;
13、基于transformer编码器将代码片段中每个词元的嵌入添加到抽象语法树序列中相应节点的嵌入后,再与层级矩阵拼接;
14、在融合解码器中部署的双交叉注意机制,并基于融合解码器分别拾取graphsage编码器和transformer编码器所学习到前序遍历的抽象语法树序列的不同视角的特征;
15、s5,利用构建的基于结构注意力的代码摘要模型,生成代码摘要。
16、进一步地,所述步骤s2中所述根据类型节点得到控制流边,具体为:
17、当类型节点为blockstatement时,将其子节点的类型节点连接在一起;
18、当类型节点为ifstatement、forstatement以及whilestatement中的其中一个时,则将其连接到下一个同级节点,并将其子节点的类型节点连接在一起。
19、进一步地,所述步骤s2中所述根据值节点得到数据流边,具体为:
20、将所有值节点从被定义的位置连接到被引用的位置连接。
21、进一步地,所述步骤s4中所述graphsage编码器,包括:变换器和聚合器;
22、所述变换器用于根据结构的注意力分数矩阵进行调整;
23、所述聚合器用于捕捉抽象语法树序列中每个节点相对局部的特征。
24、进一步地,所述步骤s4中基于graphsage编码器学习前序遍历的抽象语法树序列中局部视角的特征,具体为:
25、为每一层节点引入belu非线性,并使用残差连接,其中:
26、第k层中nodei的处理可以表述为:
27、
28、其中,表示第i个节点在第k层的特征;表示第i个节点在第k-1层的特征;w1和w2表示可学习的权重矩阵;n(i)是第i节点的邻居集合;aggr是聚合函数,用于聚合第i节点的邻居传递信息;
29、将所有特征串联起来,送入relu激活函数,如下式;
30、
31、其中:为所有整个graphsage在第k层的总输出;
32、采用残差连接和层归一化策略,生成局部视角的特征,具体为:
33、
34、进一步地,所述基于transformer编码器将代码片段中每个词元的嵌入添加到ast序列中相应节点的嵌入后,再与层级矩阵拼接,并通过以下步骤表示:
35、embast=emb(s1,s2,...,sn)
36、embcode=emb(c1,c2,...,cm)
37、
38、otherwise;
39、h=[embfusion,mlevel]
40、其中:embast表示ast节点序列的嵌入向量;embcode表示源代码序列的嵌入向量;embfusion表示上述两种嵌入向量的融合的嵌入向量;h表示结合了层级信息的最终嵌入向量;
41、si和ci分别表示抽象语法树序列和源代码序列中的第i个词元;emb(·)是嵌入层,mlevel是层级矩阵。
42、本发明还提供了一种基于结构注意力的代码摘要的生成装置,所述装置包括:
43、分裂处理模块,将源代码的代码片段解析为原始抽象语法树,并将原始抽象语法树的节点分裂为类型节点和值节点,得到分裂后的抽象语法树;
44、s2、基于分裂后的抽象语法树,为抽象语法树中的终端值节点、类型节点和值节点分别构建连接边,得到原始边;
45、基于抽象语法树中的控制流和数据流,构建控制流边、数据流边,设计原始边的邻接矩阵;
46、为抽象语法树中的叶子节点构建连接边;
47、结构注意力分数矩阵的生成模块,对原始边的邻接矩阵与控制流以及原始边的邻接矩阵与数据流分别进行联合运算,初步得到origin-control矩阵和origin-dataflow矩阵,并通过分别计算origin-control矩阵和origin-dataflow矩阵的二次幂,最终得到矩阵中每个元素代表从一个节点到另一个节点路径数为2的两个基于结构的注意力分数矩阵;
48、模型构建模块,利用基于结构的注意力得分矩阵、前序遍历的序列、边的关系矩阵和层级矩阵,构建基于结构注意力的代码摘要模型:所述代码摘要模型包括graphsage编码器、transformer编码器和融合解码器;
49、基于graphsage编码器学习前序遍历的抽象语法树序列中局部视角的特征;
50、基于transformer编码器将代码片段中每个词元的嵌入添加到抽象语法树序列的嵌入后,再与层级矩阵拼接;
51、在融合解码器中部署的双交叉注意机制,并分别拾取graphsage编码器和transformer编码器所捕捉到前序遍历的抽象语法树序列的不同视角的特征;
52、模型输出模块:利用构建的基于结构注意力的代码摘要模型,生成代码摘要。
53、根据本发明提供的具体实施例,本发明公开了以下技术效果:
54、1、本发明通过利用分析源代码的抽象语法树,根据每个节点的值与类型字段,分裂每个节点,并重构出新的抽象语法树split ast;然后在重构出新的抽象语法树上探索数据流、控制流及其上下文等信息,构建相应的注意力分数矩阵,再搭配graphsage编码器与transformer编码器,提取多粒度多表示的特征,以增强代码摘要生成任务的效果。针对传统的代码摘要生成方法,本发明做了以下改进:
55、(1)之前经常使用源代码ast来表示代码的研究者,通常在遍历时仅仅访问节点的值,然而,却忽视了节点的类型是显式语法信息;而在本发明中,同时关注了ast节点的类型和值,并在任务中将其拆分为单独的节点,重构出了明确包含语法信息的ast新表示,这样显示的结构表示能让模型更容易捕获源代码的语法结构特征;
56、(2)现有方法通常专注于所添加的关系本身,却忽略了这些边周围的上下文节点也可能会增强模型对源代码的理解;并且也忽略了所涉及的关系的重要程度。而在本发明中,则通过邻接矩阵的二次幂,并将这些矩阵视为注意力得分矩阵,而不是掩码矩阵,从而让基于结构注意力的代码摘要模型关注到了所定义的有关上下文节点的边,而不仅局限于原始边、数据流边和控制流边本身。
57、(3)现有的使用混合表示和粒度来生成代码摘要的工作需要一种更好的方式来捕捉和融合它们的不同特征;在本发明中,在基于结构注意力的代码摘要模型中包含两个不同的基础模型graphsage编码器和transformer编码器,前者能以更高的泛化程度学习ast,后者能以更灵活的方式捕捉全局和综合特征,二者的结合能让模型能更加全面地学习到源代码的特征,从而更好的进行代码摘要的生成。
本文地址:https://www.jishuxx.com/zhuanli/20240911/290008.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。