利用大语言模型的自然语言匿名化方法、装置及存储介质与流程
- 国知局
- 2024-09-14 14:42:29
本申请涉及人工智能,尤其涉及一种利用大语言模型的自然语言匿名化方法、装置及存储介质。
背景技术:
1、大模型这类基于自然语言的模型,均建立在大量的原始文本数据集训练之上。原始数据中不可避免会包含敏感信息,因此大语言模型的防护会被别有用心的人绕过,从而获取训练集中的敏感数据。为确保安全性,有必要针对原始数据进行脱敏,再进行训练和建模。然而,自然语言文本具有含义模糊抽象、句式灵活多变等特点,如何有效地从中删除敏感信息,同时保留原句句式和语义以供后续利用,成为了一大挑战。
2、例如,有如下句子:“昨天我湖边散步时,在苏堤偶遇了邻居小李,他也刚出家门”,那么就可以推出这个人的住址信息,也就是杭州市西湖区,但使用传统程序无法自动完成这类推理,自然也无法进行针对性的脱敏。
3、数据匿名化是一种保护隐私安全的技术,是数据安全的重要发展方向。而文本数据匿名化主要针对非结构化数据,涉及到自然语言处理、信息抽取等技术,难度较大。
4、传统数据匿名化路线主要包括泛化和差分,其原理如下:
5、对数据进行泛化处理,与其他数据元素相较而言,某些数据元素更容易用来与特定的个人关联到一起。为保护这些特定个人的隐私,会采用泛化技术来移除部分相关数据,或者使用常见值取而代之。例如,可能会采用泛化技术以相同的数字序列来取代所有的区号或电话号码条目。通过泛化处理,我们可以实现 k 匿名效果。例如,假设有一个数据集,对应的 k 是 50,属性是邮政编码。如果我们查看该数据集中任何人的相关数据,一定会发现另外 49 个人也有着相同的邮政编码。因此,仅根据邮政编码,我们无法辨识该数据集中任何人的身份。
6、如果某数据集中的所有人都具有相同的敏感属性值,那么只要知道这些人属于相关数据集,就可能会知道这项敏感信息。为降低这种风险,我们可能会采用 l 多样性。l 多样性也是业界标准术语,用于表示敏感值中的多样性程度。例如,假设有一群人全都在同一时间搜索了同一敏感健康主题。如果我们查看该数据集,将无法知道到底是谁搜索了这个主题(得益于 k 匿名)。不过,由于该数据集中的所有人都具有相同的敏感属性(即查询的主题),因此可能依然会存在泄露隐私的风险。l 多样性意味着匿名化处理后的数据集将不会只包含流感查询,而是会同时包含流感查询以及其他查询,以便进一步保护用户隐私。
7、向数据中添加噪声,差别隐私是一种向数据中添加数学噪声的技术。如果使用该技术,就无法确定任何个人是否属于某数据集,因为给定算法的输出结果看起来基本都一样,无论是包含还是未包含相应个人的信息都是如此。例如,假设正在衡量某地理区域的整体流感查询趋势。为实现差别隐私,可向该数据集中添加噪声。这意味着可增加或减少某个社区中搜索流感相关内容的人数,但这样做并不会影响在较大的地理区域范围内衡量这一趋势。针对文本信息,可以使用词嵌入向量,对该向量加差分隐私噪声来形成新的词汇。不过,向数据中添加噪声可能会导致数据变得不那么实用。
技术实现思路
1、本申请实施例提供一种利用大语言模型的自然语言匿名化方法、装置及存储介质,提供一种对文本数据完成脱敏的有效方法,最大程度上保留信息和语义。
2、本申请实施例提供一种利用大语言模型的自然语言匿名化方法,包括:
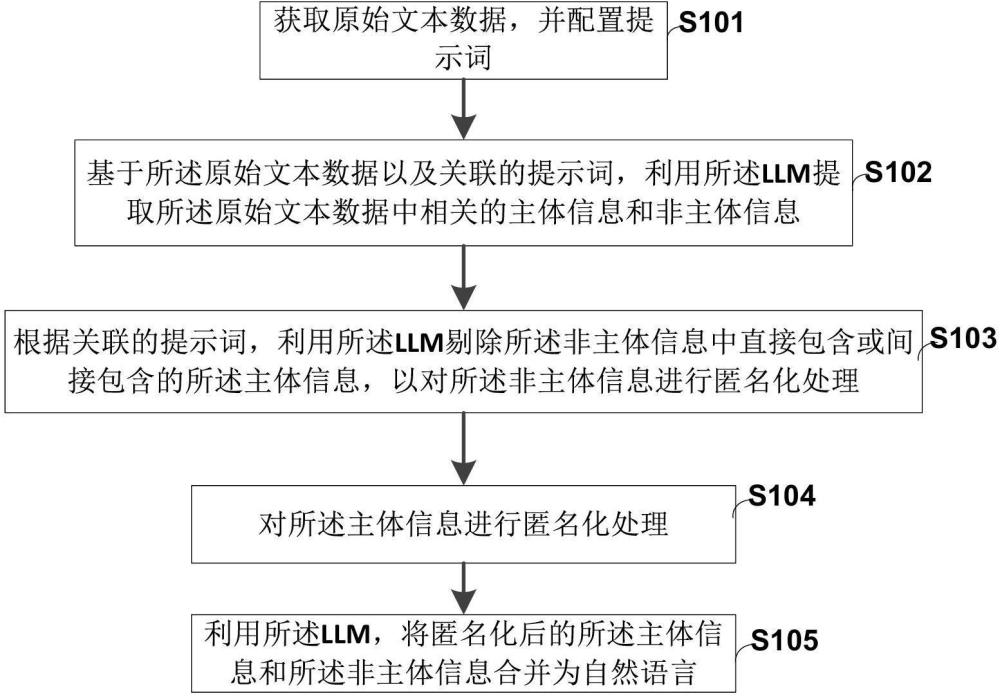
3、获取原始文本数据,并配置提示词,其中所配置的提示词与指示大语言模型llm执行的任务相关联;
4、基于所述原始文本数据以及关联的所述提示词,利用所述llm提取所述原始文本数据中相关的主体信息和非主体信息;
5、根据关联的所述提示词,利用所述llm剔除所述非主体信息中直接包含或间接包含的所述主体信息,以对所述非主体信息进行匿名化处理;以及,
6、对所述主体信息进行匿名化处理;
7、基于匿名化后的所述主体信息和所述非主体信息,利用所述llm,将匿名化后的所述主体信息和所述非主体信息合并为自然语言。
8、可选的,基于所述原始文本数据以及关联的所述提示词,利用所述llm提取所述原始文本数据中相关的主体信息和非主体信息包括:
9、基于所述原始文本数据以及关联的所述提示词,指示所述llm,按照设定的格式,提取所述原始文本数据中相关的主体信息和非主体信息。
10、可选的,在对所述主体信息以及所述非主体信息进行匿名化之前还包括:
11、根据llm确定的非主体信息,再次根据关联的所述提示词,利用所述llm进行推理,以对所述主体信息进行补充。
12、可选的,对所述主体信息进行匿名化处理包括:
13、对所述主体信息进行脱敏处理;以及,
14、对脱敏后的所述主体信息,利用匿名化算法进行匿名化处理。
15、可选的,对所述主体信息进行匿名化处理还包括:
16、为所述主体信息中的各项属性设置离群值,以将属性限定在设定范围,消除异常属性值。
17、本申请实施例还提出一种利用大语言模型的自然语言匿名化装置,包括处理器,被配置为:
18、获取原始文本数据,并配置提示词,其中所配置的提示词与指示大语言模型llm执行的任务相关联;
19、基于所述原始文本数据以及关联的所述提示词,利用所述llm提取所述原始文本数据中相关的主体信息和非主体信息;
20、根据关联的所述提示词,利用所述llm剔除所述非主体信息中直接包含或间接包含的所述主体信息,以对所述非主体信息进行匿名化处理;以及,
21、对所述主体信息进行匿名化处理;
22、基于匿名化后的所述主体信息和所述非主体信息,利用所述llm,将匿名化后的所述主体信息和所述非主体信息合并为自然语言。
23、可选的,所述处理器具体被配置为:
24、根据llm确定的非主体信息,再次根据关联的所述提示词,利用所述llm进行推理,以对所述主体信息进行补充。
25、可选的,所述处理器具体被配置为:
26、对所述主体信息进行脱敏处理;以及,
27、对脱敏后的所述主体信息,利用匿名化算法进行匿名化处理
28、可选的,所述处理器具体被配置为:
29、为所述主体信息中的各项属性设置离群值,以将属性限定在设定范围,消除异常属性值。
30、本申请实施例还提出一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如前述的利用大语言模型的自然语言匿名化方法的步骤。
31、本申请实施例通过大语言模型和匿名化方法,提出了一种对文本数据完成脱敏的有效方法,最大程度上保留信息和语义。
32、上述说明仅是本申请技术方案的概述,为了能够更清楚了解本申请的技术手段,而可依照说明书的内容予以实施,并且为了让本申请的上述和其它目的、特征和优点能够更明显易懂,以下特举本申请的具体实施方式。
技术特征:1.一种利用大语言模型的自然语言匿名化方法,其特征在于,包括:
2.如权利要求1所述的利用大语言模型的自然语言匿名化方法,其特征在于,基于所述原始文本数据以及关联的所述提示词,利用所述llm提取所述原始文本数据中相关的主体信息和非主体信息包括:
3.如权利要求1所述的利用大语言模型的自然语言匿名化方法,其特征在于,在对所述主体信息以及所述非主体信息进行匿名化之前还包括:
4.如权利要求1所述的利用大语言模型的自然语言匿名化方法,其特征在于,对所述主体信息进行匿名化处理包括:
5.如权利要求4所述的利用大语言模型的自然语言匿名化方法,其特征在于,对所述主体信息进行匿名化处理还包括:
6.一种利用大语言模型的自然语言匿名化装置,其特征在于,包括处理器,被配置为:
7.如权利要求6所述的利用大语言模型的自然语言匿名化装置,其特征在于,所述处理器具体被配置为:
8.如权利要求6所述的利用大语言模型的自然语言匿名化装置,其特征在于,所述处理器具体被配置为:
9.如权利要求8所述的利用大语言模型的自然语言匿名化装置,其特征在于,所述处理器具体被配置为:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至5中任一项所述的利用大语言模型的自然语言匿名化方法的步骤。
技术总结本申请公开了一种利用大语言模型的自然语言匿名化方法、装置及存储介质,涉及人工智能技术,包括:获取原始文本数据,并配置提示词;基于所述原始文本数据以及关联的提示词,利用所述LLM提取所述原始文本数据中相关的主体信息和非主体信息;利用所述LLM剔除所述非主体信息中包含的主体信息,以完成所述非主体信息的匿名化;并对所述主体信息进行匿名化处理;基于匿名化后的所述主体信息和所述非主体信息,利用所述LLM,将匿名化后的所述主体信息和所述非主体信息合并为自然语言。本申请提供了一种对文本数据完成脱敏的有效方法,能够最大程度上保留信息和语义。技术研发人员:陆志鹏,韩光,郑曦,国丽,郭祎萍,周蒙,孙自立受保护的技术使用者:中电数据产业集团有限公司技术研发日:技术公布日:2024/9/12本文地址:https://www.jishuxx.com/zhuanli/20240914/295577.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表