一种基于视频流姿态模拟的捕捉方法与流程
- 国知局
- 2024-09-14 14:51:21
本发明涉及视频姿态捕捉,具体涉及一种基于视频流姿态模拟的捕捉方法。
背景技术:
1、人体姿态捕捉是图像处理中一项重要任务,旨在从输入图像或时序视频中估计人体关键点信息,例如头部、肩膀、腿部等,然后将关节点组成正确的人体姿态,从而推断出人体空间位置,人体姿态估计已成为计算机捕捉人体动作和行为信息的一个重要手段,通过将视频图像中的多帧人体姿态连接起来可形成人的行为轨迹,可以提供重要的行为描述信息,人体姿态估计具有非常广阔的应用前景。
2、目前基于视频流的姿态捕捉按照不同输入数据的类型,将人体姿态捕捉方法划分为以下两类:基于视频序列的人体姿态估计方法和基于动态图像的人体姿态估计方法,主要存在以下问题:
3、(1)基于视频序列的人体姿态估计方法,存在网络参数量大、运算复杂度高以及模型感知能力不足的问题;
4、(2)基于动态图像的人体姿态估计方法,虽然在动态图像上取得了显著的效果,但是实际场景中将其直接应用至视频数据时,会产生性能上的下降,检测精度是无法和图片数据上的结果进行比较,没有充分考虑视频帧之间的时序信息,尤其当视频中出现部位遮挡和大量异物遮挡时,无法保证视频帧之间的几何一致性和时间依赖性,会产生较差的估计结果。
技术实现思路
1、本发明的目的在于提供一种基于视频流姿态模拟的捕捉方法,以解决现有技术中对于现有技术中存在网络参数量大、运算复杂度高、模型感知能力不足以及无法保证视频帧之间的几何一致性和时间依赖性的技术问题。
2、为解决上述技术问题,本发明具体提供下述技术方案:
3、本发明提供了一种基于视频流姿态模拟的捕捉方法,包括以下步骤:
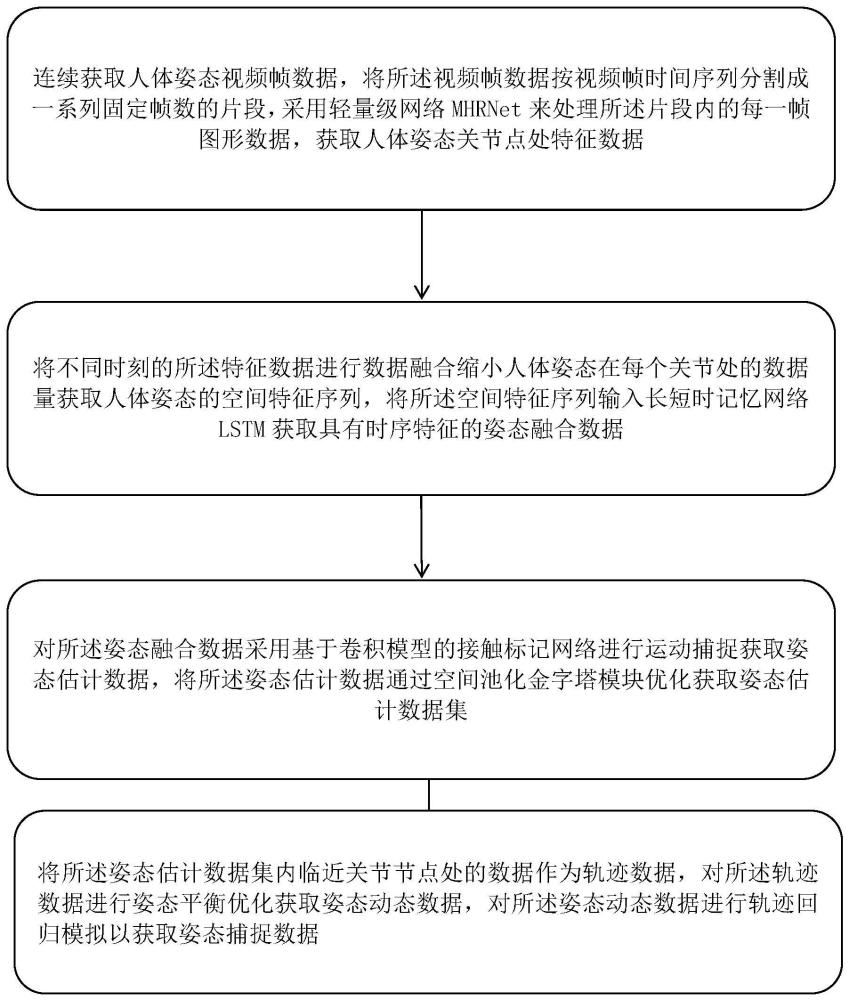
4、连续获取人体姿态视频帧数据,将所述视频帧数据按视频帧时间序列分割成一系列固定帧数的片段,采用轻量级网络mhrnet来处理所述片段内的每一帧图形数据,获取人体姿态关节点处特征数据;
5、将不同时刻的所述特征数据进行数据融合缩小人体姿态在每个关节处的数据量获取人体姿态的空间特征序列,将所述空间特征序列输入长短时记忆网络lstm获取具有时序特征的姿态融合数据;
6、对所述姿态融合数据采用基于卷积模型的接触标记网络进行运动捕捉获取姿态估计数据,将所述姿态估计数据通过空间池化金字塔模块优化获取姿态估计数据集;
7、将所述姿态估计数据集内临近关节节点处的数据作为轨迹数据,对所述轨迹数据进行姿态平衡优化获取姿态动态数据,对所述姿态动态数据进行轨迹回归模拟以获取姿态捕捉数据。
8、作为本发明的一种优选方案,将连续的所述人体姿态视频帧数据输入循环卷积神经网络中获取按视频帧时间序列排列的视频帧特征数据,包括:
9、将所述人体姿态视频帧数据输入所述循环卷积神经网络中,所述循环卷积神经网络通过卷积层和池化层逐步提取每一帧图像的空间信息,所述循环卷积神经网络采用有向有环计算模式获取卷积神经网络系统状态,表达式为:
10、h(t)=f(αh(t-1),βx(t),θ)
11、x(t)=σ(x(t-1))
12、其中,x(t)表示t时刻的卷积层输入,f表示非线性激活函数,h(t)表示t时刻的隐藏状态,h(t-1)表示t-1时刻的隐藏状态,α、β表示隐藏状态下权值矩阵,θ表示偏置向量,σ表示激活函数,x(t-1)表示t-1时刻的卷积层输入;
13、并将所述空间信息转换为特征向量,将所述特征向量按视频帧时序序列进行排序获取视频帧特征数据。
14、作为本发明的一种优选方案,依据时间序列对所述视频帧数据采用基于时间约束的轻量级网络mhrnet,获取相邻帧之间人体姿态关节点处的特征数据,包括:
15、依据事件序列对所述视频帧数据进行连续帧排序,获取所述连续帧与时间相关性的联系,采用lstm作为所述轻量级网络mhrnet的模型,获取所述视频帧数据之间的几何一致性和时间依赖性的关系,提取基于所述时间序列的视频帧特征数据;
16、将所述视频帧特征数据输入所述轻量级网络mhrnet建立关节点处热力图,将当前所述热力图的热点数据通过逐一元素相加合并的方式融合上一帧关节处热力图数据和当前热力图数据,获取合并后的特力图数据;
17、将合并后的所述热力图数据通过循环卷积神经网络复制和处理相同数据,获取每一帧中相互独立的关节处特征数据,将所述关节处特征数据进行融合,通过分组卷积获取关节处姿态时间约束的数据,将具有时间约束的数据作为所述人体姿态关节点处的特征数据。
18、作为本发明的一种优选方案,将不同时刻的所述特征数据通过姿态时域管理缩小人体姿态在每个关节处的数据量,通过多级卷积神经网络获取人体姿态的空间特征序列,包括:
19、依据所述特征数据的时序将不同时段中的特征数据逐帧输入多级卷积神经网络中,在所述多级卷积神经网络中设置中心高斯映射连接不同卷积单元建立递归神经网络;
20、在所述递归神经网络中通过长短时记忆网络lstm获取所述特征数据几何一致的相同帧和时序向量,通过所述时序向量对相同帧进行编码获取关节点处的关联;
21、以所述关节点处的关联性建立基于人体姿态的空间坐标,对人体每个关节点设置学习权重,通过将人体关节点特征数据输入多级卷积神经网络中获取每个关节点对应的一个权重向量;
22、通过所述权重向量建立三维卷积核获取每个关节位置学习不同的变换矩阵,通过所述特征数据的最终捕捉实际需求实时调整关节数据量,获取具有时序特征的姿态融合数据;
23、作为本发明的一种优选方案,对所述姿态融合数据采用接触标记网络进行运动捕捉获取姿态估计数据,包括:
24、所述接触标记网络采用图卷积模型连接人体姿态的空间坐标,对关节点分布状态进行分类,根据所述人体姿态的空间坐标构建关节点处骨架图g(v,e,h),其中v、e、h分别表示人体姿态在空间直角坐标系中的三维向量,通过图卷积模型获取关节处在运行中的输出特征xout:
25、
26、其中,p={r,u,l}分别表示人体中心,上半身关节和下半身关节,p表示人体关节,a∈{0,1}n×n表示n×n维邻接矩阵,d∈rn×n表示n×n维关节对角度矩阵,xin∈rn×n表示关节点的输入特征,表示t时刻人体关节p处可学习的权重矩阵和特征矩阵;
27、将所述输出特征xout连接所述长短时记忆网络lstm,通过所述长短时记忆网络lstm输出的逐帧时序向量获取姿态的连接结构,根据所述姿态的连接结构通过判断是否接触获取关节点的二维关节节点,以捕捉姿态估计数据。
28、作为本发明的一种优选方案,将所述姿态估计数据通过空间池化金字塔模块优化获取姿态估计数据集,包括:
29、对所述姿态估计数据进行自底而上的逐层降重采样,构造高斯金字塔数据模型,采用l-k光流算法检测图层中的运动物体,获取像素点在所述图层的关键帧数据;
30、从所述高斯金字塔数据模型的最高层开始向下依次迭代每层中对应像素点的关键帧数据,将间隔帧定义为每隔三帧取一帧,逐层对所述关键帧数据进行提取,对所述提取结果进行修正获取姿态估计数据;
31、对所述姿态估计数据建立mpii数据集,并将所述姿态估计数据映射回最终的原图上;
32、作为本发明的一种优选方案,将所述姿态估计数据集内临近关节节点处的数据作为轨迹数据,对所述轨迹数据进行姿态平衡优化获取姿态动态数据,包括:
33、通过所述姿态估计数据映射的原图数据获取透视矩阵k,设置所述原图的投影比例s,通过对所述姿态估计数据集内的姿态估计数据构建损失函数lc:
34、w′=skx
35、lr(x,k)=‖w-kx‖f
36、
37、其中,x表示基于原图预测的三维姿态,w表示基于原图预测的二维姿态,w′表示反向预测后的姿态,f表示关节处动态姿态数据,lr(x,k)表示反向映射的损失函数,i2表示基于原图设置的恒等矩阵,lc表示基于原图参数预测的损失函数;
38、通过损失函数lc反向映射检测姿态偏差,调整所述循环卷积神经网络中的卷积参数,以动态捕捉姿态数据。
39、本发明与现有技术相比较具有如下有益效果:
40、本发明采用基于时间约束的lstm模块,对视频帧之间的几何一致性和时间依赖性进行建模,并构建姿态时间约束模块,压缩关键点的搜索范围,通过空间池化金字塔模块,增加了模型的感受视野范围,融合了局部细节特征和全局特征,有效提高了人体姿态捕捉的准确率。
41、采用高分辨率轻量级网络mhrnet作为骨干网络,减少模型的参数量和计算复杂度,实现轻量化网络的目标,采用循环卷积网络模型为小尺度的关键点提供更准确的特征,并降低定位误差带来的影响,解决了细节丢失的问题,在出现遮挡和尺度较小的情况下,能够有效的捕捉关键点的信息,有效提升了特征提取以及捕捉能力。
本文地址:https://www.jishuxx.com/zhuanli/20240914/296170.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表