一种基于局部特征与全局特征提取网络的3D-HEVC深度图编码单元划分方法
- 国知局
- 2024-09-14 14:55:32
本发明涉及视频压缩编码领域,尤其涉及一种基于局部特征与全局特征提取网络的3d-hevc深度图编码单元划分方法。
背景技术:
1、近年来,伴随着移动通讯技术的飞速发展,3d视频逐渐受到越来越多的关注。3d-hevc在hevc标准的基础上引入了深度图以及众多针对深度图的编码技术,采用多视点纹理加深度(multi-view video plus depth,mvd)的格式对3d视频进行编码,随后引入基于深度图像的绘制技术(depth image based rendering,dibr)在真实视点之间合成虚拟视点。这些新编码技术的出现大幅提升了3d-hevc的压缩性能,但也同时带来了巨大的深度图编码复杂度,严重拖累了3d视频编解码的速度。特别地,编码过程中的深度图编码单元(coding unit,cu)的划分步骤极其复杂耗时,占整体编码复杂度的九成左右,成为阻碍3d-hevc大规模应用的关键。
2、近年来为实现3d-hevc快速编码开展了大量的相关研究,许多传统方法关注纹理图和深度图的纹理特征、边缘类型或时空相关性等特征,通过较为繁琐的手工阈值提取来判断cu分类,在一定程度上限制了算法的泛化性能。随着深度神经网络的不断发展壮大,基于深度学习的3d-hevc快速编码方法不断涌现。这些方法利用深度学习自发提取原始信号特征、自动学习特征层次化表达的特点,从大量训练数据中得到cu划分或预测模式选择规律,显著提升了编码效率。本发明基于3d-hevc标准,提出了一种基于卷积神经网络(convolutional neural networks,cnn)的深度图cu快速划分方法。利用对cu划分结构的预测加快复杂耗时的深度图cu划分过程,能够在保持率失真性能几乎不变的条件下,有效降低3d-hevc的编码复杂度,实现快速编码。
技术实现思路
1、本发明的目的在于,针对当前3d-hevc中深度图编码采用的cu划分过程复杂度较高,从而影响3d视频编码速度的问题,提出了一种基于局部特征与全局特征提取网络的3d-hevc深度图编码单元划分方法。
2、为实现上述目的,本发明提供了如下技术方案:
3、步骤1:构建用于训练和测试的编码视频数据集
4、首先选择6个不同视频内容、不同镜头特点标准测试序列的深度图用于训练和测试,包括1024*768和1920*1088两种分辨率,随后在3d-hevc参考软件htm16.0上编码所有选择的序列。编码在4个不同的量化参数qps下分别进行,qps的取值分别为34,39,42,45。编码后将包含深度信息的、大小为64*64的编码单元cu与四种qps下的编码划分标签组成一个训练/测试样本。最后由若干已打乱排列顺序的样本构成数据集,其中训练集包含来自kendo和undo_dancer序列的共185100个样本、验证集包含来自balloons和poznan_hall2序列的共7020个样本、测试集包括来自newspaper和poznan_street序列的共14040个样本。
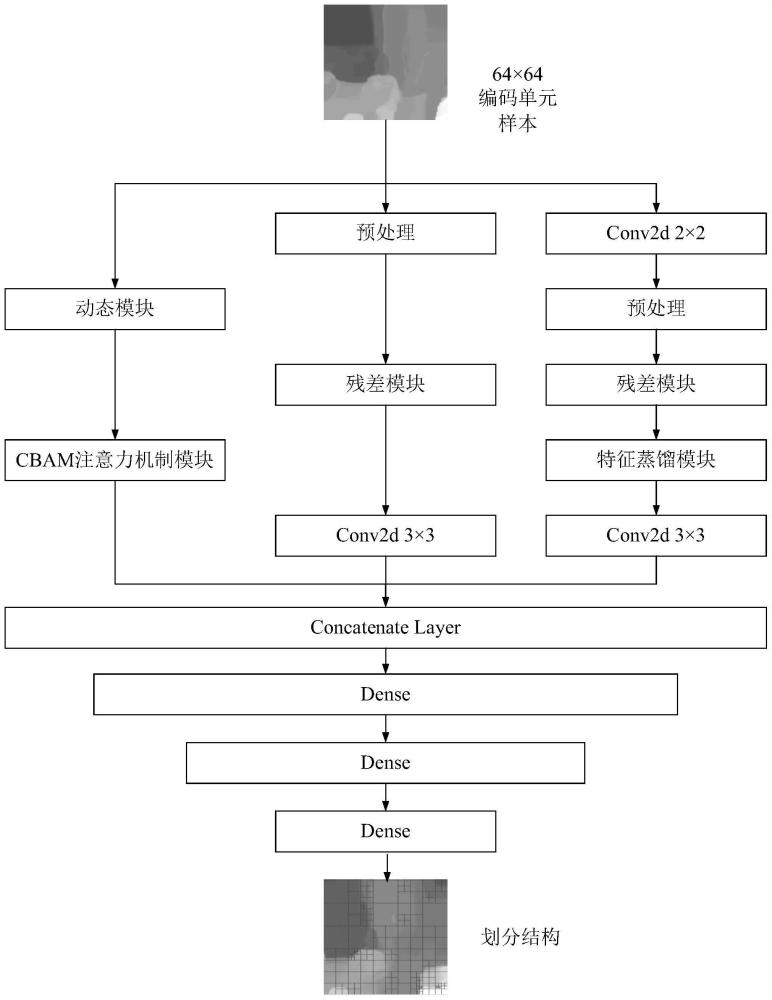
5、步骤2:构建全局图像特征提取网络分支
6、网络具体包括两个全局图像特征提取分支和一个局部图像特征提取分支,包含残差模块的两个网络分支负责提取全局图像特征,学习的特征用于深度图划分中低深度层级划分结构参考。依据多层次特征融合的思想,第一分支直接输送64*64的样本进入预处理操作部分,去除均值,归一化输入像素。而第二分支则首先经卷积核为2*2的卷积操作,依靠与卷积核尺寸相同的卷积运算跨步步长,通过非重叠卷积的方式减少特征图一半的空间尺寸,提取全局图像特征中的底层特征,随后对32*32特征图进行预处理。对于第一分支,空间尺寸为64*64的特征经预处理部分后进入残差模块。残差模块的设计包含一个卷积核为3*3的重叠卷积层和三个连续的残差单元,而残差单元则由两个卷积核为3*3的重叠卷积层构成,其中采用leaky relu激活函数为网络中加入非线性特征,在训练过程中自适应地学习整流器的参数并有效地提高参数的精度,并且在最后一个卷积层的输出处与原始输入进行跳跃连接并逐元素相加,减少噪声的影响。该分支随后经一个卷积核为3*3的重叠卷积层,得到分支输出的特征向量。对于第二分支,32*32样本经预处理后首先进入与第一分支相同结构的残差模块,随后在残差模块后增添了特征蒸馏模块来进一步增强其全局图像特征提取能力。特征蒸馏模块由3个类似残差单元的网络结构构成,其输出和原始输入经卷积核为1*1的卷积层和leaky relu激活函数后一同拼接,使得输出特征图的通道数变为输入的4倍,丰富提取到的全局图像特征,再经卷积核为1*1的卷积层和leaky relu激活函数得到第二分支的最终输出。
7、步骤3:构建局部图像特征提取网络分支
8、该分支的输入首先通过动态模块,得到尺寸为16*16的局部特征图,随后通过cbam注意力机制模块,提取相对原始输入而言的局部样本上的全部特征,从而构成双特征流网络中的局部图像特征流。所设计的动态模块会根据qp值的不同而动态调整其结构,能够解决编码单元划分结构随qp的减小而变复杂导致对网络局部信息提取能力的要求变高的问题,有效防止不同qp下的编码速度产生巨大的差异。其特征在于,当(纹理qp,深度qp)取值为(30,39)、(35,42)以及(40,45)时,编码单元划分结构不存在巨大的差异,此时动态模块采用如附录图4(1)所示的结构,输入首先经一个卷积核为4*4的非重叠卷积层,得到空间尺寸为原本1/4的特征图,随后经去均值等归一化操作得到动态模块的输出;当(纹理qp,深度qp)的取值为(25,34)时,此时的编码单元划分结构与以上三种取值下的划分结构存在较大差异,动态模块采用如附录图4(2)所示的结构,输入首先经检测错误率低且定位边缘较为精准的canny边缘检测算法找到边缘复杂度最高的尺寸为16*16的特征图,随后经去均值等归一化操作得到动态模块的输出,进入cbam注意力机制模块。cbam注意力机制模块由三个conv-cbam子块构成,每一个conv-cbam子块由一个卷积核为3*3的重叠卷积层和cbam模块组成。cbam模块包括利用输入特征通道间关系生成通道注意力图的通道注意力模块cam和利用输入特征空间关系生成空间注意力图的空间注意力模块sam,其输入首先经cam,随后将输出与原始输入逐元素相乘送入sam,sam的输出再与sam的输入进行逐元素相乘得到最终的输出。双特征流网络连续使用三个conv-cbam子块的设计,有效加强了对于动态模块中筛选与提取的重要局部信息的甄别与学习,最终得到局部图像特征流的输出。
9、步骤4:构建特征流整合输出部分
10、将双特征流网络第一、二分支提取的全局图像特征流和最后一个网络分支提取的局部图像特征流送入合并层进行整合,充分利用提取到的全部特征以及分支间相关性。合并后的特征向量经过两层以relu为激活函数的全连接层和一层以sigmoid为激活函数的输出层得到编码单元最终划分结果,该结果将被用作实际3d视频编码过程中的参考。
本文地址:https://www.jishuxx.com/zhuanli/20240914/296392.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表