一种多模型比较得出的用户类型分析方法与流程
- 国知局
- 2024-09-14 14:55:39
本发明涉及用户数据分析,尤其是涉及的是一种多模型比较得出的用户类型分析方法。
背景技术:
1、现有的烟草营销过程中,由于用户的多样性及庞杂的购买数据,烟草经营人员很难对现有消费者用户进行消费类型判断及评定其是否为烟草高价值用户,从而无法开展后续的高价值客户营销推广,在面对新的客户群体,也没有一个综合合理的评价指标对其进行分析,判断其应该重点培养哪个方面,才可以顺利成长为新的高价值用户。
技术实现思路
1、本发明的其他特征和优点将在随后的说明书中阐述,并且部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书以及其他说明书附图中所特别指出的结构来实现和获得。
2、本发明的目的在于克服上述不足,提供一种多模型比较得出的用户类型分析方法,通过现有的部分高价值用户,分析其具有的特征标签及评价指标,对其进行聚类算法,生成具有多个特征标签及评价指标的种子用户画像,通过计算其他用户与聚类中心的距离可获得一分数,通过ahp层次分析法确定不同特征标签及评价指标的权重,结合每个用户所具有的特征标签及评价指标,形成另一分数,通过比较所有用户两分数的总值,综合判断出小范围内用户中的实际烟草高价值用户,根据判断出的实际烟草高价值用户进行相似人群拓展,通过比较多个分类算法模型的综合预测能力,选取其优者预测更大范围内的客户是否有成为烟草高价值用户的潜质,根据其缺少的特征标签进行重点培养,从而形成新的烟草高价值用户。
3、本发明提供一种多模型比较得出的用户类型分析方法,包括:
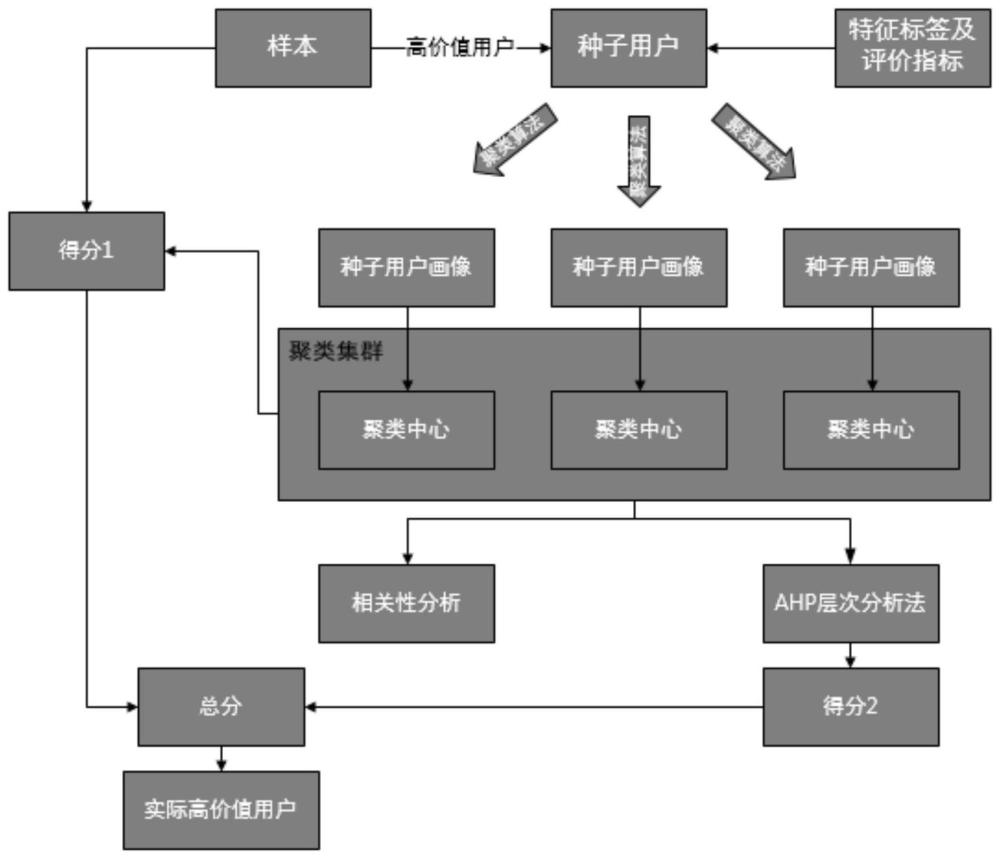
4、s1、将客户提供的一部分高价值客户样本作为种子用户,根据已构建的特征标签对种子用户进行特征分析及分类,聚类生成多个具有不同特征标签及下属评价指标的种子用户画像,计算其他用户和每个聚类中心之间的距离,根据最小距离确定每个用户的得分1;
5、s2、种子用户画像进行特征的相关性分析,比较不同特征标签下属评价指标之间的相关性,使用ahp层次分析法确定不同特征标签下属的评价指标的指标权重,结合每个用户的实际特征标签,计算每个用户的得分2;
6、s3、将s1与s2两部分的结果结合起来计算用户的最终烟草价值得分,进而判断该用户是否为烟草高价值用户,在小范围人群中筛选出实际的烟草高价值用户;
7、s4、在获得实际烟草高价值用户的基础上,进行相似人群拓展,即预测在大范围人群中是否有其他客户为烟草高价值用户,相似人群拓展通过建立分类算法模型实现,该分类算法模型包括决策树模型、逻辑回归模型和随机森林模型,利用混淆矩阵对多个分类算法进行准确率、精准率、回归率及f1-score的计算,选取模型效果最好的做为最终模型预测大范围人群中的烟草高价值用户;
8、s5、利用模型结果对大范围人群进行分类和概率输出,获取相似的高价值客户群。
9、在一些实施例中,该特征标签包括人口属性、消费能力、人员类型、富裕指数、兴趣偏好、消费偏好六类,每个特征标签下还具体细分有多个评价指标。
10、在一些实施例中,种子用户在聚类之前需要进行数据处理,该数据处理过程具体包括:字段剔除、空值填充、字段衍生或单位转换、字符串映射以及标准化处理,标准化处理的公式为:
11、a=(a-min(a))/(max(a)-min(a))
12、其中,a为特征原始数据,min(a)为特征原始数据中的最小值,max(a)为特征原始数据中的最大值,a为归一化得出的值,a∈[0,1]。
13、在一些实施例中,在s1步骤中,聚类分析的具体步骤为:
14、s11、初始化聚类中心:从数据集中随机选择k个样本作为初始的聚类中心点,这些中心点为随机选择或通过其他方法得到;
15、s12、分配样本到最近的聚类中心:计算每个样本与k个聚类中心的距离,并将样本分配到距离最近的聚类中心所属的类别;
16、s13、更新聚类中心:对于每个聚类,计算该类别中所有样本的平均值,将该平均值作为新的聚类中心;
17、s14、重复s12和s13步骤,直到聚类中心不再发生变化,或者达到预定义的迭代次数;
18、通过聚类分析后,种子用户根据不同特征标签下的多个评价指标聚集成多个聚类中心,计算小范围用户与各聚类中心之间的距离,从而获得根据最小距离确定每个用户的得分1。
19、在一些实施例中,在s2步骤中,种子用户画像在经过数据处理后需要进行特征的相关性分析,比较单个特征标签之下不同评价指标之间的相关性,计算两评价指标之间相关性的公式为:
20、
21、其中,x,y分别代表两评价指标中的数据,μ为pearson相关系数,用于检测两个变量是否线性相关;
22、在一些实施例中,pearson相关系数要求数据需来自于正态分布的总体,相关系数在[-1,1]之间,越接近±1,相关性越强,越靠近0,相关性越弱,常规相关等级为:μ=0二者完全不相关;0<|μ|<=0.3弱相关;0.3<|μ|<=0.5中等相关;0.5<|μ|<=0.8显著相关;0.8<|μ|<=1强相关。
23、在一些实施例中,在进行评价指标之间的相关性计算后需要对不同评价指标之间的重要性进行排序,减少计算量和模型复杂度,提高模型效率,通过ahp层次分析法确定不同评价指标的指标权重,结合每个用户本身所具有的评价指标,计算得到每个用户的得分2。
24、在一些实施例中,在s3步骤中,最终得分的计算公式为:
25、score=1/2*(score1+score2)
26、其中,score1为s1步骤中每个用户的最小距离得分,即得分1;score2为s2步骤中,每个用户根据其自身所具有的评价指标所得到的评价指标得分,即得分2;score为最终得分。
27、在一些实施例中,在s4步骤中,混淆矩阵的评价标准包括准确率、精确率、召回率和f1-score,其中准确率的计算公式为:
28、accuracy=(tp+tn)/(tp+fp+tn+fn)
29、精确率的计算公式为:
30、precision=(tp)/(tp+fp)
31、召回率的计算公式为:
32、recall=(tp)/(tp+fn)
33、f1-score的计算公式为:
34、f1-score=2x(精确率x召回率)/(精确率+召回率)
35、其中,tp为真阳性数值,tn为真阴性数值,fp为假阳性数值,fn为假阴性数值,准确率accuracy为所有被分类正确的点在所有点中的概率,精确率precision表示的是预测为正的样本中有多少为真正的正样本,召回率recall表示的是样本中的正例有多少被预测正确,f1-score为精确率和召回率的加权平均值,f1-score的最佳值为1。
36、通过采用上述的技术方案,本发明的有益效果是:
37、本发明通过现有的部分高价值用户,分析其具有的特征标签及评价指标,对其进行聚类算法,生成具有多个特征标签及评价指标的种子用户画像,通过计算其他用户与聚类中心的距离可获得一分数,通过ahp层次分析法确定不同特征标签及评价指标的权重,结合每个用户所具有的特征标签及评价指标,形成另一分数,通过比较所有用户两分数的总值,综合判断出小范围内用户中的实际烟草高价值用户,根据判断出的实际烟草高价值用户进行相似人群拓展,通过比较多个分类算法模型的综合预测能力,选取其优者预测更大范围内的客户是否有成为烟草高价值用户的潜质,根据其缺少的特征标签进行重点培养,从而形成新的烟草高价值用户。
38、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
39、无疑的,本发明的此类目的与其他目的在下文以多种附图与绘图来描述的较佳实施例细节说明后将变为更加显见。
40、为让本发明的上述和其他目的、特征和优点能更明显易懂,下文特举一个或数个较佳实施例,并配合所示附图,作详细说明如下。
本文地址:https://www.jishuxx.com/zhuanli/20240914/296402.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。