一种融合注意力机制和短期时序特征提取的步态识别方法
- 国知局
- 2024-10-09 15:45:02
本发明属于计算机视觉中的视频图像处理和步态识别领域,涉及一种融合注意力机制和短期时序特征提取的步态识别方法。
背景技术:
1、步态识别是一种基于人体行走姿态独特性的生物识别技术。由于可以在远距离条件下捕捉人体步态,并且识别过程不需要受试者的配合,因此步态识别可以广泛应用于视频监控、智能交通等领域;
2、目前,人们提出了许多基于深度学习的步态识别框架来生成判别步态特征表示。由于步态特征中包含多个复杂的运动模式和细节信息,目前大多数基于卷积神经网络的步态识别框架往往很难注意到某些特定的具有判别性的步态特征(如步长、步频、肢体摆动)等;此外,在步态时序特征提取上,目前的步态识别方法大多只使用常规卷积进行时间特征提取。由于有限的接受野,很难提取长期的时间关系。由于相邻帧之间的差异非常小,仅通过相邻帧的时间建模很难学习到判别性的时间特征,导致对遮挡的鲁棒性较差。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了一种融合注意力机制和短期时序特征提取的步态识别方法,解决了上述背景技术中的问题。
3、(二)技术方案
4、本发明为了实现上述目的具体采用以下技术方案:
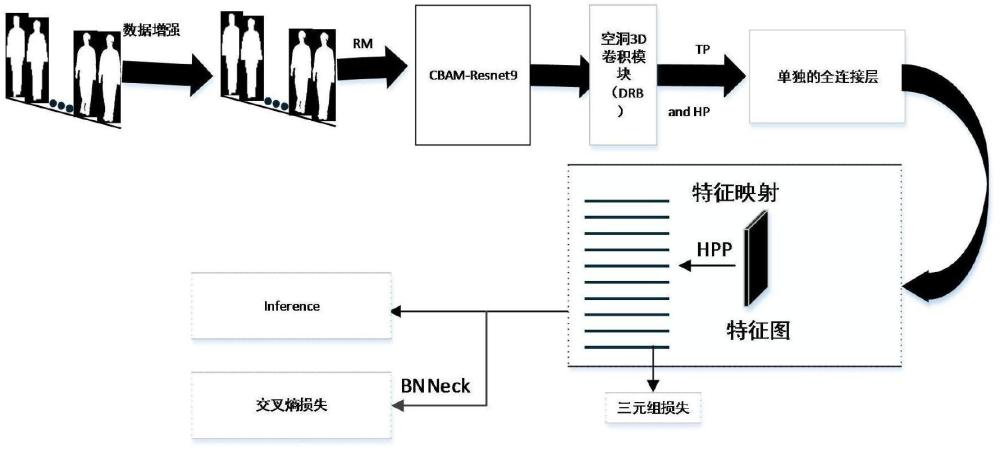
5、一种融合注意力机制和短期时序特征提取的步态识别方法,该方法包括以下步骤:
6、s1.准备数据集,对步态数据集进行数据增强和预处理,然后将步态轮廓序列输入到随机掩模(rm)中进行数据增强;
7、s2.构建基于双重注意力机制的cbam-resnet9骨干网络模型,对步态图像特征进行提取,并将输出转换为具有高度、宽度和通道尺寸的3d特征图;
8、s3.采用空洞3d卷积模块(drb)进行短期时序特征提取,将输出的3d步态特征图进行时序特征提取,通过时间特征提取模块,从高层空间特征图中提取短期时间特征,实现了短期时序建模;
9、s4.利用时间池化和均值池化得到几个特征向量,并通过一个独立的全连接层将特征向量映射到度量空间;进一步采用bnneck来调整特征空间,并利用分离的三元组和交叉熵损失来驱动训练过程;
10、s5.使用训练好的网络进行前向推理时,计算probe和gallery的融合特征之间的欧几里得距离和余弦距离,可以用来计算从画廊和探针集的样本之间的相似性,根据距离进行排序,并计算rank-1识别准确率,距离最近的即为来自同一个样本的序列。
11、进一步地,所述s1中,对输入步态数据进行水平翻转、旋转、透视和仿射变换等操作,然后将每帧图像归一化为64×44的尺寸;输入一批包含多个步态样本的数据,表示为×in∈rc×t×h×w,其中c是通道数,t是步态序列的长度,(h,w)是每帧图像的大小;
12、进一步地,所述s2中,在类resnet9的网络结构中实现了对步态图像特征的高效提取;具体细节如下:在cbam-resnet9的网络结构中实现了对步态图像特征的高效提取,具体细节如下:采用基于通道注意力机制和空间注意力机制的残差网络作为主干网络,所述残差网络的结构包括:卷积核大小为3×3,通道数为64,步长和padding为1的卷积层γ1,卷积核大小为3×3的最大池化下采样层4个残差结构组layer1,layer2,layer3,layer4沿主干网络输入-输出方向依次串联,其中layer1残差结构组中是由1个残差结构a1组成,残差结构a1由沿主干网络输入-输出方向依次串联的以下两个卷积层构成:卷积核大小为3×3,输入通道数为64,输出通道数为64的卷积层,卷积核大小为3×3,输入通道数为64,输出通道数为64的卷积层;在卷积层γ1后依次插入通道注意力机制和空间注意力机制,通道注意力机制和空间注意力机制插入前的卷积层的通道数记为θ,θ等于64;
13、所述残差结构组layer2是由1个残差结构a2组成,残差结构a2由沿主干网络输入-输出方向依次串联的以下两个卷积层构成:卷积核大小为3×3,输入通道数为64,输出通道数为128的卷积层,卷积核大小为3×3,输入通道数为128,输出通道数为128的卷积层;
14、所述残差结构组layer3是由1个残差结构a3组成,残差结构a3由沿主干网络输入-输出方向依次串联的以下两个卷积层构成:卷积核大小为3×3,输入通道数为128,输出通道数为256的卷积层,卷积核大小为3×3,输入通道数为256,输出通道数为256的卷积层;
15、所述残差结构组layer4是由1个残差结构a4组成,残差结构a4由沿主干网络输入-输出方向依次串联的以下两个卷积层构成:卷积核大小为3×3,输入通道数为256,输出通道数为512的卷积层,卷积核大小为3×3,输入通道数为512,输出通道数为512的卷积层,最终输出记为m,表示为
16、m∈rc1×t1×h1×w1;
17、进一步地,所述s3中,空洞3d卷积模块(drb)的构建具体如下:
18、空洞3d卷积模块(drb)由带有残差连接的多尺度扩展卷积块组成,该模块可以高效捕获短时间信息。使得网络在轮廓部分缺失的前提下可以通过其他帧获取补充信息,有效提高了网络对遮挡的鲁棒性。drb概述,它是由空洞时序3d卷积层、修正线性单元和批归一化组成。其形式定义为:
19、fdrb=drb(m)∈rc1×t2×h1×w1。
20、进一步地,所述s4中,利用时间池和均值池层实现特征映射,将输入特征映射通过多个独立的全连接层进行前向传播,从而实现对特征信息的聚合。采用bnneck来调整特征空间,定义三重态损失函数和交叉熵损失函数,在训练过程中,通过反向传播算法(backpropagation algorithm)和优化器(optimizer),迭代更新模型的权重参数,以最小化三重态损失函数和交叉熵损失函数。
21、(三)有益效果
22、与现有技术相比,本发明提供了一种融合注意力机制和短期时序特征提取的步态识别方法,至少具备以下有益效果:
23、一、在类resnet9的网络结构中巧妙地融合了空间注意力机制和通道注意力机制。针对输入的步态图像,这两种注意力机制分别专注于图像中的特征内容和特征位置,它们相互补充,显著提升了网络对步态特征的提取能力。在本发明的网络架构中,空间注意力机制关注于图像中的空间布局,突出步态的关键特征位置;而通道注意力机制则侧重于特征内容的强度,强化了那些对于识别任务更为关键的图像特征。这种融合使得网络能够更加精确地识别不同人的步态。
24、经过多次实验验证,我们将注意力机制放置在第一个卷积层之后,这样的设置能够使得网络在特征提取的初期阶段就关注到重要的信息,从而提升了整个网络的性能。经过多次试验之后,将该注意力放在第一个卷积层之后,可以获得更好的效果。为了验证本发明的有效性,我们在casia-b数据集上进行了详尽的消融实验。在不引入短期时间聚合模块的情况下,仅通过融合注意力机制,相较于baseline算法,本发明的模型就在正常行走条件下达到了平均97.7%(97.6%)的准确率,相较于baseline算法有了显著的提升。更重要的是,由于本发明的模型对特征信息的深入挖掘,使得它在面对协变量因素(如穿大衣、背包等)时,也表现出了较强的鲁棒性。在穿大衣和背包的条件下,平均识别率分别达到了94.0%和80.2%,相较于其他算法,如gaitbase,在相同条件下有着更高的识别率。
25、二、本发明采用了一种创新的方法,通过对步态序列中的时间特征进行随机遮挡,并结合短期时序特征提取技术,显著提升了网络对遮挡条件的鲁棒性。特别是在背包行走的复杂场景下,本发明的平均识别率达到了82.2%,相较于gaitbase在相同背包条件下的77.4%平均识别率,实现了4.8%的显著提升。这一成果表明,本发明能够有效捕捉并处理步态序列中的短期时间信息,从而在各种实际环境中提供更加稳定和准确的步态识别结果。
本文地址:https://www.jishuxx.com/zhuanli/20240929/309913.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表