一种基于提示引导的零样本图像分类方法及系统
- 国知局
- 2024-10-09 15:49:19
本发明涉及计算机视觉人工智能,尤其涉及一种基于提示引导的零样本图像分类方法及系统。
背景技术:
1、目前,人工智能在图像特征提取到分类的端到端模型技术在计算机视觉和图像处理方向已经相当成熟,能够在大量带标签样本支持下获得高分类精度。特别地,当前广泛采用的resnet、vgg等在imagenet数据集上训练出的基于cnn的大型预训练图像模型,已为图像分类提供一种新范式一以它们为骨干网络,并对下游任务进行微调。尽管这些模型能在日常场景下能够出色地完成任务,但是,在一些特定的场景,比如人工标注数据开销昂贵、不同类别样本数量服从长尾分布数量不平衡、低资源领域标注数据稀少且标注数据需要专业知识等极端的场景之下,传统的人工智能模型往往无法发挥作用。另外,训练好的模型只能为训练过程中见过的类别进行分类,在遇到一些未见过的类时,就无法分类。这些问题为图像分类领域带来了一系列挑战。
2、为了应对这种挑战,面向零样本学习的图像分类工作被广泛研究并不断地发展。零样本学习主要是模拟人脑的认知过程,模拟从可见类到不可见类的知识迁移来从可见类中学习到可转移的相关知识,并应用于不可见类的分类中。基于语义提示的零样本图像分类的研究工作主要分为了两类,一类是基于生成的零样本分类模型,一类是基于嵌入的零样本分类模型。基于生成的模型旨在通过语义提示为不可见类生成相应的图像特征,并将其简化为一个完全监督的分类问题。基于嵌入的模型希望通过找到一种映射关系,将语义属性映射到视觉空间,或是将视觉特征映射到语义空间,或者,寻找一个公共空间,将语义属性和视觉特征一起映射到公共空间中,其最终的目的,是在同一个向量空间中学习语义和视觉特征的联系,并在这个空间完成分类任务。
技术实现思路
1、本发明的主要目的在于克服现有技术的缺点与不足,提供一种基于提示引导的零样本图像分类方法及系统,其能够在没有可训练的图像样本的场景下,充分利用文本语义提示和属性向量进行自动图像分类,保证了实例级语义信息和实例级视觉信息可靠的跨模态交流,提高了图像分类的精度。
2、根据本发明的一个方面,本发明提供了一种基于提示引导的零样本图像分类方法,所述方法包括以下步骤:
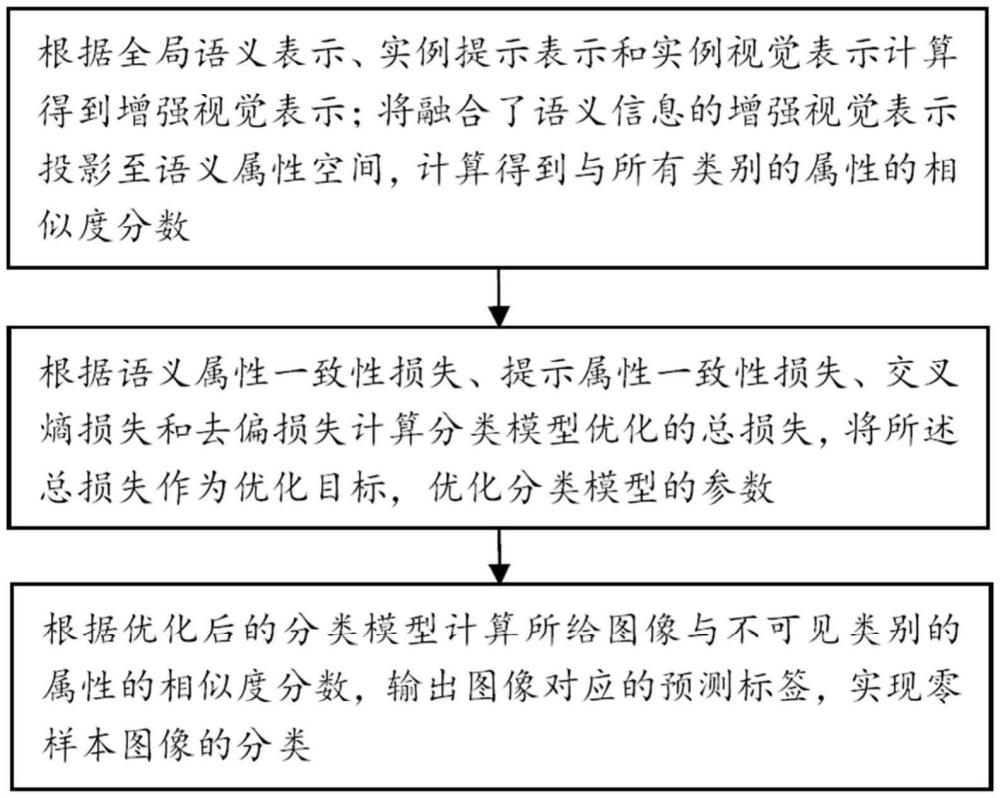
3、根据全局语义表示、实例提示表示和实例视觉表示计算得到增强视觉表示;将融合了语义信息的增强视觉表示投影至语义属性空间,计算得到所有类别的属性的相似度分数;
4、根据语义属性一致性损失、提示属性一致性损失、交叉熵损失和去偏损失计算分类模型优化的总损失,将所述总损失作为优化目标,优化分类模型的参数;
5、根据优化后的分类模型计算所给图像与不可见类别的属性的相似度分数,输出图像对应的预测标签,实现零样本图像的分类。
6、优选地,所述根据全局语义表示、实例提示表示和实例视觉表示计算得到增强视觉表示包括:
7、从数据集中获得可见类的实例图像、对应可见类的属性向量和共享属性的全局语义描述,通过属性向量获得对应的文本化实例提示;
8、将全局语义描述和实例图像对应的实例提示输入到文本编码器中,得到全局语义表示和实例提示表示;将实例图像输入到视觉编码器的前l-1层,得到实例视觉表示;
9、将全局语义表示和实例视觉表示送入语义视觉跨模态融合模块中的视觉实例引导的全局语义增强解码器,得到增强全局语义表示;
10、将增强全局语义表示和实例提示表示输入到语义视觉跨模态融合模块中的提示实例引导的局部增强语义增强解码器,得到局部增强后的局部增强语义表示;
11、将实例视觉表示和局部增强语义表示输入到语义视觉跨模态融合模块中的局部增强语义引导的视觉解码器中,获得增强视觉表示。
12、将增强视觉表示输入到视觉编码器的最后一层编码层进行编码得到编码结果;
13、对所述增强视觉表示的编码结果、全局语义表示和实例提示表示进行融合配对,得到增强视觉表示。
14、优选地,所述将融合了语义信息的增强视觉表示投影至语义属性空间,计算得到所有类别的属性的相似度分数包括:
15、利用余弦相似度评估所给图像与每个类的属性向量的相似度分数:
16、
17、其中,为分类任务的候选标签,z为需要分类类别的属性向量的集合,τ为缩放因子,x为实例图像,为增强视觉表示,wp为全连接层,gap为一维全局平均池化函数。
18、优选地,所述根据语义属性一致性损失、提示属性一致性损失、交叉熵损失和去偏损失计算分类模型优化的总损失包括:
19、
20、其中,lsa为语义属性一致性损失、lpac为提示属性一致性损失、lcls为交叉熵损失、ldeb为去偏损失、l为优化总损失;attention_scores,v、分别为视觉实例引导的全局语义解码器和提示实例引导的局部语义解码器中的注意力分数,gmp表示一维全局最大池化函数,zc为该类的属性向量,表示向量二范数的平方,αs、αu分别为可见类和不可见类预测相似度分数的均值,βs、βu分别为可见类与不可见类预测相似度分数的方差,λc、λcls和λdeb为加权系数。
21、优选地,所述根据优化后的分类模型计算所给图像与不可见类别的属性的相似度分数,输出图像对应的预测标签包括:
22、计算不可见类别的分数:
23、
24、输出相似度分数最高的类别的预测标签
25、
26、其中,γ是用来平衡训练时可见类与不可见类分数的校准系数,fi(·)是一个指示函数,如果则该函数值为0,否则为1,其中yu表示不可见类的标签集合;y为需要预测的标签集合。
27、根据本发明的另一个方面,本发明还提供了一种基于提示引导的零样本图像分类系统,所述系统包括:
28、计算模块,用于根据全局语义表示、实例提示表示和实例视觉表示计算得到增强视觉表示;将融合了语义信息的增强视觉表示投影至语义属性空间,计算得到与所有类别的属性的相似度分数;
29、优化模块,用于根据语义属性一致性损失、提示属性一致性损失、交叉熵损失和去偏损失计算分类模型优化的总损失,将所述总损失作为优化目标,优化分类模型的参数;
30、分类模块,用于根据优化后的分类模型计算所给图像与不可见类别的属性的相似度分数,输出图像对应的预测标签,实现零样本图像的分类。
31、优选地,所述计算模块根据全局语义表示、实例提示表示和实例视觉表示计算得到增强视觉表示包括:
32、从数据集中获得可见类的实例图像、对应可见类的属性向量和共享属性的全局语义描述,通过属性向量获得对应的文本化实例提示;
33、将全局语义描述和实例图像对应的实例提示输入到文本编码器中,得到全局语义表示和实例提示表示;将实例图像输入到视觉编码器的前l-1层,得到实例视觉表示;
34、将全局语义表示和实例视觉表示送入语义视觉跨模态融合模块中的视觉实例引导的全局语义增强解码器,得到增强全局语义表示;
35、将增强全局语义表示和实例提示表示输入到语义视觉跨模态融合模块中的提示实例引导的局部增强语义增强解码器,得到局部增强后的局部增强语义表示;
36、将实例视觉表示和局部增强语义表示输入到语义视觉跨模态融合模块中的局部增强语义引导的视觉解码器中,获得增强视觉表示。
37、将增强视觉表示输入到视觉编码器的最后一层编码层进行编码得到编码结果;
38、对所述增强视觉表示的编码结果、全局语义表示和实例提示表示进行融合配对,得到增强视觉表示。
39、优选地,所述计算模块将融合了语义信息的增强视觉表示投影至语义属性空间,计算得到所有类别的属性的相似度分数包括:
40、利用余弦相似度评估所给图像与每个类的属性向量的相似度分数:
41、
42、其中,为分类任务的候选标签,z为需要分类类别的属性向量的集合,τ为缩放因子,x为实例图像,为增强视觉表示,wp为全连接层,gap为一维全局平均池化函数。
43、优选地,所述优化模块根据语义属性一致性损失、提示属性一致性损失、交叉熵损失和去偏损失计算分类模型优化的总损失包括:
44、
45、
46、其中,lsac为语义属性一致性损失、lpac为提示属性一致性损失、lcls为交叉熵损失、ldeb为去偏损失、l为优化总损失;attention_scores,v、分别为视觉实例引导的全局语义解码器和提示实例引导的局部语义解码器中的注意力分数,gmp表示一维全局最大池化函数,zc为该类的属性向量,表示向量二范数的平方,αs、αu分别为可见类和不可见类预测相似度分数的均值,βs、βu分别为可见类与不可见类的预测相似度分数方差,λc、λcls和λdeb为加权系数。
47、优选地,所述分类模块根据优化后的分类模型计算所给图像与不可见类别的属性的相似度分数,输出图像对应的预测标签包括:
48、计算不可见类别的分数:
49、
50、输出相似度分数最高的类别的预测标签
51、
52、其中,γ是用来平衡训练时可见类与不可见类分数的校准系数,fi(·)是一个指示函数,如果则该函数值为0,否则为1,其中yu表示不可见类的标签集合;y为需要预测的标签集合。
53、有益效果:本发明引入了实例级别的文本化提示,弥补了语义提示下零样本图像分类任务中实例级别语义信息的缺失,为分类任务提供更多实例级别的语义信息。本发明利用提示实例引导的局部增强语义解码器带来了语义空间上的全局语义和实例语义信息的对齐,保证可见类知识的语义空间的转移。本发明利用提示引导的语义视觉跨模态融合模块完成了实例级语义信息和实例级视觉信息借助全局语义信息进行交互的任务,保证了实例级语义信息和实例级视觉信息可靠的跨模态交流,帮助细粒度的视觉信息与细粒度的语义信息对齐。本发明充分完成了语义视觉的融合,实现了可见类到不可见类语义、视觉知识的转移,在零样本图像分类的三个公开数据集上都取得优异的效果,在一些标注数据稀少的场景下有良好的实用性。
54、通过参照以下附图及对本发明的具体实施方式的详细描述,本发明的特征及优点将会变得清楚。
本文地址:https://www.jishuxx.com/zhuanli/20240929/310280.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。