一种弱监督视频异常检测方法
- 国知局
- 2024-10-09 14:36:05
本发明涉及视频异常检测,尤其是涉及一种弱监督视频异常检测方法。
背景技术:
1、视频异常检测(vad)旨在从未修剪的视频中检测出异常事件。该任务不仅能满足日常生活中日益增长的安全需求,而且能大幅度地解放人类的劳动,为构建智慧城市提供重要支持。由于异常事件具有稀疏性和不可预知性,人工筛选效率低下,既耗时又费力,并且可能因人类视觉疲劳而导致检测缺失,难以应对大规模的视频流。因此,采用深度学习算法自动检测视频中的异常事件具有十分重要的意义。
2、由于异常事件的稀疏性和多样性,以往的研究大多基于半监督设置,即采用单类别(one-class)分类范式,使用正常视频数据训练模型。这种方法假设模型能从正常视频中学习到正常模式,并将偏离这些正常模式的模式(patterns)判定为异常。然而,收集所有可能的正常事件来进行建模是不现实的。因此,这种对异常的判定方式过于理想化,忽略了正常事件的多样性。此外,所学习到的模型在表示能力和泛化能力之间难以找到合理的平衡点:若模型表示能力不足,则可能将未见过的正常事件错误地识别为异常;反之,若模型泛化能力过强,则可能导致将异常事件误判为正常。因此,在复杂场景中,这类方法的检测性能通常并不理想。而弱监督视频异常检测方法(ws-vad)通过在训练阶段引入视频级别标签和异常视频,采用多实例学习(mil)机制和排序损失来检测异常事件。这种方法使模型能够同时提取正常与异常事件的特征。因此,与半监督方法相比,这种方法更有效地检测视频中的异常事件。
3、弱监督方法中给出了视频级标签而没有给出异常实例的时间位置,目前大部分基于mil的视频异常检测方法都将视频视为包,视频中的各个片段视为包中的实例。其中,异常视频被视为正包,正常视频则被视为负包。该类方法通常假设正包中异常分数最大的实例最有可能是异常的,并通过扩大正包中最大异常分数的实例和负包中最大异常分数的正常实例之间的异常分数差距,使正包中最有可能是异常的实例能获得更大的异常分数。
4、尽管这种方法在训练中引入异常事件信息,但是现有基于mil的弱监督方法仍然存在一些问题。首先,现有方法大多使用时空视觉特征,比如3d convnet(c3d)或inflated3dconvnet(i3d)来提取视频的视觉特征,并利用这些视觉特征来进行视频异常检测。然而,在一些复杂场景中,异常事件可能在视觉上并不明显。以爆炸事件为例,若火焰仅占据画面的小部分或者被烟雾遮蔽时,场景中的视觉信息可能无法充分表达事件的完整语义。依赖单一的视觉特征往往难以获取视频中所有的高级语义信息,从而使得检测某些异常事件变得困难。此外,文本特征更强调获取那些视觉特征难以直接捕捉的抽象概念,为理解视频事件提供了一个新的视角。为了克服视觉特征的局限性,引入更适应表达事件语义的文本信息作为补充,是提升模型性能的关键步骤。chen等人借鉴视频字幕模型(video captioningmodel),提取包含丰富语义信息的文本特征,用以补充视觉特征,以提高弱监督视频异常检测任务的准确性和鲁棒性。虽然文本特征与视觉特征间存在相互补充信息,但二者间仍然在一定程度上存在信息冗余。在融合视觉和文本特征时,chen等人仅采用了简单的方法,如:拼接、相加和相乘。这种简单的特征级联方法并不能有效地建模两个模态之间的互补信息和相关性。文本特征与视觉特征虽然存在相互信息补充,还在一定程度上存在信息冗余。因此,将二者有效结合,将有助于模型在不同情境下保持鲁棒的性能表现。其次,视频由连续的片段组成,这些片段之间存在天然的时间依赖性。然而上述弱监督方法大多是依据单个片段内的特征差异对异常进行定位,对于片段之间的时间依赖性,特别是长期和短期的时序依赖性,探索仍然非常有限。这些片段之间的时间依赖性,对于检测出异常非常重要。此外,在损失函数中,基于mil的排序损失尽可能地扩大异常和正常视频中异常分数最大的片段之间的异常分数差异,以实现更好的检测性能。但是,异常事件往往由多个连续的异常片段构成,单纯地选择异常分数最大的实例作为排序损失的优化对象,可能导致在异常视频中漏检异常片段。并且,异常视频中经常包含大量正常片段的噪声,这同样会对模型训练优化造成干扰。
技术实现思路
1、本发明所要解决的技术问题是提供一种弱监督视频异常检测方法,该方法通过从竞争融合视觉-文本特征、挖掘片段之间的时间依赖以及增加异常片段和正常片段之间的区分度三个方面来提高视频异常检测的准确性以及增强视频异常检测的鲁棒性。
2、本发明所采用的技术方案是,一种弱监督视频异常检测方法,该方法包括下列步骤:
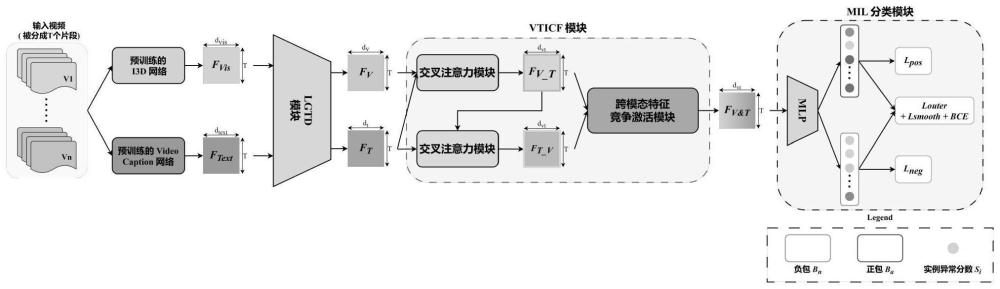
3、步骤一、构建时序增强的视觉-文本竞争融合网络模型;所述的时序增强的视觉-文本竞争融合网络模型依次包括并行的视觉分支和文本分支、局部-全局时间依赖模块、视觉-文本信息竞争融合模块以及mil分类器;
4、步骤二、对所述时序增强的视觉-文本竞争融合网络模型进行训练,得到训练后的时序增强的视觉-文本竞争融合网络模型;
5、步骤三、将待检测的视频输入至所述的训练后的时序增强的视觉-文本竞争融合网络模型中进行视频异常检测;
6、其中,在步骤二中,所述的对所述时序增强的视觉-文本竞争融合网络模型进行训练的具体过程包括:
7、s1、给定输入视频v,所述的输入视频v的视频级标签为y,y∈{0,1};将所述的输入视频v分割成t个片段,即每个视频片段由vi表示;
8、s2、针对每一个所述的视频片段,将所述视频片段分别输入到视觉分支和文本分支,所述的视觉分支用于提取所述视频片段的视觉特征fvis,并将提取到的视觉特征fvis输出;所述的文本分支用于提取视频片段对应的文本特征ftext,并将提取到的文本特征ftext输出;
9、s3、将视觉分支的输出的视觉特征fvis以及文本分支输出的文本特征ftext分别输入到局部-全局时间依赖模块中进行处理,由所述局部-全局时间依赖模块输出局部-全局时间依赖视觉特征fv以及局部-全局时间依赖文本特征ft,其中,
10、s4、将所述的fv和ft同时输入视觉-文本信息竞争融合模块中进行融合,得到融合特征fv&t,其中,
11、s5、将所述的融合特征fv&t输入mil分类器中进行片段级异常分数预测,得到视频的片段异常分数集合s={s1,s2,…,st},其中,si表示第i个视频片段的异常分数;
12、s6、利用损失函数计算所述mil分类器的训练损失,并通过梯度反传训练所述mil分类器,得到训练后的mil分类器;
13、s7、采用下一个输入视频,返回步骤s1进行循环,直至得到训练后的时序增强的视觉-文本竞争融合网络模型。
14、本发明的有益效果是:采用上述一种弱监督视频异常检测方法,该方法通过视觉-文本信息竞争融合模块(vticf)来聚合视觉和文本二者的互补信息,并采用竞争机制减少二者的信息冗余,来更好地捕获视频的高级语义,获得具有判别性的语义信息。并且,建立了一个局部-全局时间依赖模块(lgdt)来对视频片段之间的短期和长期时间依赖进行建模,并调整片段内部的信息权重,最后利用损失函数还对mil分类器进行训练;该方法能够提高视频异常检测的准确性以及增强视频异常检测的鲁棒性。
15、作为优选,在步骤s3中,所述的局部-全局时间依赖模块依次包括多尺度时序特征融合模块、多头自注意力模块以及senet模块;所述的将视觉分支输出的视觉特征fvis输入到局部-全局时间依赖模块中进行处理的具体过程包括下列步骤:
16、s3.1、在多尺度时序特征融合模块中,使用卷积核大小为s的一维卷积对视觉特征fvis进行卷积运算,其表示为:fvis(s)=conv1d(s)(fvis);其中,s∈{3,7},conv1d(s)(·)表示卷积核大小为s的一维卷积操作,fvis(s)表示视觉特征fvis在时间维度上应用一维卷积后的输出特征,通过卷积运算提取到视觉特征fvis(3)以及视觉特征fvis(7);
17、s3.2、将视觉特征fvis(3)、视觉特征fvis(7)以及原始视觉特征fvis进行融合,得到多尺度时序融合特征fvis_l,
18、s3.3、将所述的多尺度时序融合特征fvis_l输入多头自注意力模块中,首先通过三个全连接层将fvis_l转换成查询q、键k以及值v;其中,以及然后将q、k以及v分别划分为qc、kc以及vc;其中,以及接着由多头自注意力模块分别计算每个头的自注意力oc,其表达式为:oc=sa(qc,kc,vc);随后将得到的每个头的自注意力结果合并,得到最终输出特征fvis_lg:fvis_lg=mhsa(fvis_l)=concat(o1,...,oh);其中,
19、s3.4、将所述输出特征fvis_lg送入senet模块中进行片段特征权重调整;具体为:首先是squeeze操作,对输出特征fvis_lg进行全局平均池化,其中的每个片段特征用一个常量表示,然后是excitation操作,通过线性映射先降维后升维,学习片段特征的重要程度,即获得片段特征的权重w,w∈rt;最后是scale操作,将注意力权重w与fvis_lg相乘得到最后的特征输出fv,
20、作为优选,在步骤s4中,所述的将所述的fv和ft同时输入视觉-文本信息竞争融合模块中进行融合的具体过程包括下列步骤:
21、s4.1、将所述的fv和ft送入第一交叉注意力机制中,由第一交叉注意力机制将文本信息嵌入到视觉特征中,其具体过程为:
22、s4.01、将所述的fv和ft分别映射为查询qv以及键kt和值vt,表示为:其中,和表示可学习的线性投影参数;
23、s4.11、计算文本特征和视觉特征的交叉注意力分数,并应用残差连接,得到融合文本语义的视觉特征fv_t,表示为:其中,dvt表示qv和kt的特征维数;
24、s4.2、将视觉特征fv_t输入第二交叉注意力机制中,由第二交叉注意力机制再次将视觉特征fv_t嵌入至文本特征中,其具体过程为:
25、s4.02、将ft和fv_t输入第二交叉注意力机制,并通过相似的映射过程,将ft和fv_t分别映射为查询qt以及键kvt和值vvt,其表示为:其中,和表示可学习的线性投影参数;
26、s4.12、计算ft和fv_t的交叉注意力分数并应用残差连接,得到融合视觉信息的文本特征ft_v,其表示为:其中,dtv表示qt和kvt的特征维数,
27、s4.3、采用跨模态特征动态竞争激活机制来动态权衡视觉信息和文本信息的相对重要性,通过聚合不同特征中的信息以形成最终的融合文本语义的视觉特征fv_t以及最终的融合视觉信息的文本特征ft_v,所述最终的融合文本语义的视觉特征fv_t表示为:
28、所述最终的融合视觉信息的文本特征ft_v表示为:
29、其中,特征的通道数为t,特征维度为dvt,
30、视觉-文本信息互补增强特征表示为:其中:(fivt)d=φd,(fitv)d=θd,max(,)代表最大化激活操作。
31、作为优选,在步骤s6中,所述的损失函数表示为:其中,μ和σ均表示权重;bce(s,y)表示异常分数集合s与标签集合y之间的二值交叉熵损失;louter表示top-k包外损失函数,kmax(s)表示视频片段的异常分数集合s中异常分数si最大的k个元素的集合,和分别表示异常视频的片段异常分数和正常视频中的片段异常分数;linner表示k-maxmin包内损失函数,linner=lpos+lneg,lpos表示k-maxmin正包内损失函数,kmin(s)视频片段的异常分数集合s中异常分数si最小的k个元素的集合,lneg表示k-maxmin负包内损失函数,lsmooth表示平滑损失函数,
32、作为优选,所述的将待检测的视频输入至所述的训练后的时序增强的视觉-文本竞争融合网络模型中进行视频异常检测的具体过程为:将待检测的视频输入至所述的训练后的时序增强的视觉-文本竞争融合网络模型中,由训练后的mil分类器预测待检测的视频中所有视频片段的异常分数,设定一个阈值,根据阈值划分每个视频片段的类型,即异常分数大于阈值的视频片段为异常片段,异常分数小于阈值的视频片段为正常片段。
本文地址:https://www.jishuxx.com/zhuanli/20241009/305809.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。