一种用于计算机软件开发的数据处理系统和方法与流程
- 国知局
- 2024-10-09 15:09:26
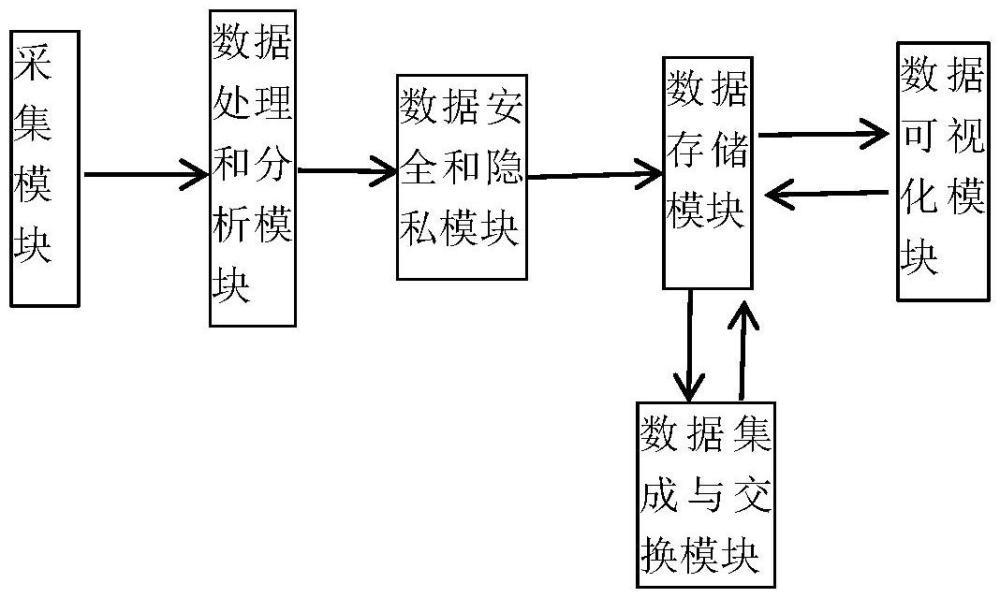
本发明涉及数据处理,尤其涉及一种用于计算机软件开发的数据处理系统和方法。
背景技术:
1、计算机软件开发的数据处理系统是指通过计算机软件来对数据进行采集、存储、处理、分析和展示的系统。随着信息技术的发展和数据量的急剧增加,数据处理系统在各个领域得到广泛应用,包括企业管理、科学研究、医疗保健、金融服务等。
2、在申请号为cn2022104803795《一种用于计算机软件开发的数据处理系统》的专利中,公开了一种用于计算机软件开发的数据处理系统,包括以下模块构成:数据收集模块、数据传输模块、数据储存模块、可视化监控模块;所述可视化监控模块定时执行查询数据储存模块的占用空间、剩余空间、运行温度等sql语句,将查询出来的结果通过显示屏展示给运维人员。该用于计算机软件开发的数据处理系统,通过可视化监控模块,在数据处理系统运行时,维护人员只需查看显示屏便可知悉数据储存服务器的占用空间、剩余空间、运行温度等数据。上述专利中的一种用于计算机软件开发的数据处理系统存在以下不足:
3、整体系统虽然使运维人员能够注意到重要的维护信息,实现了便于维护的目的,但是整体系统在进行数据处理和分析上并未阐述具体,尤其对于计算机软件开发过程中,数据去除重复数据、处理数据缺失值和纠正数据错误等方面,并未展现。
技术实现思路
1、本发明的目的是为了解决现有技术中存在的缺点,而提供了一种用于计算机软件开发的数据处理系统,包括:
2、数据采集模块,用于从第一数据库中选择适合数据需求的数据源,以确定数据需求,并根据所述数据需求通过数据提取工具对需求数据进行结构化分类和非结构化分类,以得到提取分类数据,其中,所述数据源包括数据库类型、文件类型、传感器类型、api接口类型和网络爬虫类型在内的数据来源;
3、数据存储模块,用于将所述提取分类数据存储到第二数据库内,并根据适用场景将所述提取分类数据划入到所述第二数据库中的关系型数据库和非关系型数据库内;
4、数据处理与分析模块,用于在所述数据存储模块将所述提取分类数据存储过程中,对所述提取分类数据进行处理和分析操作得到第一处理数据,以及对所述第一处理数据进行转换和格式化操作得到第二处理数据,其中,所述处理和分析操作包括去除重复数据、处理数据缺失值和纠正数据错误在内的操作,所述转换和格式化操作包括数据的转换、合并和拆分在内的操作;
5、数据可视化模块,用于根据确定可视化的类型、格式和内容将所述数据源通过tabl eau工具创建交互式图表,并测试可视化效果,根据测试反馈的效果对所述交互式图表进行优化和改进;
6、数据安全与隐私模块,用于所述第二数据库对所述提取分类数据进行安全风险评估,根据评估结果将所述提取分类数据分为敏感类数据和非敏感类数据,并对所述敏感类数据进行加密处理,同时设置访问控制机制,其中,所述访问控制机制确保授权用户能够访问和操作数据;
7、数据集成与交换模块,用于所述数据存储模块确定对需求数据进行结构化分类和非结构化分类过程中统一数据格式和结构,即通过ta l end和kafka工具对不同数据源的数据进行清洗和转换,将所述第二数据库内的数据进行集成,确保数据在不同系统内之间进行交换和共享。
8、优选地,在数据采集模块中,所述根据所述数据需求通过数据提取工具对需求数据进行结构化分类和非结构化分类,进一步包括:
9、通过数据提取工具apachen i f i从所述数据源中提取出所述需求数据,提取过程中对所述需求数据进行预处理,其中所述预处理是对于非结构化数据,进行文本清洗、分词和词性标注,对于结构化数据,进行数据类型转换和数据清洗;
10、结构化分类和非结构化分类是结构化数据根据数据类型和数据结构进行分类,非结构化数据根据文本内容和数据格式进行分类。
11、优选地,在所述数据存储模块中,所述根据适用场景的不同分别划入到关系型数据库和非关系型数据库内,进一步包括:
12、所述关系型数据库,根据所述第二处理数据的数据结构和关系选择数据库模型为mysql模型;在所述mysql模型中创建相应的所述第二数据库和表,并定义表结构和字段类型,将所述需求数据从所述数据源中导入到所述第二数据库内;
13、所述非关系型数据库,根据所述第二处理数据的数据特点和应用场景选择数据库模型为hbase模型,在所述hbase模型中创建相应的所述第二数据库和集合,并定义数据结构和索引,将所述需求数据从所述数据源中导入到所述第二数据库内。
14、优选地,在数据处理与分析模块,所述处理和分析操作,进一步包括:
15、对所述提取分类数据进行特征处理,提取所述提取分类数据的特征和属性,并根据选定的特征导入到机器学习算法中进行训练,以实现识别和去除重复数据,其中,所述特征处理包括所述提取分类数据的时间特征、文本特征、图像特征、数值特征和类别特征在内的特征;
16、通过ta l end工具识别所述提取分类数据中的缺失值,并根据缺失值的类型和分布情况选择删除缺失值和填充缺失值,根据数据删除或填充后的数据集建立机器学习模型进行训练,由此对所述第二数据库中数据进行删除缺失值和填充缺失值处理;
17、对所述提取分类数据进行所述特征处理,提取所述提取分类数据的特征和属性,选定已知的正确数据导入到机器学习算法中进行训练,便于模型学习出正确的数据纠正规则,以实现对数据进行错误纠正。
18、优选地,在数据处理与分析模块,所述转换和格式化操作,进一步包括:
19、根据数据特点、转换、合并和拆分目标对所述第一处理数据进行特征提取得到提取特征,同时选择深度学习模型对所述提取特征进行数据训练得到训练数据,训练好后对所述训练数据进行转换、合并和拆分得到所述第二处理数据;
20、其中,所述特征提取包括数据数值、数据类别、文本特征和时间序列。
21、优选地,所述通过tab l eau工具创建交互式图表,进一步包括:
22、将所述数据源与所述tab l eau工具连接,并导入所述需求数据中的可视化数据;
23、在工作表界面选择适合数据展示的图表类型,并将数据集中的字段拖拽到图表的“行”和“列”的区域,根据需要调整字段的顺序和设置,并通过添加按钮对图标进行图标信息调整;
24、用户通过点击“显示工作表”或“显示仪表板”按钮来预览图表的可视化效果,查看图表的交互功能和效果;
25、根据预览的效果和反馈,对图表进行优化和改进,所述对图表进行优化和改进包括图表的布局、颜色和标签。
26、优选地,所述通过添加按钮对图标进行图标信息调整,进一步包括:
27、添加筛选器,用户根据需要选择不同的数据维度和度量;
28、添加参数,用户可自由调整图表中参数;
29、添加工具提示,通过添加工具提示可以显示所述可视化数据的详细信息和说明;
30、添加动画效果,通过添加动画效果可以让所述可视化数据的进行变化。
31、优选地,在数据安全与隐私模块中,所述用于所述第二数据库对所述提取分类数据进行安全风险评估,根据评估结果将所述提取分类数据分为敏感类数据和非敏感类数据,进一步包括:
32、明确定义敏感数据,所述敏感数据包括个人身份信息、财务信息、健康信息在内涉及隐私和安全的数据;
33、绘制所述第二数据库的数据地图,标识出所有数据表和字段,以及数据表和字段之间的关系;
34、通过识别所述字段的特定字段和数据类型来对所述第二数据库中的所述提取分类数据进行分类,划分为所述敏感类数据和非敏感类数据;
35、审查和分类数据库用户的权限,确保只有授权用户可以访问所述敏感类数据。
36、优选地,一种用于计算机软件开发的数据处理方法,包括以下步骤:
37、s1:从第一数据库中选择适合数据需求的数据源,以确定数据需求,通过数据提取工具提取需求数据,且对所述需求数据统一数据格式和结构,并通过所述数据提取工具进行结构化分类和非结构化分类,以得到提取分类数据,其中,所述数据源包括数据库类型、文件类型、传感器类型、api接口类型和网络爬虫类型在内的数据来源;
38、s2:第二数据库对所述提取分类数据进行安全风险评估,根据评估结果将所述提取分类数据分为敏感类数据和非敏感类数据,并对所述敏感类数据进行加密处理,同时设置访问控制机制,其中,所述访问控制机制确保授权用户能够访问和操作数据;
39、s3:根据所述访问控制机制在所述提取分类数据存储过程中,对所述提取分类数据进行处理和分析操作得到第一处理数据,以及对所述第一处理数据进行转换和格式化操作得到第二处理数据,其中,所述处理和分析操作包括去除重复数据、处理数据缺失值和纠正数据错误在内的操作,所述转换和格式化操作包括数据的转换、合并和拆分在内的操作;
40、s3:将所述第二处理数据存储到所述第二数据库内,并根据适用场景将所述提取分类数据划入到所述第二数据库中的关系型数据库和非关系型数据库内;
41、s4:根据所述关系型数据库和所述非关系型数据库确定可视化数据的类型、格式和内容,并将所述第二数据库的可视化数据通过tab l eau工具创建交互式图表,并测试可视化效果,根据测试反馈的效果对所述交互式图表进行优化和改进。
42、与现有技术相比,本发明的有益效果是:
43、1)本发明通过数据提取工具将需要的数据进行结构化分类和非结构化分类避免了手动提取数据的繁琐和耗时过程,提高了数据提取的效率,实现了多种数据类型的提取和分类,满足不同数据需求,适用于大数据环境下的数据提取需求。
44、2)本发明通过适用场景的不同分别划入到关系型数据库和非关系型数据库,能够确保数据的一致性,适用于需要强一致性和数据完整性的场景,且适用于需要进行复杂查询和数据分析的场景,同时能够实现高可扩展性,适用于需要处理大规模数据和高并发访问的场景,以及数据结构不固定或频繁变化的场景。
45、3)本发明通过机器学习模型可以自动识别重复数据、处理缺失值和纠正数据错误,减少了人工处理的工作量,且提高了数据的处理效率,机器学习模型可以根据不同的数据特点和处理需求进行调整和优化,具有较强的可扩展性,且适用于各种类型的数据处理任务;
46、4)本发明通过深度学习模型能够自动学习数据之间的关系和模式,从而自动进行数据的转换、合并和拆分操作,减少了人工干预的需求,且可以处理大规模数据,快速地进行数据的转换、合并和拆分,提高了处理效率和准确性;
47、5)本发明通过tab l eau提供直观的用户界面和拖放式操作,使得用户可以轻松创建交互式图表,无需专业的编程技能,且用户可以快速创建各种类型的图表,并实时查看效果,同时使得用户可以与图表进行互动,探索数据的不同维度和关系,并根据反馈对图表进行优化和改进,提升可视化效果和吸引力;
48、6)本发明通过将数据库内的数据分为敏感类和非敏感类,有助于更精准地识别和评估数据安全风险。通过对敏感数据进行重点关注和保护,可以有效减少数据泄露和滥用的风险;对敏感数据实施更严格的访问控制、加密和监控,能够有效防范潜在的安全威胁;通过对数据库内的数据进行分类,可以更有效地分配安全资源和投入,避免资源浪费和降低安全成本。
本文地址:https://www.jishuxx.com/zhuanli/20241009/307856.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表