应用于FPGA加速器的PME算法异构计算方法及装置
- 国知局
- 2024-10-09 15:18:16
本发明涉及分子动力学模拟,尤其涉及一种应用于fpga加速器的pme(粒子网格ewald)算法异构计算方法及装置。
背景技术:
1、分子动力学(md)模拟方法是用于模拟分子运动的常用方法,以获得分子体系的各种化学和物理特性。在分子体系中,分子内和分子间存在各种不同类型的力,其中静电力是非键相互作用力的重要组成部分。随着模拟体系分子规模的增大,计算静电力所消耗的计算资源也在迅速的增加。为了减少静电力的计算量,逐步发展了一系列的方法,其中pme方法是计算静电力的主流方法。
2、在pme方法下,模拟体系的静电势能分为三个部分,分别是实空间的静电势能、傅里叶空间的静电势能,以及能量修正项pme算法pme算法。通过选择合适的ewald系数,可以使实空间的静电势能快速收敛,进而可以采用截断的方式来处理实空间的静电势能。能量修正项本身的计算量不大,所以整个pme算法中最耗时的是计算傅里叶空间的静电力。
3、异构计算系统是指使用不同类型指令集和体系架构的计算单元组成系统,如cpu和fpga、cpu和gpu组成的异构计算系统。由cpu完成任务的分配和调度,fpga或gpu完成具体的计算任务,进而提升计算的效率。为了提升pme算法的计算效率,可以将傅里叶空间的静电力计算卸载到fpga或gpu中,cpu只做管理和调度,从而提升pme算法的计算速度。
4、目前基于异构系统的pme算法主要是cpu+gpu的架构,相较之下,基于cpu+fpga架构的pme算法还不够成熟。openmm是一个用于分子动力学模拟的开源工具包,具有高度的可扩展性、灵活性和高性能特点,主要用于计算蛋白质、药物和其他生物分子的电子结构、动态和热力学性质。openmm支持纯cpu计算和cpu+gpu的异构计算,尚不支持cpu+fpga的异构计算。
5、目前基于异构系统的pme算法主要是cpu+gpu的架构,openmm是一个用于分子动力学模拟的开源工具包,主要用于计算蛋白质、药物和其它生物分子的电子结构、动态和热力学性质。pme算法是openmm工具包中一个重要的算法,用于计算长程静电力,其中fft计算又是pme算法的重要组成部分。目前openmm支持纯cpu计算和cpu+gpu的异构计算,尚不支持cpu+fpga的异构计算。现有技术中也存在将pme算法移植到fpga中进行计算,但存在使用hbm作为存储器导致的在pme计算过程中数据存取延时长,以及多维fft计算过程中转置和卷积单独处理导致的存储资源占用多、计算时间长的问题。
技术实现思路
1、本发明通过提供一种应用于fpga加速器的pme算法异构计算方法,解决了现有技术中在使用hbm作为存储器导致的在pme计算过程中数据存取延时长,以及多维fft计算过程中转置和卷积单独处理导致的存储资源占用多、计算时间长的问题,实现了将pme算法卸载到fpga中,以此提升pme算法的计算速度。
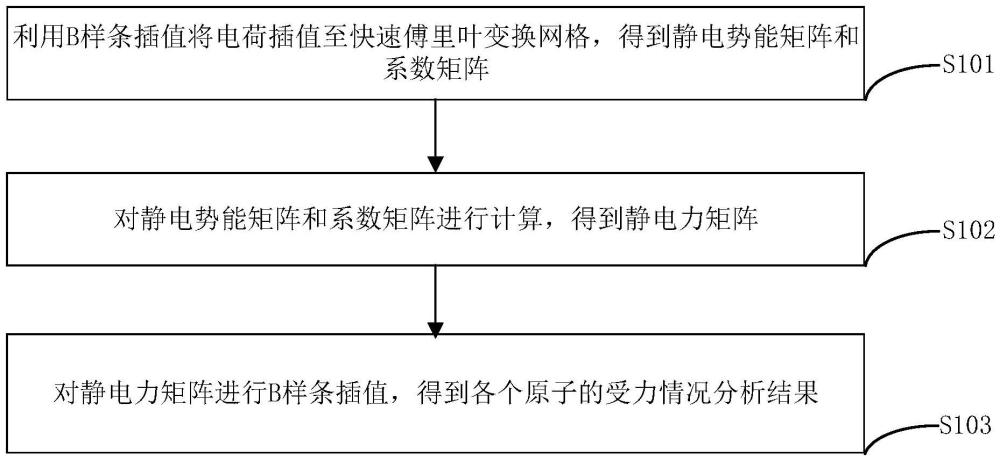
2、第一方面,本发明提供了一种应用于fpga加速器的pme算法异构计算方法,该方法包括:
3、利用b样条插值将电荷插值至快速傅里叶变换网格,得到静电势能矩阵和系数矩阵;
4、对所述静电势能矩阵和所述系数矩阵进行计算,得到静电力矩阵;
5、对所述静电力矩阵进行b样条插值,得到各个原子的受力情况分析结果。
6、结合第一方面,在一种可能的实现方式中,所述利用b样条插值将电荷插值至快速傅里叶变换网格,得到静电势能矩阵和系数矩阵的操作发生在cpu中。
7、结合第一方面,在一种可能的实现方式中,所述对所述静电势能矩阵和所述系数矩阵进行计算,得到静电力矩阵,包括:
8、通过直接内存访问引擎访问主机内存,得到所述静电势能矩阵和所述系数矩阵;
9、利用fpga加速器对所述静电势能矩阵和所述系数矩阵进行三维快速傅里叶变换计算、卷积计算和三维快速傅里叶逆变换,得到静电力矩阵。
10、结合第一方面,在一种可能的实现方式中,所述利用fpga加速器对所述静电势能矩阵和所述系数矩阵进行三维快速傅里叶变换计算、卷积计算和三维快速傅里叶逆变换,得到静电力矩阵,包括:
11、对所述静电势能矩阵先进行x维傅里叶变换,得到x维傅里叶变换结果;
12、将所述x维傅里叶变换结果进行数据处理,将处理结果进行y维傅里叶变换,得到y维傅里叶变换结果;
13、对所述维傅里叶变换结果进行z维傅里叶变换,得到z维傅里叶变换结果;其中,所述x维傅里叶变换结果、y维傅里叶变换结果和z维傅里叶变换结果均为复数;
14、根据所述z维傅里叶变换结果和所述系数矩阵进行相乘,得到傅里叶变换结果;
15、对所述傅里叶变换结果进行z维傅里叶逆变换,得到z维傅里叶逆变换结果;
16、对所述z维傅里叶逆变换结果进行y维傅里叶逆变换,得到y维傅里叶逆变换结果;
17、对所述y维傅里叶逆变换结果进行数据处理,将处理结果进行x维傅里叶逆变换,得到静电力矩阵。
18、结合第一方面,在一种可能的实现方式中,所述数据处理,包括:
19、对输入的数据先进行转置,再将转置后的数据进行拼接,得到数据处理结果。
20、结合第一方面,在一种可能的实现方式中,所述x维傅里叶变换结果、所述y维傅里叶变换结果、所述z维傅里叶变换结果、所述傅里叶变换结果、所述z维傅里叶逆变换结果、所述y维傅里叶逆变换结果和所述静电力矩阵均在所述fpga中进行保存。
21、结合第一方面,在一种可能的实现方式中,所述对所述静电势能矩阵和所述系数矩阵进行计算,得到静电力矩阵发生的操作在fpga中。
22、第二方面,本发明提供了一种应用于fpga加速器的pme算法异构计算装置,该装置包括:cpu和fpga;所述cpu和所述fpga利用高速串行计算机扩展总线连接;
23、所述cpu用于利用b样条插值将电荷插值至快速傅里叶变换网格,得到静电势能矩阵和系数矩阵;
24、所述fpga用于对所述静电势能矩阵和所述系数矩阵进行计算,得到静电力矩阵;
25、所述cpu还用于对所述静电力矩阵进行b样条插值,得到各个原子的受力情况分析结果。
26、结合第二方面,在一种可能的实现方式中,所述fpga加速器包括:计算单元、全局内存单元;
27、所述计算单元利用变换计算模块、卷积计算模块、数据处理模块进行数据的变换卷积计算,并利用数据加载模块用于完成所述全局内存单元中的全局内存和所述变换计算模块和所述卷积计算模块中本地内存之间的数据交互;
28、所述全局内存单元存储所述cpu下发的所述静电势能矩阵、所述系数矩阵和所述静电力矩阵。
29、本发明中提供的一个或多个技术方案,至少具有如下技术效果或优点:
30、(1)本发明通过将pme算法中计算耗时的傅里叶变换、卷积计算和傅里叶逆变换放到fpga加速器中实现,保留插值计算在主机中处理。主机与加速器之间的数据传输为静电势能矩阵、系数矩阵,以及静电力矩阵;
31、(2)本发明通过主机首先下发静电势能矩阵和系数矩阵到fpga加速器的全局内存中,并通过指令告诉加速器开始计算任务。加速器中的计算单元从全局内存取出数据存入本地内存,计算单元中各个变换计算核和卷积计算核从各自本地内存中取出数据完成三维傅里叶变换、卷积计算和三维傅里叶逆变换,最后得到静电力矩阵并存回全局内存中。加速器通过中断信号告诉主机计算任务完成,主机从加速器的全局内存中取回数据;
32、(3)存储由全局内存和本地内存构成,本地内存又分为静电势能本地内存和系数矩阵本地内存,静电势能本地内存为真双端口ram,系数矩阵本地内存为简单双端口ram。在多次三维快速傅里叶变换、快速傅里叶逆变换过程中,数据的存取在本地内存中进行,数据的存取速度快。
本文地址:https://www.jishuxx.com/zhuanli/20241009/308269.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。