一种基于多尺度学习的半监督实例分割方法、系统及存储介质
- 国知局
- 2024-10-09 15:28:01
本发明涉及计算机视觉中的图像分割领域和机器学习中的半监督学习领域,是半监督学习和实例分割的结合任务,具体涉及一种基于多尺度学习的半监督实例分割方法、系统及存储介质。
背景技术:
1、实例分割的任务设置是对于图片中所有的实例输出像素级别的分割预测。目前,基于直接分割的实例分割方法在速度和性能上取得了很大的提升。半监督学习是通过部分有标签图片和大量的无标签图片来训练模型,通过无标签图片来进一步提升模型的性能。但是这些模型的训练都需要大量像素级别的标注信息,耗费较大。而半监督学习能够很好地缓解该问题。
2、目前,半监督学习基本的方法有两种:一致性学习的方法和伪标签的方法。最近的工作已经很好地将半监督学习结合进目标检测任务中,针对半监督实例分割任务,目前有一篇工作构建了一个多阶段的框架,通过增加一个更抗噪声的掩膜分支和保留掩膜边缘信息的权重来更好地利用无标签图片的信息去提升半监督实例分割的性能。还有一篇有着目前最优性能的工作构建了一个端到端的框架,设计的损失函数能够根据不同伪标签的质量动态调整分类损失和掩膜损失的权重,这些权重是利用每个掩膜的像素级别的信息所学习得到的值。
3、在半监督实例分割的任务设定中,教师模型对无标签的图片进行推理产生伪标签,利用伪标签指导学生模型训练。所以,和图片真实的标签相比,仅在单一尺度下经由教师模型推理产生的伪标签不可避免地会出现在像素级和分类级的噪声,导致伪标签质量低,会影响半监督学习中一致性学习的收敛,从而限制模型实例分割性能的提升。
技术实现思路
1、针对现有技术存在的问题,本发明的目的在于提供一种基于多尺度学习的半监督实例分割方法、系统及存储介质,其通过引入额外下采样尺度的信息,并根据多尺度下生成的伪标签进行信息纠正和融合,提高伪标签的质量。
2、为实现上述目的,本发明采用的技术方案是:
3、一种基于多尺度学习的半监督实例分割方法,所述方法增设了多尺度伪标签纠正模块和面积适应的额外尺度学习策略;所述方法具体包括以下步骤:
4、步骤1、随机初始化学生模型和教师模型;
5、步骤2、将原始尺度的有标签图片输入学生模型得到预测结果;
6、步骤3、通过有标记图片的标签和预测结果进行计算损失函数;
7、步骤4、对原始尺度和下采样0.5倍尺度的无标记图片进行弱数据增强,从教师模型中获取弱增强的无标记图片的预测结果,最终得到原始尺度下的伪标签以及下采样0.5倍尺度下的伪标签;
8、步骤5、将原始尺度下的伪标签和下采样0.5倍尺度下伪标签输入进多尺度伪标签纠正模块,得到优化后的伪标签;
9、步骤6、对原始尺度下的无标签图片进行强数据增强,将经过强增强的无标记图片输入到学生模型得到预测结果;
10、步骤7、将学生模型对于原始尺度下强增强图片的预测结果和优化后的伪标签计算无标记图片的损失函数;
11、步骤8、对下采样0.5倍尺度下的无标签图片进行强数据增强,将经过强增强的无标签图片输入到学生模型得到预测结果;
12、步骤9、将优化后伪标签下采样至对应尺度得到,将学生模型对于下采样0.5倍尺度下强增强图片的预测结果和利用面积适应的额外尺度学习策略计算无标签图片的损失函数;
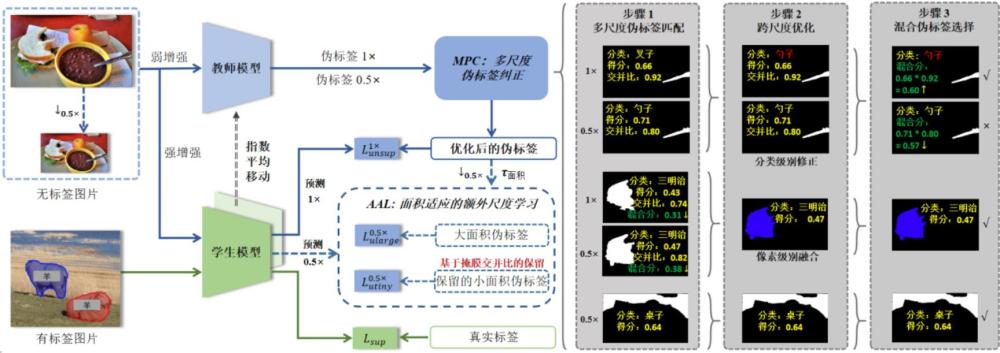
13、步骤10、将步骤2、步骤6和步骤8得到的损失值加权求和得到总损失,以梯度回传算法训练学生模型;
14、步骤11、通过ema方法对多个时间步中的学生模型进行集成,更新教师模型的参数;
15、步骤12、重复步骤2至步骤11,不断训练学生模型和教师模型实例分割的性能,直到预设的迭代次数结果;
16、步骤13、训练完成后,任意选择教师模型或者学生模型对于输入的图片进行推理预测,得到实例分割的结果。
17、所述步骤3中,损失函数计算如下:
18、(1)
19、其中,是分类计算的交叉熵损失,是掩膜计算的dice损失。
20、所述伪标签和分别包含了掩膜和、分类标签和、分类置信度和、iou得分和;
21、所述步骤5中,原始尺度下的伪标签和下采样0.5倍尺度下伪标签输入进多尺度伪标签纠正模块后,伪标签纠正模块的处理包含了三个步骤:多尺度伪标签匹配、跨尺度优化和混合伪标签选择;
22、步骤5.1、多尺度伪标签匹配;
23、首先,给定原始尺度下伪标签中的第i个掩膜与下采样0.5倍尺度下伪标签中的所有掩膜进行比较,以找到最大iou的第j个下采样尺度下的伪标签,从而在两个尺度中找到匹配的掩膜对;
24、如果最大交并比大于阈值,则视为两个尺度下的预测掩膜指向同一个实例,形成的配对;
25、对于没有形成配对的伪标签则进行保留,在原始尺度有而下采样尺度没有的伪标签记为;在下采样尺度中有而原始尺度没有的伪标签记为;
26、步骤5.2、跨尺度优化;
27、对于步骤5.1中形成的掩膜配对,在伪标签和中对应有分类标签对和分类置信度对;首先在分类级别对伪标签进行优化,即将置信度较低的分类类别修正为另一个尺度下预测的分类得分较高的分类类别;
28、有掩膜配对,对应也有的iou得分对;接下来,通过分类置信度和iou得分相乘计算混合得分来评估伪掩模的质量;当两个尺度的伪标签掩膜的混合得分都低于阈值时,选择融合多尺度的掩膜信息,得到优化后的掩膜级伪标签;
29、步骤5.3、混合伪标签选择;
30、对由多尺度伪标签组成的混合集合做选择性保留;有三种情况:
31、第一种是对于配对在第二步做过像素融合得到的,保留融合后的掩膜以及最高分类置信对应的类别作为分类标签,得到对应的伪标签;
32、第二种情况是对于配对没有做第二步像素融合的掩膜,这代表配对中的至少一个掩膜质量较高,它的综合得分大于阈值,选择保留那一个较高的伪标签,得到;
33、最后一种情况是在第一步中没有形成配对的伪标签和,全部保留,在伪标签数量的角度上进行补充;
34、最后,获得的优化后的伪标签记为:
35、(8)。
36、所述步骤5.1中,寻找最大iou的第j个下采样尺度下的伪标签表述为:
37、(2)
38、其中,( . )是将预测掩膜可能性进行二值化的函数;
39、所述步骤5.2中,对分类标签对和的修正表述为:
40、(3)
41、所述步骤5.2中,两个尺度的伪标签掩膜的混合得分计算如下:
42、(4)
43、(5)
44、所述步骤5.2中,优化后的掩膜级伪标签为:
45、(6)
46、所述步骤5.3中,伪标签为:
47、(7)。
48、所述步骤7中,损失函数计算如下:
49、(9)
50、其中,是分类计算的交叉熵损失,是掩膜计算的dice损失。
51、所述步骤9中,利用面积适应的额外尺度学习策略计算无标签图片的损失函数具体如下:
52、通过面积阈值将所有伪标签分为大面积伪标签和小面积伪标签,将小面积伪标签与下采样0.5倍尺度下的预测结果做二分图匹配,得到匹配结果后,计算小面积伪标签和与其对应匹配预测掩膜的iou,如果iou小于阈值,把该小面积伪标签丢弃,大于则保留;
53、大面积和保留的小面积伪标签将分别在额外的尺度监督学生模型,损失分别为和,公式如下:
54、(10)
55、(11)
56、(12)
57、其中,和分别是大面积和保留的小面积伪标签的数量;是下采样0.5倍尺度下模型的预测,是对应下采样的经过mpc优化后的伪标签,是掩膜计算的dice损失,是分类计算的交叉熵损失,是无监督的下采样分辨率下的总损失
58、所述步骤10中,总损失为:
59、(13)
60、其中,和是用于平衡损失项的超参数。
61、所述教师模型的参数更新如下:
62、(14)
63、其中,表示第n次迭代中的教师模型的参数,表示第n次迭代中的学生模型的参数,表示第n-1次迭代中的教师模型的参数,是一个超参数,用来调整ema的幅度。
64、一种基于多尺度学习的半监督实例分割系统,其包括存储器、处理器及存储在存储器上的计算机程序,所述处理器执行所述计算机程序以实现如上所述的一种基于多尺度学习的半监督实例分割方法的步骤。
65、一种计算机可读存储介质,其上存储有计算机程序/指令,所述计算机程序/指令被处理器执行时实现如上所述的一种基于多尺度学习的半监督实例分割方法的步骤。
66、采用上述方案后,本发明针对现有技术中训练过程的单一尺度下伪标签在像素级和分类级存在的噪声问题,设计了多尺度伪标签纠正模块,通过引入额外下采样尺度下生成的伪标签来提供信息结合的参考。具体而言,对于两种尺度下预测的分类标签的角度以及掩膜的角度进行互相参考和纠正,再通过综合得分确定最终应当保留的伪标签,从而很好地对单一尺度上的伪标签进行数量上的补充以及质量上的提优。除此之外,为了使得额外下采样尺度下伪标签的生成质量更高,本发明面积适应的策略在多尺度下训练模型,设计了面积适应的额外尺度学习策略。具体而言,为了解决小面积伪标签在下采样尺度下训练的不兼容问题,将伪标签依据掩膜面积分为小面积和大面积两部分,将小面积的伪标签和下采样尺度下的预测做二分图匹配,并计算掩膜的交并比。我们丢弃部分交并比较低的小面积伪标签,保留的小面积伪标签和所有大面积在下采样尺度下分别监督模型。
67、基于以上,本发明具有以下突出优点:
68、(1)本发明在半监督训练期间根据多尺度下生成的伪标签进行信息纠正和融合,优化出数量更多,质量更好的伪标签。
69、(2)本发明还设计了面积适应的额外尺度学习策略,通过在额外的尺度下让模型分别学习大面积以及根据预测情况保留的小面积伪标签,有效提升额外下采样下的模型对于伪标签学习的效果。
70、(3)本发明对coco、cityscapes和bdd100k数据集进行了广泛的实验,并得出本发明方法分别在 1%、2%、5%和10% 的设置下,在coco数据集上以23.4、26.7、30.7和33.0 map实现了最先进的性能。
本文地址:https://www.jishuxx.com/zhuanli/20241009/308822.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。