用于可听化的早期反射模式生成概念的制作方法
- 国知局
- 2024-10-09 15:40:45
本技术涉及用于可听化的早期反射处理概念。房间脉冲响应(rir)描述声学环境(房间)中的声源与接收方(即,收听者)之间的关系。rir指定房间对时域中的单位脉冲的响应,并且与频域中的房间传递函数相对应。rir由直接声音路径、早期反射(er)和扩散性后期混响组成。在用于虚拟和增强现实(vr/ar)应用的双耳(或扬声器)渲染中,来自特定源和收听者地点的房间脉冲响应可能显著地改变。在6自由度(6dof)vr/ar应用中,收听者通常可以在整个场景内自由地移动,从而产生永久性型改变的房间脉冲响应。因此,考虑到墙壁的几何形状、遮挡物和其他效应,必须花费大量的计算来确定从源到收听者的各反射,以计算物理上准确的反射模式。本发明的观察结果是,不需要房间中的早期反射(er)模式的精确声学再现来进行感知上有说服力的渲染,并且这可以以在很大程度上从房间的精确几何细节抽象的方式来进行。这样,可以节省很多计算。在反射模式必须从编码器传输到渲染器的情况下,与常规的基于几何形状的渲染中的现有技术相比,可以节省与根据收听者位置高效地计算反射相关联的辅助信息的相当大的一部分。文献[1]涉及用更一般的简单er模式来替代精确计算的“真实”er。其想法是找到、描述和模拟描述大房间(例如,音乐厅)的舞台上的小或大声源(例如,管弦乐队)的感知上正交的参数[2,3],并且通过扬声器设置(例如,立体声)对其进行重放或通过耳机对其进行双耳重放。作曲师或声音工程师能够使用这些参数(如源存在、源温暖、源亮度、房间存在、运行混响、包络和余响)来设置场景。spat软件已长时间用于这种产生[4]。该方法也在isompeg-4标准化中采用[5]。在动态6dof环境中,房间的声学描述(尺寸、rt60、…)可以变化相当大的量。源和接收方位置完全自由,并且将被实时地计算以用于可听化。高度依赖于这些改变的物理设置的感知参数不能被定义为常数,并且因此不适合于该任务。这里,本发明具有采用环境的仅几个基本物理参数来选择和调整简单的基本er模式的新方法。这具有以下优点:不需要特定的声音工程背景来定义参数。参数直接来自物理模型。所使用的简单er模式适应于不同的房间大小和不同的rt60值。甚至对于室外环境,也定义简单er模式,而在spat中情况并非如此。由于人类听觉系统不能分析早期反射的精细结构(例如,[6]),因此该方法相对于完全物理上正确的模拟的感知劣化受到限制。在以下的新发明的简单er模式中,使用房间声学参数(如rt60、预延迟时间、房间容积或房间尺寸、以及rt60的频率依赖性那样)。er模式被具体地定义为在直接声音和后期混响之间产生平滑过渡。er模式应是频率中性的,并且与至墙壁的接近度以及源和接收方的开口无关。想法是产生收听者的看似合理且有说服力的感知,从而适合整个房间声学参数。这对于大多数情况是足够的,因为收听者不具有与“真实”物理上精确的er的直接比较可能性。尤其是在如实时听觉虚拟环境和增强现实那样的应用中,可以避免尤其是具有可视性检查的er的计算消耗的精确几何计算。根据源和收听者的精确(和时变)地点,“真实”er的精确计算有时也是困难的并且对于通过使er出现和消失来产生伪影是敏感的。这可以通过使用恒定的er模式(其已在进入场景时被计算一次)来避免,或者通过从一个声学环境移动到由不同声学参数定义的另一环境来避免。本发明利用编码器-位流-渲染器情景。在一个情况(a)中,可以利用仅在渲染器中可用的房间声学参数来计算默认的简单er模式。这些参数通过源-收听者距离以及它们之间的方位角来实时地调整。在情况(b)中,在编码器中以更高级的方式预分析场景的几何形状。然后,在编码器中预计算几个er的简单er模式,并将该简单er模式在位流中传输到渲染器。此处,以与情况(a)中相同的方式通过收听者距离和角度(或在渲染时可用的其他信息)来调整简单er模式。这两个情况对于开放的不过时的方法给予了完全灵活性,其中进一步的分析知识可以稍后被并入到编码器中。动机房间脉冲响应(rir)描述声学环境(房间)中的声源与接收方(收听者)之间的关系,并且指定房间对单位脉冲的响应(例如,参见图21)。rir由直接声音路径、早期反射(er)和扩散性后期声音部分组成。图21示出利用声学房间模拟程序raven生成的具有二阶er的单音rir的示例[7]。尤其是在由许多表面限定的复杂物理环境/房间中,具有必要的可视性检查(“该源是否在到收听者的直接视线中?”)的几何正确的er的计算是非常耗时的。另一方面,已知人类听觉感知抑制了关于直接声音的与er有关的许多细节(第一波前定律、优先效应、场景分析、[8,9]),并且因此脉冲响应的er部分的确切模型化在许多情况下对于实现有说服力的渲染质量不是必要的(例如,[6])。听觉系统使用er来确定或细化数个感知属性。在这些感知属性中有:-源相对于接收方的位置-源-接收方距离-听觉源宽度(asw)-边界的电平(level)和频率依赖性吸收[10]-与接近边界的接近度
背景技术:
1、存在已知简化er计算的数个方法。第一方法是仅完全避免er的计算,即在无模拟er的情况下渲染声音,即仅渲染直接声音和后期混响(参见图22)。后期混响在所谓的预延迟时间开始。图22示出具有直接声音和在预延迟时间0.13s开始的后期混响的rir(无er)。
2、下一可能性是仅计算几何上精确的一阶反射(参见图23)。在鞋盒形房间中,这将er的数量从约27减少到6。图23示出具有一阶反射和后期混响的rir(左)、俯视图(右)。正方形(红色)是声源,圆形(蓝色)是接收方,连接圆形和正方形的线(红色)是直接声音,从圆形出来的更多线(蓝色)是反射,长度与对数电平成比例。
3、下一可能性是与直接声音并排的仅两个er(参见图24)。从音乐厅声学已知侧反射对asw的影响[11]。注意,这与真实几何模拟相比,计算起来非常简单。图24示出具有与直接声音并排的两个反射的rir(左)、俯视图(右)。
4、在下一模式中,两个侧反射被到直接声音的各侧的4次反射以及[±45°和±135°]处的四个固定源位置独立反射序列(各自由4次反射组成)替代(参见图25)。该模式受到spat算法[1,5]的启发,但是该模式不实现所有细节,尤其是不实现所有输入参数的效应。该模式所用的参数被定义为具体地产生如asw那样的感知接收方属性。除rt60之外,没有房间声学性质用于该模式。图25示出具有“spat”模式的rir(左)、俯视图(右)。十字形(绿色和蓝色)是er。
5、前面所述的方法被设计成使得定义er模式的输入参数是感知参数。这些感知参数应描述由er引起的收听者的感知。缺点是该方法仅模糊地适应于房间相关参数。声音工程知识和经验对于设置感知定义的参数(如源存在、源温暖、源亮度、房间存在、运行混响、包络和余响那样)是必要的。这对于定义实时vr/ar系统的物理性质并且不具有感知声音工程体验的设计者而言是明显的劣势。尤其对于vr应用,虚拟物理空间的几何形状作为可视化处理的副产物通常是众所周知的。此外,不存在利用spat算法已知的室外环境所用的er模式。
6、本发明的目的是通过明确地使用房间声学和物理参数以定义er模式来避免现有技术的缺点。此外,不同模式是根据房间性质定义的,并且甚至适合于室外环境(在室外环境中,几何形状的确切描述是困难的)。这些模式具有取决于房间大小或其他物理参数的不同数量的er。
7、新er模式的特征在于:
8、·与“真实”er相比的感知上看似合理的渲染
9、·与“真实”er计算相比的降低的计算复杂度
10、·取决于物理房间性质的er模式的适应
11、·不需要任何特定的声音工程技能和经验来设置所需的参数
12、·用于室内和室外的有区别的er模式
13、·在渲染器内计算预定义模式的情况下,(对于包括位流的传输的编码器/位流/渲染器情景)不需要附加辅助信息
14、·在编码器中根据场景几何形状计算预定义模式的情况下,(对于包括位流的传输的编码器/位流/渲染器情景)需要非常少的附加辅助信息。
15、这通过使用不取决于房间的精确几何形状的可参数化但固定的空间er模式来实现。在本发明的优选实施例中,模式也不取决于房间中的收听者位置。代替地,使用仅一个(或几个)全局特性参数来配置er模式。这样,可以极其高效地渲染模式。
16、在以下的新发明的er模式中,具体地使用房间声学参数(如rt60、预延迟时间、房间尺寸或房间容积、rt60对模式配置的频率依赖性那样)。er模式以在直接声音和后期混响之间产生(时间上)平滑过渡的方式来定义。er模式应是中性音色。er模式取决于房间容积和表面。er模式不取决于房间中的源和接收方的位置。
17、本发明的目的是产生收听者的似合理且有说服力的感知,从而适合整个房间声学参数。这对于大多数使用情况是足够的,尤其是由于收听者不具有与“真实”物理上正确的er的渲染进行直接比较的可能性。
技术实现思路
1、根据本发明的第一方面,本技术的发明人意识到,在尝试使用音频信号的早期反射(er)渲染时遇到的一个问题源于以下事实:早期反射取决于源位置和收听者位置之间的关系。发明人发现,可以在无例如地板反射的情况下考虑源位置独立的er模式;使得er渲染变得更容易,同时渲染结果仍很好。用于渲染的房间脉冲响应的早期反射部分由早期反射模式排他地确定。对于房间脉冲响应的早期反射部分,不考虑声源和收听者之间的空间关系。此外,早期反射模式中的早期反射位置相对于收听者头部朝向的变化是不变的。这基于以下发现:不论收听者看向声源还是任何其他方向,都可以使用相同的er模式来确定房间脉冲响应的早期反射部分。
2、因此,根据本技术的第一方面,用于声音渲染的设备被配置为接收与收听者位置和声源位置有关的信息。该设备被配置为使用房间脉冲响应来渲染声源的音频信号,所述房间脉冲响应的早期反射部分由早期反射模式排他地确定。早期反射模式指示群集,例如,群集应表示位置的集合,连同从连接位置的线之间的角度方面定义位置的相互放置;同义术语应是早期反射位置的“模式”。早期反射模式以如下的方式定位在收听者位置处,使得:早期反射位置围绕收听者位置并且以相对于收听者位置的角度方向进行定位,其中所述角度方向相对于收听者头部朝向的变化是不变的,即,群集平移地放置在收听者位置处。
3、根据本发明的第二方面,本技术的发明人意识到,在尝试使用音频信号的早期反射(er)渲染时遇到的一个问题源于以下事实:针对室外环境的早期反射模式是高度独立的并且取决于场景的物理设置。发明人发现,使用环境的适度分析所生成的er模式可以得到声学上有说服力但计算上适度的er渲染结果。
4、因此,根据本技术的第二方面,用于确定用于声音再现的早期反射模式的设备被配置为:通过在一个或多于一个分析位置中的各分析位置处进行以下操作来进行声学环境的几何分析:确定函数,该函数针对距各个分析位置的不同距离中的各距离,指示表示早期反射贡献的值;以及针对一个或多于一个极大值检查该函数或从该函数导出的另一函数,以导出一个或多于一个控制参数。另外,该设备被配置为通过使用一个或多于一个控制参数放置早期反射位置来确定早期反射模式,该早期反射模式指示早期反射位置的群集。
5、根据本发明的第三方面,本技术的发明人意识到,在尝试使用音频信号的早期反射(er)渲染时遇到的一个问题源于以下事实:用于渲染的音频场景的早期反射模式的传输可能导致高信令成本。发明人发现,可以通过使用位流提示来生成er模式,从而得到声学上有说服力但计算上适度的er渲染结果。通过仅使用位流中的提示,由于不需要传输完整的er模式,因此可以降低信令成本。
6、因此,根据本技术的第三方面,用于声音渲染的设备被配置为接收与收听者位置和声源位置有关的第一信息。该设备被配置为接收包括例如定位在声源位置处的声源的音频信号的表示以及一个或多于一个早期反射模式参数的位流,并从位流中读取该音频信号的表示以及该一个或多于一个早期反射模式参数。例如,位流是音频位流(在该位流的头部或元数据字段内部具有早期反射参数)、或者文件格式流(在该文件格式流的分组和该文件格式流的轨道(包括表示音频信号的音频位流)内部具有早期反射参数)。另外,该设备被配置为根据一个或多于一个早期反射模式参数来确定指示早期反射位置的群集的早期反射模式。此外,该设备被配置为使用房间脉冲响应来渲染声源的音频信号,所述房间脉冲响应的早期反射部分由早期反射模式确定。早期反射模式指示群集,例如,群集应表示位置的集合,连同从连接位置的线之间的角度方面定义位置的相互放置;同义术语应是早期反射位置的“模式”。早期反射模式以如下的方式定位在收听者位置处,使得:早期反射位置围绕收听者位置并且以相对于收听者位置的角度方向进行定位,其中所述角度方向相对于收听者头部朝向的变化是不变的,即,群集平移地放置在收听者位置处。
7、根据本发明的第四方面,本技术的发明人意识到,在尝试使用音频信号的早期反射(er)渲染时遇到的一个问题源于以下事实:考虑到墙壁的几何形状、遮挡物和其他效应,必须花费大量的计算来确定从源到收听者的各反射,以计算物理上准确的反射模式。发明人发现,简单的房间声学参数(如房间尺寸、房间容积或预延迟那样)可以用于确定早期反射模式内的早期反射位置的数量。由于可以根据房间声学参数来近似早期反射,因此不需要分析场景的真实早期反射。发明人发现,通过er数量对房间声学参数的依赖性的er模式生成得到声学上有说服力但计算上适度的er渲染结果。
8、因此,根据本技术的第四方面,用于确定用于声音再现的早期反射模式的设备被配置为接收表示声学环境的声学特性的至少一个房间声学参数。该设备被配置为以如下的方式确定指示早期反射位置的群集的早期反射模式,使得:多个早期反射位置取决于至少一个房间声学参数。
9、根据本发明的第五方面,本技术的发明人意识到,在尝试使用音频信号的早期反射(er)渲染时遇到的一个问题源于以下事实:各源与不同的早期反射模式相关联。发明人发现,不需要针对不同源的信号使用不同的er模式。这是基于如下的想法:可以根据源收听者关系对信号进行加权和求和,使得仅基于er模式来渲染音频信号的加权和。发明人发现,通过将er模式用于多于一个声源的er再现得到声学上有说服力但计算上适度的er渲染结果。
10、因此,根据本技术的第五方面,用于声音渲染的设备被配置为接收与收听者位置、第一声源位置和第二声源位置有关的信息。该设备被配置为使用房间脉冲响应来渲染两个声源的音频信号,所述房间脉冲响应的早期反射部分由早期反射模式确定。早期反射模式指示群集,例如,群集应表示位置的集合,连同从连接位置的线之间的角度方面定义位置的相互放置;同义术语应是早期反射位置的“模式”。早期反射模式以如下的方式定位在收听者位置处,使得:早期反射位置围绕收听者位置并且以相对于收听者位置的角度方向进行定位,其中所述角度方向相对于收听者头部朝向的变化是不变的,即,群集平移地放置在收听者位置处。该设备被配置为通过形成定位在第一声源位置处的第一声源的第一音频信号和定位在第二声源位置处的第二声源的第二音频信号的加权和来渲染两个声源的音频信号。如果第一声源位置和收听者位置之间的第一距离小于第二声源位置和收听者位置之间的第二距离,则加权和以第一音频信号的权重多于第二音频信号的权重的方式进行加权,并且如果第一距离大于第二距离,则加权和以第二音频信号的权重多于第一音频信号的权重的方式进行加权。另外,该设备被配置为通过从早期反射位置渲染加权和以生成与房间脉冲响应的早期反射部分相关的早期反射贡献扬声器信号,来渲染两个声源的音频信号。
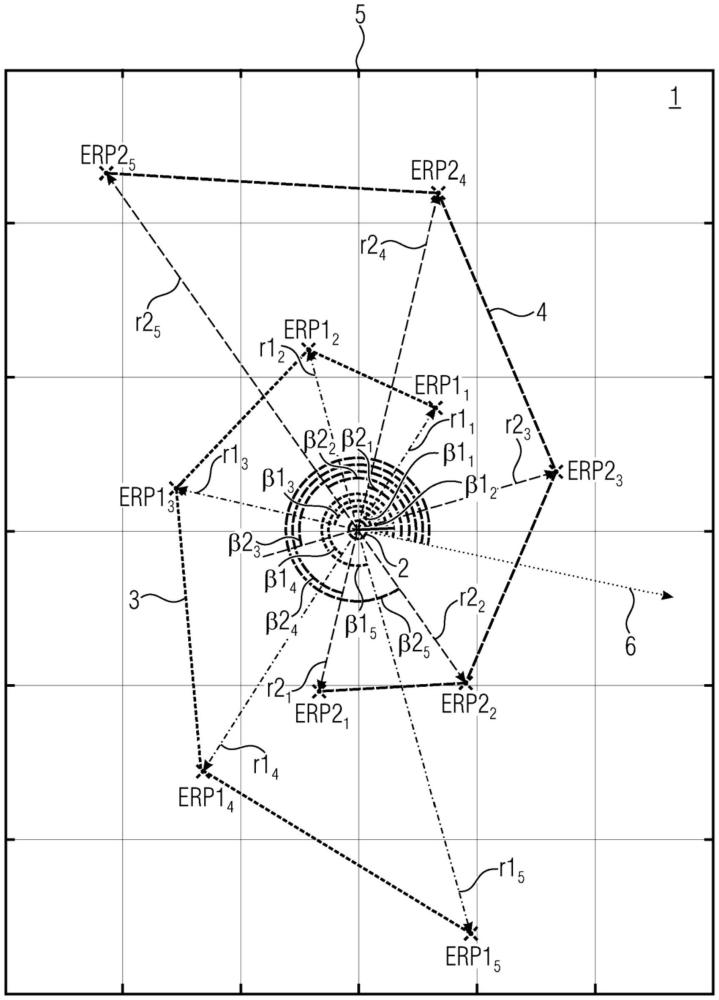
11、根据本发明的第六方面,本技术的发明人意识到,在尝试使用音频信号的早期反射(er)渲染时遇到的一个问题源于以下事实:考虑到墙壁的几何形状、遮挡物和其他效应,必须花费大量的计算来确定从源到收听者的各反射,以计算物理上准确的反射模式。发明人发现,简单的房间声学参数(如房间尺寸、房间容积或预延迟那样)可以用于对定义早期反射的位置的函数进行参数化。由于可以根据房间声学参数来近似早期反射,因此不需要分析场景的真实早期反射。此外,发现了螺旋函数提供早期反射位置的良好分布。发明人发现,使用一个或多于一个螺旋函数的er模式生成得到感知上有说服力但计算上适度的er渲染结果。
12、因此,根据本技术的第六方面,用于确定用于声音再现的早期反射模式的设备被配置为接收表示声学环境的声学特性的至少一个房间声学参数,并通过对以收听者位置为中心的一个或多于一个螺旋函数进行参数化、并且使用一个或多于一个螺旋函数放置早期反射位置来确定指示早期反射位置的群集的早期反射模式。
本文地址:https://www.jishuxx.com/zhuanli/20241009/309591.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表