一种基于文本向量化的文本分类系统的制作方法
- 国知局
- 2024-10-21 14:42:19
本发明涉及文本主题分类,尤其涉及一种基于文本向量化的文本分类系统。
背景技术:
1、在信息爆炸的时代,传统的基于规则和统计学的文本分类技术,这些技术大多依赖人工特征工程,不仅耗时费力,且难以适应语言表达的多样性和灵活性。
2、中国专利公开号cn105045812a公开了一种文本主题的分类方法及系统。本发明中,文本主题的分类方法,包含以下步骤:采集语料;其中,语料包含各个主题类型的文本;对语料进行分词,并对分词后的语料进行文本特征提取,得到各主题类型文本的特征向量;根据动态对数激励函数调整各主题类型文本的特征向量中的特征值,得到新的各主题类型文本的特征向量;根据待分类文本与新的各主题类型文本的特征向量的相似度,对待分类文本进行分类,确定待分类文本的主题类型。这样,使得对文本分类更准确;由此可见,该方案在对待分类文本进行分类时,仅针对相似度进行分析,存在文本分类准确率低的问题。
技术实现思路
1、为此,本发明提供一种基于文本向量化的文本分类系统,用以克服现有技术中文本分类准确率低的问题。
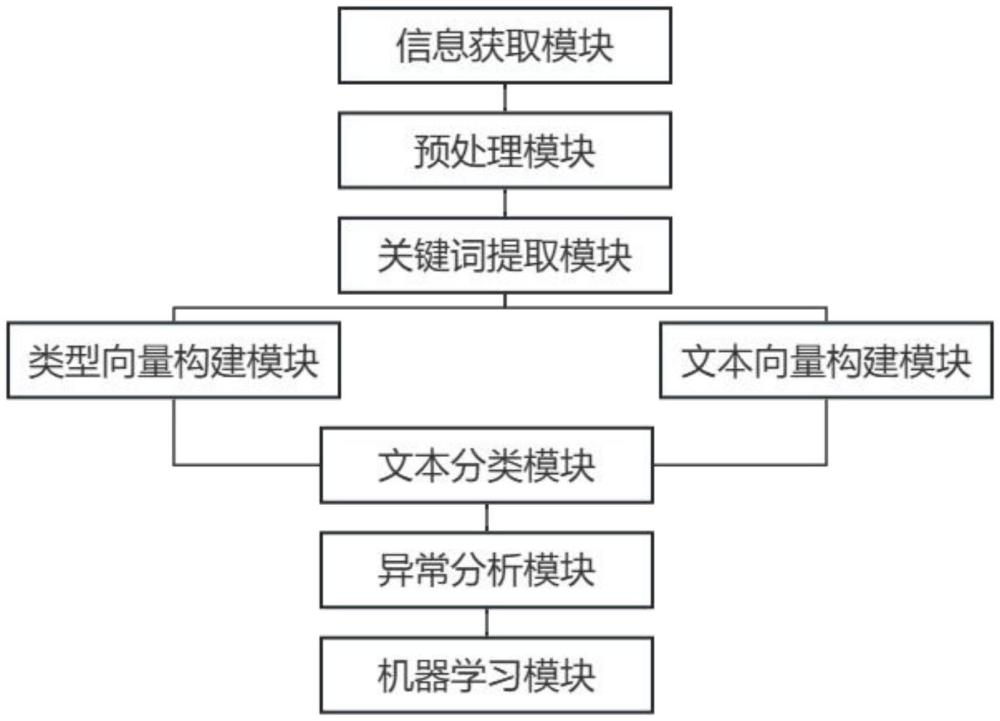
2、为实现上述目的,本发明提供一种基于文本向量化的文本分类系统,所述系统包括,
3、信息获取模块,用以获取各主题类型文本与待分类文本;
4、关键词提取模块,用以对预处理后的各主题类型文本进行主题类型关键词提取;
5、类型向量构建模块,用以根据各主题类型关键词的提取结果对各主题类型文本的特征向量进行构建;
6、文本向量构建模块,用以对预处理后的待分类文本进行待分类文本主题类型关键词提取,还用以根据提取结果对待分类文本的各主题类型特征向量进行构建;
7、文本分类模块,用以根据待分类文本的各主题类型特征向量与各主题类型文本特征向量的构建结果对待分类文本进行主题类型分类;
8、异常分析模块,用以根据待分类文本主题类型的分类结果对待分类文本分类的异常性进行分析;
9、机器学习模块,用以根据监测周期内待分类文本分类异常性的分析结果与待分类文本的数量对下一监测周期待分类文本的主题类型分类过程进行优化。
10、进一步地,所述关键词提取模块设有词频分析单元和关键词提取单元,所述词频分析单元用以对预处理后的各主题类型文本的词频进行分析,并将第i主题类型中第j个词的词频设为pij,设定:
11、
12、所述词频分析单元将第i主题类型中各词的词频按照从大到小的顺序进行排序,并将第α×ji个词的词频记为b;
13、当pij≤b时,所述词频分析单元判定第i主题中第j个词为无效词;
14、当pij>b时,所述词频分析单元判定第i主题中第j个词为第i主题类型预选词;
15、其中,pijk为第i主题类型中第j个词在第i主题类型中第k个文本出现的次数,ki为第i主题类型中文本的数量,ji为第i主题类型文本中词的数量。
16、进一步地,所述关键词提取单元根据各主题类型文本词频的分析结果对各主题类型文本的关键词进行提取,所述关键词提取单元将第i主题类型文本第m个预选词的tf-idf值设为qim,设定:qim=tfi(m)×lg{(ki+1)/[dfi(m)+1]};
17、所述关键词提取单元将第i主题类型文本中预选词的tf-idf值按照从大到小的顺序进行排序,并选取tf-idf值前n的预选词作为第i主题类型关键词;
18、其中,tfi(m)为第i主题类型文本第m个预选词在第i主题类型文本中出现的次数与第i主题类型文本中词数量的比值,dfi(m)为第i主题类型文本中包含第i主题类型文本第m个预选词的文本数量,0<m≤mi,mi为第i主题类型文本中预选词的数量,n为预设筛选数量。
19、进一步地,所述类型向量构建模块根据各主题类型关键词的提取结果对各主题类型文本的特征向量进行构建,所述类型向量构建模块将第i主题类型文本特征向量设为tzi,并将tzi的第n个元素设为qin,qin为第i主题类型中第n个关键词的tf-idf值,0<n≤n。
20、进一步地,所述文本向量构建模块设有文本分析单元和文本向量构建单元,所述文本分析单元用以将待分类文本与各主题类型关键词进行匹配,并根据匹配结果对待分类文本主题类型关键词进行提取,其中:
21、当第i主题类型中第n个关键词与待分类文本匹配时,所述文本分析单元将其作为待分类文本的i主题类型关键词;
22、当第i主题类型中第n个关键词与待分类文本不匹配时,所述文本分析单元不将其作为待分类文本的i主题类型关键词。
23、进一步地,所述文本向量构建单元用以根据待分类文本各主题类型关键词的提取结果对待分类文本的第i主题类型特征向量dti进行构建,其中:
24、当第i主体类型中第n个关键词与待分类文本不匹配时,所述文本向量构建单元将dti的第n个元素设为dti(n),设定dti(n)=0;
25、当第i主体类型中第n个关键词与待分类文本匹配时,所述文本向量构建单元将dti的第n个元素设为dti(n)’,设定dti(n)’=dtfi(n)×lg{(ki+1)/[dfi(n)+1]};
26、其中,dtfi(n)为第i主题类型第n个关键词在待分类文本中出现的次数与待分类文本中词数量的比值,dfi(n)为第i主题类型文本中包含第i主题类型第n个关键词的文本数量。
27、进一步地,所述文本分类模块将待分类文本的第i主题类型特征向量与第i主题类型文本特征向量进行相似度计算,并根据计算结果对待分类文本进行主题类型分类,所述文本分类模块将待分类文本第i主题类型特征向量与第i主题类型文本特征向量的相似度设为l(i),设定:
28、l(i)=tzi·dti/(|tzi|×|dti|);
29、所述分类模块将待分类文本各主题类型特征向量与各主题类型文本特征向量的相似度按照从大到小的顺序进行排序,并将相似度最大的主题类型文本特征向量的主题类型作为待分类文本的主题类型;
30、其中,|tzi|为向量tzi的模,|dti|为向量dti的模。
31、进一步地,所述异常分析模块根据第i主题类型特征向量与第i主题类型文本特征向量的相似度的计算结果对待分类文本分类的异常性进行分析,其中:
32、当(l1-l2)/l1≤r时,所述异常分析模块判定当前待分类文本的分类异常;
33、当(l1-l2)/l1>r时,所述异常分析模块判定当前待分类文本的分类正常;
34、其中,l1为待分类文本各主题类型特征向量与各主题类型文本特征向量相似度排序第一的相似度,l2为待分类文本各主题类型特征向量与各主题类型文本特征向量相似度排序第二的相似度。
35、进一步地,所述机器学习模块设有分类优化单元和优化调整单元,所述分类优化单元用以根据监测周期内分类异常的待分类文本数量q0与待分类文本的数量q1对分类异常率z0进行计算,设定z0=q0/q1,并将分类异常率与预设异常率z1进行比对,根据比对结果对下一监测周期待分类文本的主题类型分类过程进行一次优化,其中:
36、当z0≤z1时,所述分类优化单元判定当前监测周期分类异常率正常,不进行优化;
37、当z0>z1时,所述分类优化单元判定当前监测周期分类异常率异常,并对下一监测周期待分类文本的主题类型分类过程进行一次优化,将优化后的预设筛选数量设为n’,设定n’=n×[1+sin(z0-z1)×(π/2)]。
38、进一步地,所述优化调整单元用以将监测周期内待分类文本的数量q1与预设数量q进行比对,并根据比对结果对下一监测周期待分类文本的主题类型分类过程进行二次优化,其中:
39、当q1≤q时,所述优化调整单元判定当前监测周期待分类文本的数量异常,并对下一监测周期待分类文本的主题类型分类过程进行二次优化,将优化后的预设异常率设为z1’,设定:
40、z1’=z1×{1+[(q-q1)/q]exp{cos[(q-q1)/q]}};
41、当q1>q时,所述优化调整单元判定当前监测周期待分类文本的数量正常,不进行优化。
42、与现有技术相比,本发明的有益效果在于,所述关键词提取模块通过设置预设调整系数以提高主题类型预选词筛分的准确性,进而提高了类型关键词提取的效率,通过对各主题类型文本的关键词进行筛选以提高各主题类型文本特征向量构建的准确性,通过设置预设筛选数量提高了各主题类型文本特征向量构建的效率,所述类型向量构建模块通过关键词的tf-idf值构建各主题类型文本特征向量构建以提高各主题类型文本特征向量构建的效率,所述文本向量构建模块通过构建不同主题类型的待分类文本特征向量以提高待分类文本的各主题类型特征向量与各主题类型文本特征向量相似度计算的准确性,所述文本分类模块通过计算余弦相似度的方法以提高待分类文本的各主题类型特征向量与各主题类型文本特征向量相似度计算的效率,从而提高了文本分类的效率,进而提高了文本分类的准确性,所述异常分析模块通过设置预设异常比例以提高待分类文本分类异常性分析的准确性,从而提高了文本分类的效率,进而提高了文本分类的准确性,所述机器学习模块通过设置预设异常率以提高类型关键词提取的效率,通过设置预设数量以提高类型关键词提取的效率,从而提高了各主题类型文本特征向量构建的准确性,最终提高了文本分类的准确性。
本文地址:https://www.jishuxx.com/zhuanli/20241021/319039.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。