一种基于LSTM-SCS缺资料山区洪水过程智能预报方法
- 国知局
- 2024-10-21 15:01:18
本发明涉及一种基于lstm-scs缺资料山区洪水过程智能预报方法。
背景技术:
1、山区洪水流速快、流量大与暴涨暴落的特点导致了山洪灾害突发性强、破坏力大。同时,山区小流域情况复杂,影响因素多,加上水文观测基础设施建设落后,水文观测资料缺少,加大了山区水文预报的难度。我国西部地区和东部山区的地面观测匮乏,严重制约了这些地区的洪水预报精度。目前,山区洪水预报方法可概括为三类:基于分布式水文模型的山洪过程预报(简称分布式水文模型)、基于临界雨量阈值的山洪预警与人工智能预报,其中基于临界雨量阈值的山洪预警依赖于通过水位/流量反推法、比拟法和水动力学法来获取小流域临界雨量,缺少产流机制的描述和分析,不能描述山洪灾害的全过程。分布式水文模型考虑了降水和下垫面的空间变异性,可以更好地利用地理信息系统gis、遥感技术获取的空间信息来描述从降雨到径流的过程机理,但分布式水文模型将流域划分为很多响应单元反映时空变异性,响应单元内部参数是变化的,因而必然会产生误差。人工智能预报是目前新兴的方法,机器学习是人工智能的基本实现途径,从数据中寻求输入输出的关系,更好得拟合非线性的径流序列,但缺点是需要较大的训练数据集,一般山区小流域数据偏少,不足以支撑模型的训练。
技术实现思路
1、本发明所要解决的技术问题是提供一种基于lstm-scs缺资料山区洪水过程智能预报方法。
2、本发明一种基于lstm-scs缺资料山区洪水过程智能预报方法的技术方案是这样实现的:一种基于lstm-scs缺资料山区洪水过程智能预报方法,依次包括如下步骤:
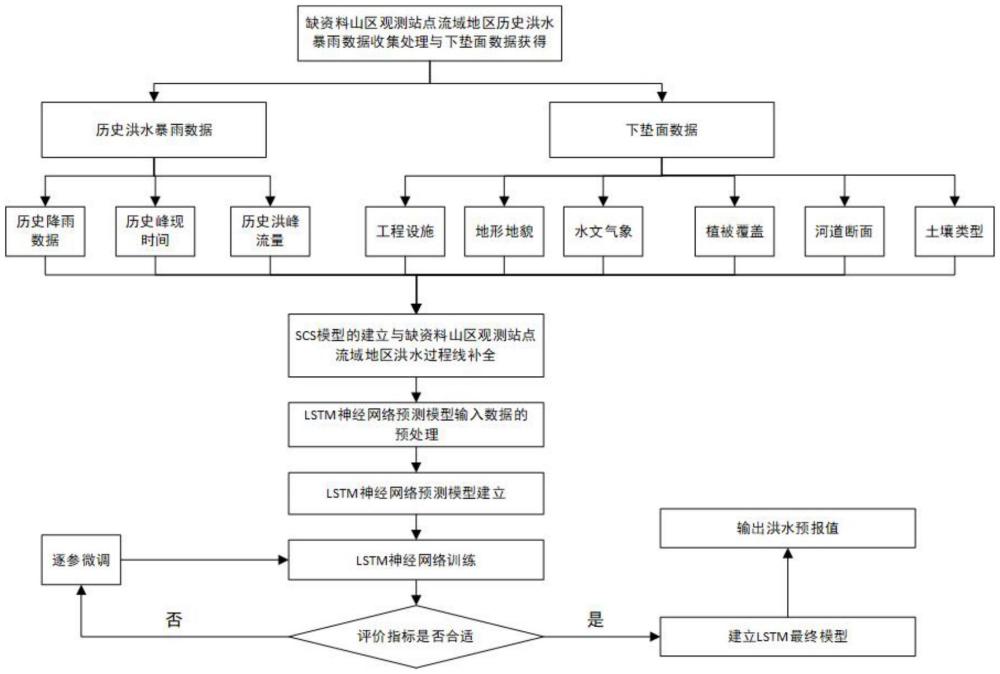
3、(1).缺资料山区观测站点流域地区历史洪水暴雨数据收集处理与下垫面数据获得
4、①.缺资料山区观测站点流域地区历史洪水暴雨数据收集处理:收集缺资料山区观测站点流域地区至少持续24小时的至少12场次洪水的历史洪水暴雨数据,所述历史洪水暴雨数据包括历史降雨数据、历史洪峰流量与历史峰现时间;所述缺资料山区观测站点流域地区如无降雨实测数据,则采用周边观测站点流域地区降雨实测数据进行插补,得到缺资料山区观测站点流域地区按时间间隔为小时、按时间先后依次排列的至少持续24小时的至少12场次洪水的历史降雨数据;根据所述缺资料山区观测站点流域地区洪痕推算出所述缺资料山区观测站点流域地区所述至少持续24小时的至少12场次洪水的历史洪峰流量;根据记载记录明确所述缺资料山区观测站点流域地区所述至少持续24小时的至少12场次洪水的历史峰现时间;基于arcgis对所述缺资料山区观测站点流域地区的dem数据进行填洼处理和流向分析,并且分析汇流累积量,对河网进行提取和分级,分割流域盆地之后得到流域盆地以及河流水系的计算图层分析数据,根据计算图层分析数据建立栅格河网数据;
5、②、缺资料山区观测站点流域地区下垫面数据获得:根据缺资料山区观测站点流域地区工程设施、地形地貌、水文气象、植被覆盖、河道断面和土壤类型资料,处理得到所述缺资料山区观测站点流域地区的下垫面数据;
6、(2).scs模型的建立与缺资料山区观测站点流域地区洪水过程线补全
7、①.scs模型的建立:a.根据邻近有资料山区观测站点流域地区的下垫面数据建立邻近有资料山区观测站点流域地区的scs模型;b.根据邻近有资料山区观测站点流域地区按时间间隔为小时、按时间先后依次排列的至少持续24小时的至少12场次洪水的历史流量数据和历史降雨数据率定调参得到适合的cn值以及单位线;c.将步骤(2)①b所述cn值和单位线与步骤(1)②所述缺资料山区观测站点流域地区的下垫面数据结合构建缺资料山区观测站点流域地区的scs模型;d.根据步骤(1)①所述缺资料山区观测站点流域地区的历史洪峰流量和历史峰现时间率定步骤(2)①b所述cn值和单位线;
8、②.缺资料山区观测站点流域地区洪水过程线补全:根据步骤(2)①所述缺资料山区观测站点流域地区的scs模型以及步骤(1)①所述缺资料山区观测站点流域地区的历史降雨数据,将步骤(1)①所述缺资料山区观测站点流域地区至少持续24小时的至少12场次洪水的历史洪峰流量与历史峰现时间的洪水过程线补全,得到缺资料山区观测站点流域地区按时间间隔为小时、按时间先后依次排列的至少持续24小时的至少12场次洪水的历史流量数据;
9、(3).lstm神经网络预测模型输入数据的预处理
10、步骤(1)①所述缺资料山区观测站点流域地区历史降雨数据中各场次洪水降雨数据按时间先后依次排列的7个降雨数据p1-p7构成各场次洪水单一降雨数据组,所述各场次洪水单一降雨数据组的p7时刻均具有对应步骤(2)②所述历史流量数据中各场次洪水流量数据的某一流量数据q;所述各场次洪水单一降雨数据组的p7时刻所对应所述某一流量数据q与各场次洪水单一降雨数据组中p1-p7依次排列构成各场次洪水单一降雨流量数据组;至少18个所述各场次洪水单一降雨数据组或各场次洪水单一降雨流量数据组按照所述数据组中p1的时间先后依次排列构成各场次洪水降雨数据组或各场次洪水降雨流量数据组;所述各场次洪水降雨流量数据组中排序的各场次洪水单一降雨数据组构成了各场次洪水时间序列数据集,采用max-min归一化将所述各场次洪水时间序列数据集中每个数据缩放在(0,1)作为各场次洪水lstm神经网络预测模型输入数据;
11、(4).lstm神经网络预测模型建立
12、初步拟定lstm神经网络模型的参数,包括隐含层数、隐含层节点数和epoch迭代次数,在标准lstm神经网络的基础上添加dropout神经网络的前向传播计算公式如公式(1)-(4)所示;将经过步骤(3)所述lstm神经网络预测模型输入数据预处理后的训练集与验证集各场次洪水数量总和的80%作为训练集、20%作为验证集;将所述训练集输入lstm模型中进行迭代训练,采用验证集对训练结果进行验证,直至预测误差满足预设标准,输出预测误差序列;
13、m(l)~bernoulli(p) (1)
14、y~(l)=r(l)*x(l) (2)
15、zi(l+1)=wi(l+1)y(~l)+bi(l+1) (3)
16、yi(l+1)=f(zi(l+1)) (4)
17、公式(1)-(4)中:m为随机掩码矩阵;l表示神经网络的层数索引,第l层表示当前层;对于神经网络,层是按顺序排列的,从输入层(通常表示为第0层)到输出层;p为保留率;y~(l)表示第l层经过丢弃操作后的输出;r(l)表示第l层的丢弃掩码,通常表示为0或1的向量;x(l)表示第l层的输入;zi(l+1)表示第l+1层第i个神经元的线性组合输入;wi(l+1)为连接第l层与第l+1层第i个神经元的权重向量;bi(l+1)表示第l层第i个神经元的偏置;yi(l+1)表示第l+1层第i个神经元的激活输出;f为门的激活函数;
18、(5).预测结果评价
19、将lstm-scs神经网络的洪水过程预测结果与bpnn-scs神经网络的洪水过程预测结果、gru-scs神经网络的洪水过程预测结果采用nse和r两个指标进行对比与分析,所述nse和r两个指标数值越高说明预测结果精度越高。
20、本发明所述缺资料山区是指易于得到历史洪水暴雨数据、但难以得到历史流量数据的山区;本发明所述有资料山区是指具有历史降雨数据与历史流量数据的山区。如无特别说明,本发明所述历史降雨数据是指按时间间隔为小时、按时间先后依次排列的至少持续24小时的至少12场次(实施例为13场)洪水的历史降雨数据;如无特别说明,本发明所述历史流量数据是指按时间间隔为小时、按时间先后依次排列的至少持续24小时的至少12场次(实施例为13场)洪水的历史流量数据;如无特别说明,本发明所述历史洪峰流量是指至少持续24小时的至少12场次(实施例为13场)洪水的历史洪峰流量;如无特别说明,本发明所述历史峰现时间是指至少持续24小时的至少12场次(实施例为13场)洪水的历史峰现时间。
21、本发明一种基于lstm-scs缺资料山区洪水过程智能预报方法步骤(2)中所述scs模型是由美国农业水土保持局(soil conservation service)针对小型流域研究的设计洪水模型,scs模型结构简单,参数较少。scs模型用于补充水文资料,对于缺乏实测洪水过程的洪水数据,仅有洪峰流量与峰现时间,可以基于scs模型修正洪水过程线获得实际洪水数据,作为山区中小流域洪水智能预报的输入数据集。scs模型的建立是根据水量平衡方程以及比例相等假设和初损值可能存在最大潜在滞留量关系两个假设条件,其公式如公式(5)-(6)所示:
22、
23、
24、公式(5)-(6)中:r为地表径流量;p为降雨总量;ia为初始损失量,即产生地表径流之前的降雨损失,如填洼和植被截留;s为流域当时的可能最大滞留量,是后损的上限;f为实际后损量;
25、土壤可能最大滞留量s在空间上分布不均,与土壤的类型、土地利用类型、管理策略以及坡度等数据资料有关,随着时间改变土壤水含量变化也会改变;scs模型中s的计算公式如公式(7)所示:
26、
27、公式(7)中:cn值无量纲,是一个综合参数,反映降雨前期流域特征,综合了前期土壤湿度、土地利用方式和土壤类型状况因素;
28、步骤(3)所述各场次洪水单一降雨流量数据组数据表现形式如表1如示:
29、表1各场次洪水单一降雨流量数据组数据表现形式
30、
31、表1中var1(t)与var8(t)表示p7时刻;var2(t-1)、var3(t-2)、var4(t-3)、var4(t-4)、var4(t-5)与var4(t-6)分别表示p7时刻前6小时、前5小时、前4小时、前3小时、前2小时与前1小时;
32、步骤(4)中山区各中小流域水文特征相似,在各流域进行洪水过程智能预报时,各中小流域参数设置可参考相同方案;步骤(4)中lstm神经元的三个门分别是遗忘门、输入门和输出门。所述遗忘门控制是否遗忘,以一定的概率控制在lstm中是否会遗忘上一层的隐藏细胞状态,选择遗忘信息;所述输入门是处理当前序列位置作为输入。所述遗忘门公式如公式(8)所示:
33、ft=σ(wf·[ht-1,xt]+bf) (8)
34、公式(8)中,ft是t时刻序列遗忘的信息;wf为遗忘门的系数权重矩阵;σ是relu激活系数;ht-1是上一序列lstm模块的隐藏状态输出;xt表示t时刻样本序列输入;bf是遗忘门的偏移项;
35、所述输入门公式如公式(9)-(10)所示:
36、it=σ(wi·[ht-1,xt]+bi (9)
37、
38、t时刻的cell状态(长时)方程如公式(11)所示:
39、
40、公式(9)-(11)中:it为输入门的激活值;σ为sigmoid激活函数;wi为输入门的权重矩阵;ht-1为前一时间步的隐藏状态;xt为当前时间步的输入;bi为输入门的偏置向量;c~t为候选记忆单元状态;tanh为双曲正切激活函数;wc为候选记忆单元状态的权重矩阵;bc候选记忆单元状态的偏置向量;ct为当前时间步的记忆单元状态;ft为遗忘门激活值;ct-1前一时间步的记忆单元状态;
41、所述输出门公式如公式(12)-(13)所示:
42、ot=σ(wo·[ht-1,xt]+bo) (12)
43、ht=ot·tanh(ct) (13)
44、公式(12)-(13)中:ot为t时刻序列输出门的输出;σ为relu激活系数;wo为输出门的系数权重矩阵;ht-1为上一序列lstm模块的隐藏状态输出;xt表示t时刻样本序列输入;bo为输出门的偏移项;ht为当前序列的lstm模块的隐藏状态输出;ct为t时刻序列的细胞状态;
45、σ(z)为sigmoid激活函数如公式(14)-(15)所示,tanh(z)为tanh激活函数如公式(16)-(17)所示:
46、
47、σ′(z)=σ(z)[1-σ(z)] (15)
48、
49、tanh′(z)=1-tanh2(z) (17)
50、公式(14)-(17)中:σ为sigmoid函数;z为神经元的输入值,即线性组合的结果;tanh为双曲正切函数;e为自然常数,基于自然对数的底数,约为2.71828;σ′(z)为sigmoid函数的导数,用于反向传播计算梯度;tanh′为tanh函数的导数,用于反向传播计算梯度;
51、相比于标准的神经网络,添加了dropout的神经网络相当于为前一层的输出向量添加了一道概率流程,即是否经过筛选;
52、步骤(5)中结果评价方法采用如公式(18)所示的nse和如公式(19)所示的r两个指标,采用所述nse和r指标评价模型,可以从模型模拟效果和拟合优度方面来评价模型效果;nse取值范围为(-∞,1),越接近1,表示预测效果越好;相关系数r度量自变量解释比例,反映回归方程拟合的优度;对模型拟合优度进行综合评价;r越接近1,说明用自变量来解释因变量值变化的部分所占比例越多,拟合效果就越好;
53、
54、公式(18)中:yi和y′i分别表示真实观测的数据和模拟的数据,表示对真实观测数据取均值,i表示第i个时刻,n表示总时段数;
55、
56、公式(19)中:yi和y′i表示真实观测的数据和模拟的数据;和表示真实观测的均值和模拟数据的均值;i表示第i个时刻;n表示总时段数。
57、本发明一种基于lstm-scs缺资料山区洪水过程智能预报方法建立的scs模型缺资料数据插补效果显著、具有预报精度高的特点。
本文地址:https://www.jishuxx.com/zhuanli/20241021/320199.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表