一种基于改进PPO算法的多AGV调度系统及其方法与流程
- 国知局
- 2024-11-06 14:47:33
本发明涉及agv调度,具体涉及一种基于改进ppo算法的多agv调度系统及其方法。
背景技术:
1、自动引导车(agv)系统在制造和仓库环境中进行路径规划时面临着重大挑战,这些环境通常具有高度的动态性和复杂性,需求包括避免碰撞和在有限空间内有效管理多个agv的运作。现有的agv调度系统大多依赖预设的路径和固定的操作规则,这在不断变化的环境中常常导致效率低下。此外,工厂和仓库的布局可能根据生产需求调整,需要调度系统能够实时响应这些变化,并有效地管理agv车辆以避免拥堵和碰撞。
2、深度神经网络,特别是通过强化学习训练的网络,为处理复杂的决策问题提供了强大的工具。在众多强化学习算法中,ppo(proximal policy optimization)算法特别适合于实时、动态的决策环境,如多agv调度系统。这种算法能够在保证学习稳定性的同时,优化长期奖励,使得模型能够在接收到环境反馈的基础上不断自我改进,适应多变的任务和环境要求。此外,深度学习模型能够从大量数据中学习到复杂的模式和策略,提高调度策略的效率和精确性。但是市面上还没有一种将ppo算法、深度神经网络同时应用在工厂及仓库agv调度领域上。
3、因此,现有的调度系统在需求和环境条件频繁变化的情况下,无法有效处理复杂环境下的动态调度问题。
技术实现思路
1、为了解决现有技术中普遍存在的各种问题,本发明的目的在于提供一种基于改进ppo算法的多agv调度系统及其方法,该发明可以实现不同场景中agv调度策略网络的训练,训练速度快且调度策略网络高效、灵活。
2、本发明通过以下技术方案来实现上述目的:
3、一种基于改进ppo算法的多agv调度系统,包括:
4、多agv调度仿真环境环境、改进的ppo强化学习算法模型和深度神经网络;
5、其中,改进的ppo强化学习算法模型包括:计算样本中观测状态的g值时,区分结束状态terminated和truncated;当结束状态为terminated时,设置该结束状态的g值为0,而当结束状态为truncated时,该结束状态的g值使用critic估计,即vθ(s)。
6、根据本发明提供的一种基于改进ppo算法的多agv调度系统,所述深度神经网络为调度策略网络actor和价值函数critic的载体,所述调度策略网络actor包括特征提取模块和策略模块,所述价值函数critic包括特征提取模块和价值函数模块,两者共用一个特征提取模块。
7、根据本发明提供的一种基于改进ppo算法的多agv调度系统,所述特征提取模块为观测状态输入的第一块网络,使用多层卷积神经网络和池化层以及一个展平层和若干个全连接层构成,输出一维特征向量;所述策略模块连接在所述特征提取模块后,使用特征提取模块输出的特征向量作为输入,由若干个全连接层构成,输出动作;所述价值函数模块同样连接在特征提取模块后,使用特征提取模块输出的特征向量作为输入,由若干个全连接层构成,输出状态价值的预测值。
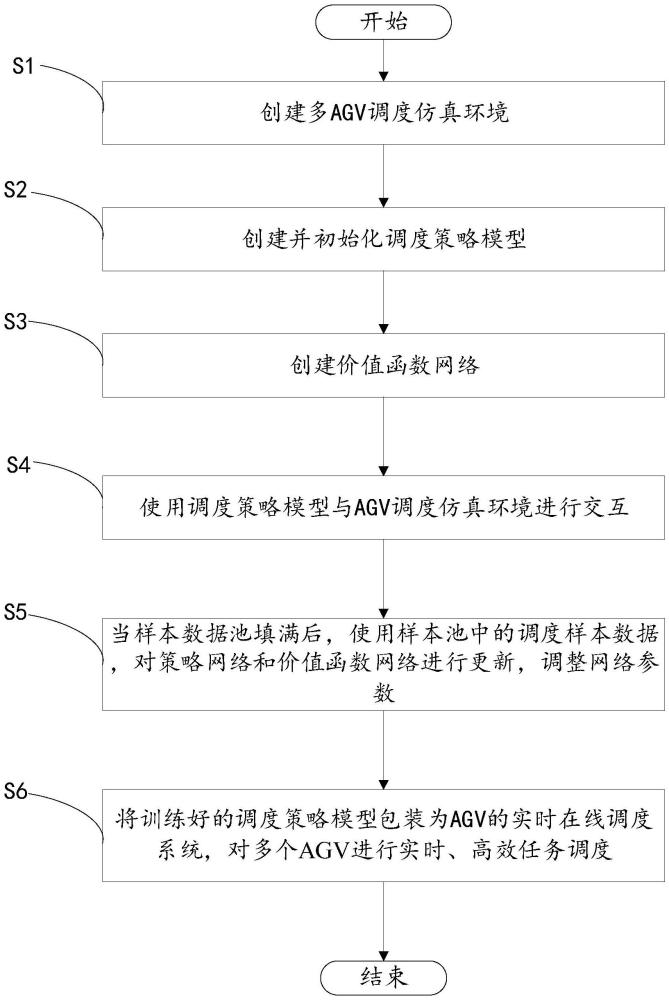
8、一种基于改进ppo算法的多agv调度方法,该方法用于实施上述的基于改进ppo算法的多agv调度系统,该方法包括以下步骤:
9、创建多agv调度仿真环境,用于模拟真实场景中多agv运作的虚拟环境;
10、创建并初始化调度策略网络,用于根据当前状态生成调度决策;
11、创建价值函数网络,用于对当前状态的价值进行评估,并指导调度策略网络的优化方向,以帮助实现稳定高效的策略更新过程;
12、使用调度策略网络与agv调度仿真环境进行交互,即策略网络根据当前环境状态生成调度决策,agv调度仿真环境根据该调度决策执行相应的物理模拟,并在agv调度仿真环境中执行调度任务,计算所有agv每一仿真步的状态、动作、奖励以及其他信息,记录调度样本数据到样本数据池中;
13、当样本数据池填满后,使用样本池中的调度样本数据,对策略网络和价值函数网络进行更新,调整网络参数;
14、将训练好的调度策略网络包装为agv的实时在线调度系统,对多个agv进行实时、高效任务调度。
15、根据本发明提供的一种基于改进ppo算法的多agv调度方法,所述多agv调度仿真环境基于马尔可夫决策过程模型搭建,所述马尔可夫决策过程模型包括:
16、观测状态的设置,其包含agv当前所处状态信息;
17、动作的设置,即为调度指令,包括系统可以执行的所有动作的集合;
18、结束条件,所述马尔可夫决策过程模型包括三种结束条件,分别是:完成所有搬运任务、超过设定的最大仿真时间、仿真过程中发生碰撞;
19、奖励函数的设置,根据训练目标进行设置。
20、根据本发明提供的一种基于改进ppo算法的多agv调度方法,在设置观测状态时,观测状态由5个二维矩阵构成,分别表示地图信息、agv所在位置、agv目标位置,其他agv当前位置和其他agv的目标位置;其中,这些矩阵表示的是由拓扑地图转换后的栅格地图,矩阵的尺寸根据实际地图尺寸和分辨率计算得到;
21、其中,地图信息矩阵表示了整个工作区域的静态环境信息;agv所在位置矩阵标记了当前所有agv在栅格地图中的具体位置;gv目标位置矩阵标记了每个agv的目标位置;其他agv当前位置矩阵标记了除了当前关注的agv之外,其他所有agv在栅格地图中的当前位置;其他agv的目标位置矩阵标记了除了当前关注的agv之外,其他所有agv的目标位置。
22、根据本发明提供的一种基于改进ppo算法的多agv调度方法,在设置动作时,调度指令被设计为当前agv应该前往的下一个节点的id,当agv调度仿真环境接收到动作后使用a*路径搜索算法搜索agv前往该节点的路径,并执行该路径。
23、根据本发明提供的一种基于改进ppo算法的多agv调度方法,在设置结束条件时,在一个调度仿真episode中,设置有若干个搬运任务;在一个调度仿真episode中,所有agv需要共同完成设定的搬运任务,因而具有相同的结束状态;
24、在完成所有搬运任务和发生碰撞这两种结束状态被称为终止,而达到最大仿真时间的技术状态被称为截断。
25、其中,奖励由密集奖励和稀疏奖励两部分组成,密集奖励在每一个仿真步都会获得,表示agv执行该步动作所消耗的能量,为负值;稀疏奖励只有在agv完成一个搬运任务或达到结束条件时获得。
26、根据本发明提供的一种基于改进ppo算法的多agv调度方法,agv调度仿真环境在与调度策略网络交互的过程中,首先输出观测状态;在调度策略网络输入观测状态并输出动作后,仿真环境输入并执行该动作来进行仿真;
27、其中,仿真环境中包含有向图表示的拓扑地图和若干台agv小车,以及任务生成器、任务分配器和a*路径规划算法;
28、在拓扑地图中,节点表示agv可以停留的位置,边表示节点之间可通行的路径,对每一台agv,仿真环境会分别为其计算观测状态、接收动作并规划路径。
29、根据本发明提供的一种基于改进ppo算法的多agv调度方法,在调度策略网络对agv调度仿真环境中多个agv进行调度时,采用异步调度的方式,当agv调度仿真环境中存在agv请求路径时,agv调度仿真环境返回当前agv的观测状态、奖励、结束状态,并接受动作;
30、当agv调度仿真环境中没有agv请求路径时,仿真才会继续进行;
31、当一个agv触发结束状态时,需要依次返回所有agv的观测状态、奖励、结束状态,并保存这些仿真样本数据到样本数据池中。。
32、由此可见,相比于现有技术,本发明具有以下有益效果:
33、1、提高调度效率:本发明通过引入改进的ppo(proximal policy optimization,近端策略优化)算法,系统能够更快速地学习和适应复杂的调度环境。ppo算法在保持策略稳定性的同时,允许较大的策略更新步长,从而加速了学习过程,提高了调度效率。
34、2、增强鲁棒性:本发明在改进的ppo算法中,通过区分结束状态terminated和truncated,并分别处理其g值(累积回报),使得算法能够更准确地评估不同情况下的策略效果,这种处理方式增强了算法对噪声和不确定性的容忍度,提高了系统的鲁棒性。
35、3、实现高效策略更新:本发明利用深度神经网络构建的价值函数网络(critic)对状态价值进行评估,并指导调度策略网络(actor)的优化方向,这种结构不仅有助于实现稳定高效的策略更新过程,还能够在一定程度上减少过拟合的风险,提高调度策略的泛化能力。
36、4、仿真环境支持:本发明通过创建多agv调度仿真环境,系统能够在虚拟环境中模拟真实场景中的多agv运作,为算法的训练和测试提供了便利。仿真环境能够复现各种复杂场景和突发事件,使得调度策略能够在实际应用前得到充分验证和优化。
37、5、实时在线调度能力:本发明训练好的调度策略网络可以被包装为agv的实时在线调度系统,对多个agv进行实时、高效的任务调度,这种实时调度能力对于提高生产效率、降低运营成本具有重要意义。
38、6、可扩展性和灵活性:本发明基于深度学习和强化学习的调度系统具有较高的可扩展性和灵活性。随着生产环境和需求的变化,可以通过调整网络结构和算法参数来适应新的场景和任务要求,无需对系统进行大规模的重构或修改。
39、7、减少人工干预:本发明自动化调度系统能够减少人工干预和错误,提高调度的准确性和一致性。同时,自动化调度还能够降低人力成本,提高生产效益。
40、综上所述,本发明基于改进ppo算法的多agv调度系统及其方法在提高调度效率、增强鲁棒性、实现高效策略更新、支持仿真环境验证、实现实时在线调度、可扩展性和灵活性以及减少人工干预等方面具有显著优势。
41、下面结合附图和具体实施方式对本发明作进一步详细说明。
本文地址:https://www.jishuxx.com/zhuanli/20241106/324146.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表