一种基于改进强化学习的手机中框点胶路径规划方法
- 国知局
- 2024-11-21 11:42:02
本发明涉及点胶路径规划,尤其涉及一种基于改进强化学习的手机中框点胶路径规划方法。
背景技术:
1、手机中框点胶工艺在现代手机制造过程中占据了至关重要的位置,它直接影响到手机的整体结构强度和防水性能。传统的点胶路径规划方法主要依赖预设规则或简单的算法来确定点胶路径。然而,随着手机设计的多样化和精密化,点胶工艺要求也变得愈加复杂和精细,传统方法已难以满足现有生产的需求。
2、传统点胶路径规划方法的一个主要缺陷是其无法自适应复杂且动态变化的生产环境。这些方法通常依赖于事先设定的固定路径和参数,缺乏灵活性和智能化,导致在面对不同手机中框设计时无法做出最优调整。比如,在实际操作中,点胶头的位置和姿态以及点胶量的精确控制在很大程度上决定了点胶的质量和效率,传统方法难以在实时生产中根据反馈进行调整和优化,往往导致点胶路径不够优化,从而影响点胶的精度和效率。
3、此外,传统点胶路径规划方法对粘合剂的使用控制不够精确,容易导致材料浪费。一方面是由于点胶路径的非最优性,导致多余的路径增加了粘合剂的消耗;另一方面是点胶量的控制不精确,可能导致涂布过量或者不足,不仅增加了生产成本,还可能影响产品的质量。特别是在面对不同的中框设计和粘合剂特性时,传统方法无法自适应调整,进一步加剧了材料的浪费问题。
4、基于这些传统方法的缺陷,现有技术急需一种能够在复杂和动态环境中自适应调整的点胶路径规划方法。强化学习作为一种智能算法,通过在实际操作中不断学习和优化策略,具有显著的潜力来解决上述问题。然而,现有的强化学习算法在应用于点胶路径规划时也面临一些挑战。例如,单层的强化学习模型可能无法处理多维度的状态和动作空间,难以达到对点胶路径、点胶头姿态和点胶量的全面优化。再者,现有的强化学习模型在初步训练阶段往往依赖大量的实验数据和计算资源,对于生产环境的实时反馈处理能力不足,无法及时调整策略以适应实际操作中的变化。
5、综上所述,传统的点胶路径规划方法在应对复杂和动态变化的生产环境时存在诸多缺陷,包括路径优化不足、材料浪费严重和对实时反馈处理能力不足等问题。本发明提供一种改进的强化学习方法,通过多级模型的构建和实时反馈的在线优化,全面提升点胶路径规划的精确性和效率,解决生产过程中遇到的技术难题。
技术实现思路
1、本发明的一个目的在于提出一种基于改进强化学习的手机中框点胶路径规划方法,本发明可以实现最优路径规划和精确控制,从而提高点胶的精度和效率,减少材料浪费。技术方案如下:
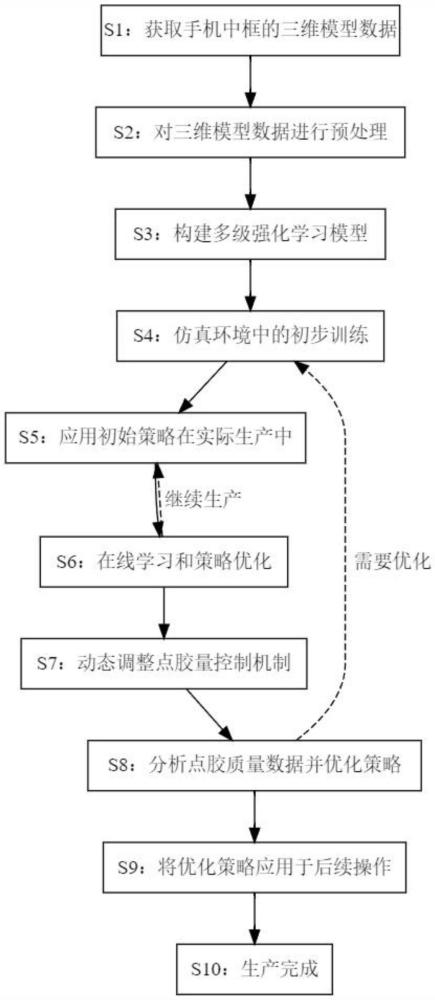
2、一种基于改进强化学习的手机中框点胶路径规划方法,包括以下步骤:
3、s1、获取手机中框的三维模型数据;
4、s2、对三维模型数据进行预处理,生成标准化的点胶区域;
5、s3、结合标准化的点胶区域构建多级强化学习模型;
6、s4、对多级强化学习模型进行初步训练,采用仿真环境模拟点胶过程,通过多级试探性动作获取初始策略;
7、s5、应用初始策略在实际生产过程中,使用多传感器系统实时监控点胶头的位置、姿态、距离、角度以及点胶质量,并反馈至多级强化学习模型中;
8、s6、多级强化学习模型根据实时反馈进行在线学习和策略优化;
9、s7、动态调整点胶量控制机制,根据多级强化学习模型的反馈和优化结果调整点胶头的输出量;
10、s8、在每次点胶操作后,分析多级点胶质量数据,更新和优化多级强化学习模型的奖励机制和策略,使其逐渐逼近最优路径规划;
11、s9、将最优路径规划和控制策略应用于后续的点胶操作,直至完成点胶操作。
12、可选的,所述s1包括以下子步骤:
13、s11、通过三维扫描仪对手机中框进行扫描,生成原始三维点云数据;
14、s12、对原始三维点云数据进行预处理,生成精确的三维点云数据;
15、s13、根据精确的三维点云数据得到标准化的三维模型数据m3d。
16、可选的,所述s2包括以下子步骤:
17、s21、对标准化的三维模型数据m3d进行分割,提取出初始的点胶区域边界,形成初始边界点集binitial:
18、s22、使用形态学方法对初始边界点集binitial进行处理,生成精确的点胶边界bglue;
19、s23、根据点胶工艺要求对精确的点胶边界bglue进行细化处理,生成符合点胶工艺要求的标准化点胶区域aglue。
20、可选的,所述s3包括以下子步骤:
21、第一层状态空间s1,表示点胶头在三维模型数据m3d中的位置和姿态;
22、第二层状态空间s2,表示点胶头与中框表面的距离和角度,以及在标准化点胶区域aglue中的位置;
23、第三层状态空间s3,表示点胶质量参数,包括:胶水在点胶区域aglue上的厚度分布以及点胶区域aglue上的平均胶水厚度;
24、s32、定义多级动作空间:
25、第一层动作空间a1,表示点胶头在三维模型数据m3d中的移动方向和速度;
26、第二层动作空间a2,表示点胶头的距离和角度的调整速度以及在标准化点胶区域aglue中的位置调整速度;
27、第三层动作空间a3,表示点胶头的点胶速度和点胶量控制,所述点胶量控制即点胶量的变化速度;
28、s33、设计分层次奖励机制:
29、第一层奖励机制r1,根据点胶路径在三维模型数据m3d中的点胶时间点胶路径长度而设定;
30、第二层奖励机制r2,根据点胶头与中框表面的精确对准程度以及在标准化点胶区域aglue中的位置设定;
31、第三层奖励机制r3,根据点胶质量设定。
32、可选的,所述s4包括以下子步骤:
33、s41、构建仿真环境esim,仿真环境基于标准化的三维模型数据m3d和点胶区域数据aglue;
34、s42、初始化多级强化学习模型的初始策略πinit,初始策略定义为在状态空间s1,s2,s3和动作空间a1,a2,中选择最优动作的概率分布;
35、s43、在仿真环境esim中,通过多级试探性动作进行初步训练,记录状态转移和奖励,更新初始策略πinit:
36、πinit(s,a)=πinit(s,a)+α[r+γmaxa'q(s′,a′)-q(s,a)];
37、其中,πinit(s,a)表示状态s下选择动作a的概率,α为学习率,r为即时奖励,γ为折扣因子,q(s,a)为状态-动作值函数;
38、s44、在仿真环境esim中对初始策略πinit进行多轮迭代训练,利用经验回放技术存储和重用状态转移样本,进一步优化策略:
39、πopt(s,a)=argmaxaq(s,a);
40、其中,πopt(s,a)表示优化后的策略,选择使状态-动作值q(s,a)最大的动作a;
41、s45、在仿真环境esim中进行策略验证,通过模拟点胶过程,评估优化策略πopt的性能,将优化后的策略πopt应用于实际生产环境中,初始化实际点胶操作中的策略参数。
42、可选的,所述s6包括以下子步骤:
43、s61、第一层模型根据实时反馈调整点胶头的移动路径:
44、获取点胶头当前位置(xt,yt,zt)和目标位置(xt+1,yt+1,zt+1);
45、计算点胶头移动路径的最短距离dmin和所需时间tmin:
46、
47、其中,vmax为点胶头的最大移动速度,dmin为点胶头从当前位置到目标位置的最短距离;
48、实时调整点胶头的移动路径pmove,确保路径最短且时间最少:
49、
50、其中,p为点胶头移动路径,n为路径上的点数,λ为平衡路径距离和时间的权重参数,表示路径上每个点的速度变化率;
51、s62、第二层模型根据实时反馈调整点胶头与中框表面的距离和角度:
52、获取点胶头与中框表面的实时距离dreal和角度(αreal,βreal);
53、计算距离误差δd和角度误差(δα,δβ):
54、δd=dopt-dreal;
55、δα=αopt-αreal;
56、δβ=βopt-βreal;
57、其中,dopt为最优距离,dreal为实时距离,δd为距离误差,αopt和βopt分别为最优角度,αreal和βreal分别为实时角度,δα和δβ为角度误差;
58、实时调整点胶头的距离和角度(dadj,αadj,βadj),确保点胶头精确对准中框表面:
59、
60、
61、其中,η1、κ、μ为调整因子,表示实时误差变化率对距离和角度调整的影响;
62、s63、第三层模型根据实时反馈调整点胶速度和点胶量:
63、获取当前点胶速度vreal和点胶量qreal;
64、计算点胶速度误差δv和点胶量误差δq:
65、δv=vopt-vreal;
66、δq=qopt-qreal;
67、其中,vopt为最优点胶速度,vreal为实时点胶速度,δv为速度误差,qopt为最优点胶量,qreal为实时点胶量,δq为点胶量误差;
68、实时调整点胶速度和点胶量(vadj,qadj),确保点胶质量最佳:
69、
70、其中,ν调整因子,表示实时误差变化率对速度调整的影响,ξ为调整因子,表示实时误差变化率对点胶量调整的影响。
71、可选的,所述s8包括以下子步骤:
72、s81、在每次点胶操作后,收集并存储多级点胶质量数据dquality,该数据包括点胶路径pmove、点胶距离和角度(dadj,αadj,βadj)以及点胶速度和点胶量(vadj,qadj);
73、s82、对收集到的点胶质量数据dquality进行分析,计算各项质量指标的误差值,包括路径误差δp、距离误差δd、角度误差(δα,δβ)和点胶质量误差(δv,δq):
74、δp=ptarget-pmove;
75、δd=dopt-dadj;
76、δα=αopt-αadj;
77、δβ=βopt-βadj;
78、δv=vopt-vadj;
79、δq=qopt-qadj;
80、其中,ptarget为目标点胶路径,dopt,αopt,βopt最优距离和角度,vopt,qopt为最优点胶速度和点胶量;
81、s83、基于误差值,更新多级强化学习模型的奖励机制rnew,确保模型能够学习并优化点胶路径、距离、角度和点胶量:
82、rnew=rprev+β∑(δp+δd+δα+δβ+δv+δq);
83、其中,rprev为更新前的奖励机制,β为更新权重;
84、s84、使用更新后的奖励机制rnew,优化多级强化学习模型的策略πopt,使其逐渐逼近最优路径规划:
85、
86、其中,πopt为优化后的策略,为在新奖励机制下的期望奖励;
87、s85、将优化后的策略πopt应用于后续的点胶操作,确保点胶路径和质量持续优化。
88、可选的,在点胶操作开始之前,对手机中框进行称重,记录其初始重量winitial,以确定在点胶过程中所需的粘合剂量;
89、在完成点胶操作后,对手机中框再次进行称重,记录其点胶后的重量wpost_glue,通过计算点胶后的重量差δwglue,确定实际使用的粘合剂量:
90、δwglue=wpost_glue-winitial;
91、其中,δwglue表示点胶过程中所使用的粘合剂的总重量。
92、在点胶后,使用设备将中框表面多余的胶水擦除干净,并对擦胶后的中框进行再次称重,记录擦胶后的重量wcleaned,通过计算擦胶前后重量差wcleaned,确定擦除的多余粘合剂量:
93、δwexcess=wpost_glue-wcleaned;
94、其中,δwexcess表示擦除的多余粘合剂的重量;
95、通过比较实际使用的粘合剂量δwglue和擦除的多余粘合剂量δwexcess,确定材料浪费的比例:
96、
97、根据材料浪费比例判断是否需要优化点胶路径和控制策略,若浪费比例超过预设阈值,则需重新调整点胶策略以减少材料浪费;
98、根据材料浪费判断的结果,将多余的粘合剂量反馈至多级强化学习模型,调整奖励机制和策略,优化后续点胶操作的路径和点胶量控制,确保材料浪费在合理范围内。
99、本发明的有益效果是:
100、(1)本发明通过构建多级强化学习模型,将点胶过程中的复杂状态空间和动作空间进行分层处理,包括点胶头的位置和姿态、与中框表面的距离和角度以及点胶质量参数等多个维度,有效解决了单层强化学习模型在处理多维度状态和动作空间时的局限性。在多级状态空间的定义中,第一层状态空间关注点胶头在三维空间中的位置和姿态,第二层状态空间关注点胶头与中框表面的距离和角度,第三层状态空间关注点胶质量参数,如胶水厚度和分布均匀性。多级动作空间分别对应于不同层次上的操作优化,包括移动路径、距离和角度调整、点胶速度和量的控制,能够实现对点胶过程的全方位优化,确保点胶头在不同维度上都能进行最优操作,通过分层次奖励机制的设计,不同层次的强化学习模型可以根据各自的优化目标进行奖励反馈,从而在整体上实现最优路径规划,大幅提高了点胶过程的智能化和自适应能力。
101、(2)本发明在实际生产过程中,实时监控点胶头的位置、姿态、距离、角度以及点胶质量,将这些信息反馈至多级强化学习模型中,模型根据实时反馈进行在线学习和策略优化,动态调整点胶路径、距离和角度以及点胶速度和量,确保点胶头能够自适应不同的生产环境,第一层模型根据实时反馈调整点胶头的移动路径,确保路径最短且时间最少,第二层模型根据实时反馈调整点胶头与中框表面的距离和角度,确保点胶头精确对准中框表面,第三层模型根据实时反馈调整点胶速度和点胶量,确保点胶质量最佳,保证了点胶过程的高效性和精确性。
本文地址:https://www.jishuxx.com/zhuanli/20241120/332457.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表