一种超大规模数据导出方法与流程
- 国知局
- 2024-11-21 12:05:32
本发明涉及软件服务,尤其涉及一种超大规模数据导出方法。
背景技术:
1、saas及企业服务行业内已有的数据导出方法基本都是预生成,利用离线平台进行导出,或者只能导出小批量的几万条数据。业内的通用型方案中,有以下几点弊端:利用离线平台导出,由于离线平台如hadoop等技术和java研发人员采用的技术体系不一样,此类开发需要大数据研发人员介入研发,而整体的表结构又是java研发人员进行设计,相较于大数据研发人员,java研发人员更加熟悉自身的业务,现方案无法支持各个业务线的java研发人员进行快速的进行功能迭代;导出时效性较低,性能较慢,往往需要几十分钟才能导出,并且由于离线计算平台和业务数据无法实时同步,基本无法导出实时数据,只能支持导出离线数据,客户体验较差;对于大体量超过百亿数据的场景,无法解决大批量数据查询和导出一致性的问题。
2、此外,由于搜索引擎elasticsearch的分词策略和离线的查询策略不一致,存在导出和搜索结果数据不一致的问题。对于小型公司,可能直接在业务数据库mysql中进行开发导出;而大型公司对于超过上百亿,千亿的数据体量的业务无法能够快速的进行导出,经常会出现内存溢出相关的问题,稍微复杂的查询传统关系型数据库会经常出现内存溢出,或者执行时间超过十个小时,经常面临导出失败。由于和线上业务共用一套数据库,也会对线上业务系统的稳定性带来隐患。
技术实现思路
1、本发明的目的是为了解决现有技术中存在的缺点,而提供了一种超大规模数据导出方法,包括以下步骤:
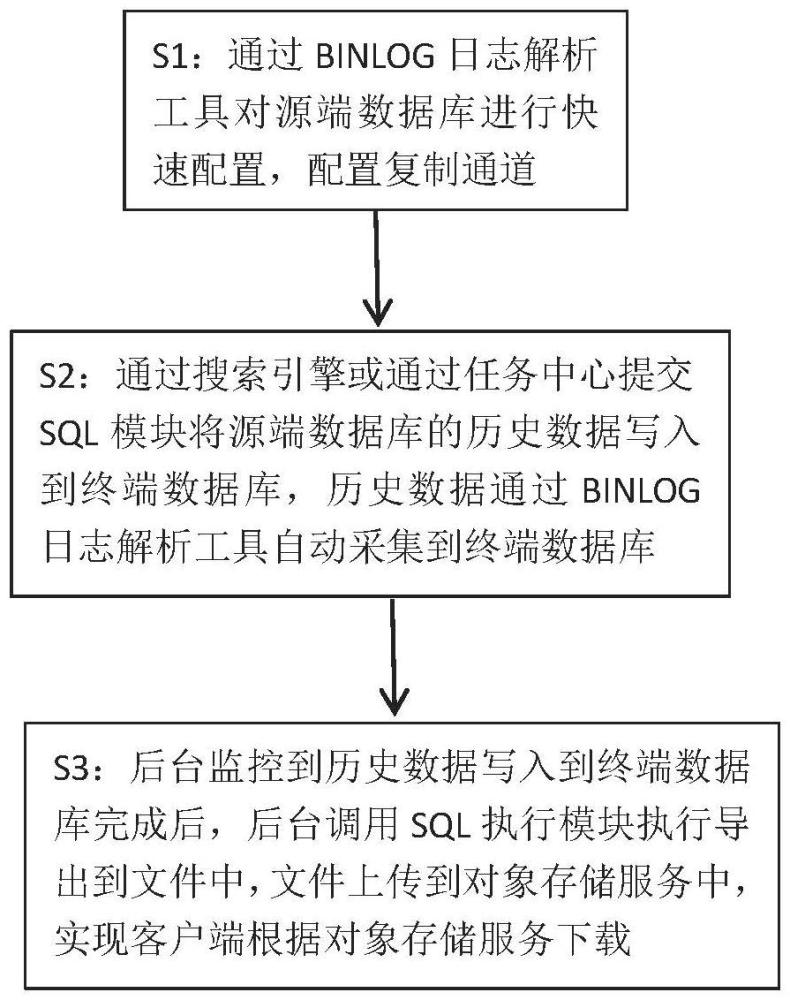
2、s1:通过binlog日志解析工具对源端数据库进行快速配置,配置复制通道;
3、s2:通过搜索引擎或通过任务中心提交sql模块将所述源端数据库的历史数据写入到终端数据库,所述历史数据通过所述binlog日志解析工具自动采集到所述终端数据库;
4、s3:后台监控到所述历史数据写入到所述终端数据库完成后,后台调用所述sql执行模块执行导出到文件中,所述文件上传到对象存储服务中,实现客户端根据所述对象存储服务下载。
5、优选地,在步骤s1中,所述快速配置,进一步包括:
6、通过平台化管理的界面填写所述源端数据库的源端数据库ip地址、源端数据库账号、源端数据库密码在内的源端数据库信息,以及所述终端数据库的终端数据库地址、终端数据库账号、终端数据库密码在内的终端数据库信息,将所述源端数据库信息和所述终端数据库信息填写到所述平台化管理的控制台。
7、优选地,在步骤s1中,所述binlog日志解析工具,进一步包括:
8、所述binlog日志解析工具通过配置的所述源端数据库地址、所述源端数据库账号和所述源端数据库密码链接到所述源端数据库中,所述binlog日志解析工具实时捕捉dml操作的binlog事件,实现通过所述binlog日志解析工具保障所述源端数据库和所述终端数据库的一致性。
9、优选地,所述保障所述源端数据库和所述终端数据库的一致性,进一步包括:
10、将所述binlog事件中的update操作和insert操作转义成replace操作,捕捉到的delete操作维持不变,将所述delete操作和所述replace操作复制到所述终端数据库执行相应的sql语句,所述终端数据库的数据内容和表结构与所述源端数据库的所述数据信息相同。
11、优选地,在步骤s2中,所述通过任务中心提交sql模块将所述源端数据库的历史数据写入到所述终端数据库,进一步包括:
12、向所述任务中心提交所述sql模块到tidb集群中,所述tidb集群根据所述sql模块的sql执行模块将所述历史数据写入到所述终端数据库。
13、优选地,在步骤s2中,通过搜索引擎将所述源端数据库的历史数据写入到所述终端数据库,进一步包括:
14、在后台搜索所述历史数据,点击导出按钮后,所述搜索引擎根据搜索条件从所述源端数据库获得所述搜索数据,将所述搜索数据写入到所述终端数据库。
15、优选地,所述搜索引擎,进一步包括
16、所述搜索引擎中记录所述搜索条件和所述搜索数据中的每条数据对应的主键字段,所述搜索引擎根据所述搜索条件批量搜索所述源端数据库的表数据的主键字段。
17、优选地,所述主键字段,进一步包括:
18、所述主键字段采用int类型,由于int类型占用内存空间小,实现下载超大规模数据的数据体量也少,通过search after批量将所述主键字段快速写入到所述终端数据库的表中。
19、优选地,所述tidb集群,包括:
20、根据所述tidb集群的多节点分布式查询所述源端数据库,所述tidb集群的tikv节点和列存节点进行并发的扫描所述主键字段进行查询所述源端数据库获取与所述搜索条件对应的数据。
21、优选地,所述列存节点,进一步包括:
22、所述列存节点提供列式存储,所述列式存储实现快速返回列数据,所述tidb集群根据所述搜索条件搜索所述数据内容,将所述搜索数据返回到所述tidb集群的server层面,构造成hash内存表进行hash join操作,实现快速返回所述搜索数据。
23、与现有技术相比,本发明的有益效果是:
24、(1)本发明通过binlog日志解析平台工具进行快速的配置复制通道,实时复制到tidb数据库中,支持各个业务线研发人员能够进行快速的进行开发;实现在不影响业务正常运行和用户体验下,面向b端的大批量数据导出。
25、(2)本发明通过搜索引擎进行搜索,将主键记录下来,利用主键进行查询,在表与表关联之间,即使在百亿级别数据中进行查询,此时执行计划也会非常稳定,不会出现内存溢出相关问题,保证搜索和导出的数据一致性复杂的关联查询。
26、(3)本发明充分发挥和利用tidb集群的多节点的分布式查询,每个tikv节点和列存节点进行并发的扫描主键进行查询获取所对应的数据,tikv节点同时根据主键进行扫描数据,列存节点,由于数据是列式存储可以快速返回所需要的的列,将所有的数据返回到tidb的server层面,构造成hash内存表进行hash join操作,快速的返回数据,能够保证的在百亿数据查询中快速返回百万级别的数据导出。
27、(4)本发明通过通过搜索引擎或通过任务中心提交sql模块将所述源端数据库的历史数据写入到终端数据库,能够实现后端java研发快速的进行功能研发,也能实现异构平台的数据实时复制,完成实时数据的快速导出。
技术特征:1.一种超大规模数据导出方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种超大规模数据导出方法,其特征在于,在步骤s1中,所述快速配置,进一步包括:
3.根据权利要求2所述的一种超大规模数据导出方法,其特征在于,在步骤s1中,所述binlog日志解析工具,进一步包括:
4.根据权利要求3所述的一种超大规模数据导出方法,其特征在于,所述保障所述源端数据库和所述终端数据库的一致性,进一步包括:
5.根据权利要求4所述的一种超大规模数据导出方法,其特征在于,在步骤s2中,所述通过任务中心提交sql模块将所述源端数据库的历史数据写入到所述终端数据库,进一步包括:
6.根据权利要求5所述的一种超大规模数据导出方法,其特征在于,在步骤s2中,通过搜索引擎将所述源端数据库的历史数据写入到所述终端数据库,进一步包括:
7.根据权利要求6所述的一种超大规模数据导出方法,其特征在于,所述搜索引擎,进一步包括
8.根据权利要求7所述的一种超大规模数据导出方法,其特征在于,所述主键字段,进一步包括:
9.根据权利要求8所述的一种超大规模数据导出方法,其特征在于,所述tidb集群,包括:
10.根据权利要求9所述的一种超大规模数据导出方法,其特征在于,所述列存节点,进一步包括:
技术总结本发明涉及软件服务技术领域,尤其涉及一种超大规模数据导出方法,包括以下步骤:S1:通过BINLOG日志解析工具对源端数据库进行快速配置,配置复制通道;S2:通过搜索引擎或通过任务中心提交SQL模块将源端数据库的历史数据写入到终端数据库,历史数据通过BINLOG日志解析工具自动采集到终端数据库;S3:后台监控到历史数据写入到终端数据库完成后,后台调用SQL执行模块执行导出到文件中,文件上传到对象存储服务中,实现客户端根据对象存储服务下载。本发明支持超大型互联网公司,在导出百万级数据分钟级别导出,通过搜索引擎Elasticsearch搜索的结果和导出数据一致性,能够实现后端java研发快速的进行功能研发,异构平台的数据实时复制,完成实时数据的快速导出。技术研发人员:刘浩,王友运,刘泉受保护的技术使用者:企迈科技有限公司技术研发日:技术公布日:2024/11/18本文地址:https://www.jishuxx.com/zhuanli/20241120/334249.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表