一种基于二叉树结构的知识点查全方法和系统
- 国知局
- 2024-11-21 12:18:10
本发明涉及电数字数据处理,更具体地说,它涉及一种基于二叉树结构的知识点查全方法和系统。
背景技术:
1、随着大模型在自然语言处理(nlp)领域的广泛应用,以大模型为核心的问答系统在各个专业领域展现出强大的潜力和应用价值。为了在特定领域中提供准确、专业的回答,大模型问答系统往往需要依赖结构化的知识库。这些知识库不仅需要覆盖广泛的专业知识,还要能够高效地从中提取出符合用户需求的知识点。因此,知识库的构建和检索策略直接影响着大模型问答系统在特定领域的表现。
2、在技术文档、法律、医疗等具有复杂层级结构的领域,传统的知识检索方法面临显著挑战。具体来说,传统检索方法通常依赖于固定的检索参数和相似度计算,然而这类方法容易因top-k检索限制而遗漏掉部分相关的知识点。例如,当用户提出一个需要涵盖多个知识点的复杂问题时,系统可能只能返回部分知识点,导致回答不完整,这直接影响了问答系统的专业性和可靠性。即传统的知识点检索方法在面对具有复杂层级结构的知识库时,无法全面提取相关知识点。常见的问题包括:
3、(1)检索范围受限:传统的top-k检索方法通常只能返回最接近的几个知识点,这对于需要全面回答的问题场景来说是不足够的,尤其当知识点跨越多个层级时。
4、(2)层次化结构处理困难:在具有复杂层级的知识体系中,简单的相似度检索难以应对多层级的知识关系,无法保证全面检索所有相关的知识点。
5、因此,需要一种更为智能且全面的知识点检索策略来解决上述问题。
技术实现思路
1、本发明要解决的技术问题是针对现有技术的不足,提供一种基于二叉树结构的知识点查全方法和系统,确保了大模型能够从知识库中提取出所有相关的知识点,从而提升问答系统的专业性和可靠性。
2、本发明所述的一种基于二叉树结构的知识点查全方法,包括以下步骤:
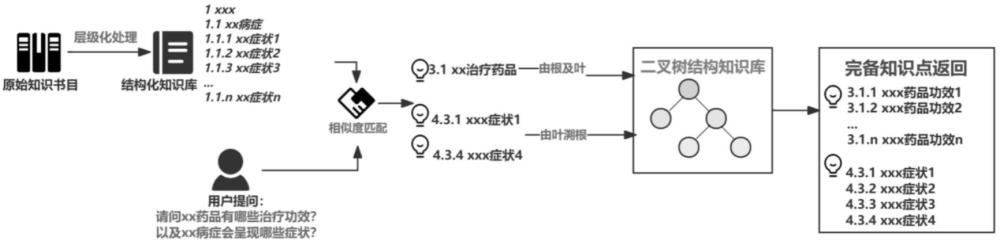
3、s1:构建层次结构化的知识库;
4、s2:获取用户输入问句,并对所述用户输入问句进行改写后使用预先训练好的大语言模型对其进行意图识别,得到意图识别结果;
5、s3:将所述意图识别结果与知识库中的知识点进行相似度检索匹配,返回相似度最高的前k个知识点;其中k是预先设定的参数,表示返回的知识点的数目;
6、s4:构建二叉树检索机制,将所述知识点输入到二叉树检索机制中进行知识点的查全,得到目标知识点集合。
7、作进一步的改进,步骤s4具体包括:
8、s4.1:通过索引表对所述知识点进行层级判断,以确定所述知识点为中间根节点还是末端叶节点;
9、s4.2:若所述知识点在经过层级判断后,确定其为末端叶节点,则执行以下操作:
10、s4.2.1:通过索引表识别所述知识点的节点位置,沿二叉树结构向上确定其上一级节点;
11、s4.2.2:将所述上一级节点作为新的根节点,沿二叉树结构向下收集其所有叶节点下的知识点内容;
12、s4.3:若所述知识点在经过层级判断后,确定其为中间根节点,则执行以下操作:
13、s4.3.1:通过索引表识别所述知识点的节点位置;
14、s4.3.2:沿二叉树结构向下收集其所有叶节点下的知识点内容;
15、s4.4将得到的所有所述知识点内容与所述知识点进行合并,得到目标知识点集合。
16、作进一步的改进,步骤s1具体包括:
17、s1.1:对原始的书目文本进行清洗,以对其添加标题号;
18、s1.2:以每个所述标题号及其中的书目文本的内容作为一个原始知识点,对每个所述原始知识点进行前缀的添加,以得到知识点;
19、s1.3:为所述知识点建立索引字典表 m;
20、s1.4:将所述各知识点进行向量化以构建知识库。
21、进一步的,步骤s1.2具体为:
22、为所述原始知识点的标题号所有的上级标题号对应的标题名称作为前缀,通过下式表示:
23、,
24、其中,表示原始知识点的完整的标题号,表示标题号的第级父级标题号,表示标题号的总层数,表示对应的标题名称,表示并集;
25、将所述前缀和原始知识点合并为知识点。
26、作进一步的改进,步骤s2具体包括:
27、s2.1:对所述输入问句进行预处理;
28、s2.2:结合历史对话记录对所述输入问句进行改写补全,形成用户查询;
29、s2.3:使用预先训练好的大语言模型对所述用户查询进行意图识别,得到意图识别结果。
30、进一步的,所述预处理包括:对所述输入问句进行分词、去除停用词、词性标注。
31、作进一步的改进,在步骤s3中,通过以下公式将所述意图识别结果与知识库中的知识点进行相似度检索匹配:
32、,
33、其中,表示知识库中第个知识点的向量,表示向量点积,表示向量的模,表示相似度分数。
34、进一步的,在步骤s3中,所述相似度最高的前k个知识点具体为:根据计算得到的所述相似度分数,选择相似度分数最高的前个所述知识点作为检索结果。
35、一种基于二叉树结构的知识点查全系统,该系统包括:
36、知识库构建模块:用于将原始的书目文本转换为知识点,并根据所有的所述知识点构建层级结构化的知识库;
37、意图识别模块:用于对用户输入问句进行改写,并通过预训练好的大语言模型对改写后的所述用户输入问句进行意图识别,得到意图识别结果;
38、知识点检索模块:用于将所述意图识别结果与知识库中的知识点进行相似度检索匹配,返回相似度最高的前k个知识点;其中k是预先设定的参数,表示返回的知识点的数目;
39、二叉树知识点查全机制模块:用于构建二叉树检索机制,将所述知识点输入到二叉树检索机制中进行知识点的查全,得到目标知识点集合。
40、有益效果
41、本发明的优点在于:本发明通过构建特定层级结构化的知识库和采用基于二叉树的独特检索机制,显著提高了在特定任务。利用书目文本数据进行知识库构建,通过用户意图的精准识别,使得系统能够理解用户提问中的特殊需求。进一步地,通过基于二叉树结构的深入检索,本发明能够全面地搜集相关知识点,确保了信息的完整性和深度,使得用户能够得到更加准确且全面的答案。
技术特征:1.一种基于二叉树结构的知识点查全方法,其特征在于,包括以下步骤:
2.如权利要求1所述的一种基于二叉树结构的知识点查全方法,其特征在于,步骤s4具体包括:
3.如权利要求1所述的一种基于二叉树结构的知识点查全方法,其特征在于,步骤s1具体包括:
4.如权利要求3所述的一种基于二叉树结构的知识点查全方法,其特征在于,步骤s1.2具体为:
5.如权利要求1所述的一种基于二叉树结构的知识点查全方法,其特征在于,步骤s2具体包括:
6.如权利要求5所述的一种基于二叉树结构的知识点查全方法,其特征在于,所述预处理包括:对所述输入问句进行分词、去除停用词、词性标注。
7.如权利要求1所述的一种基于二叉树结构的知识点查全方法,其特征在于,在步骤s3中,通过以下公式将所述意图识别结果与知识库中的知识点进行相似度检索匹配:
8.如权利要求7所述的一种基于二叉树结构的知识点查全方法,其特征在于,在步骤s3中,所述相似度最高的前k个知识点具体为:根据计算得到的所述相似度分数,选择相似度分数最高的前个所述知识点作为检索结果。
9.一种基于二叉树结构的知识点查全系统,其特征在于,该系统包括:
技术总结本发明公开了一种基于二叉树结构的知识点查全方法,属于电数字数据处理,包括:S1构建层次结构化的知识库;S2获取用户输入问句并经过一定的改写后,使用大语言模型对其进行意图识别;S3将处理过的用户输入与数据库中的知识点进行相似度检索匹配,返回top‑k个检索结果;S4构建二叉树检索机制,采用“由根及叶”和“由叶溯根”的思想方法来对检索结果进行知识点的查全。本发明还公开了一种基于二叉树结构的知识点查全系统。本发明能够广泛应用于复杂层级知识库的问答系统以及需要精确查全多个层级知识点的场景,同时能够有效规避由于top‑k检索限制而导致的知识点遗漏问题。技术研发人员:邢晓芬,陶玟羽受保护的技术使用者:华南理工大学技术研发日:技术公布日:2024/11/18本文地址:https://www.jishuxx.com/zhuanli/20241120/335115.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表