一种针对终端资源受限的联邦大模型个性化训练方法
- 国知局
- 2024-12-06 12:30:00
本发明涉及信息安全,特别涉及一种针对终端资源受限的联邦大模型个性化训练方法。
背景技术:
1、大模型,包括chatgpt、sora、及各行业大模型的出现促使人工智能从感知理解走向生成创造,推动ai迈向通用人工智能。大模型的训练依托超大规模的数据量,大模型的训练需要数千个gpu节点,采购成本高(为数十亿美元);在租用方面,构建一款模型的起始费用高达200万至300万美元。
2、而对于本地终端进行大模型训练时,存在以下技术问题:
3、(1)资源受限终端(如手机、平板等)无法进行本地大模型训练,即无法存储下大模型,并无法进行训练。若不借助大模型的训练结果,各终端利用本地有限的数据量无法获得高准确率。
4、(2)公域数据即将耗尽:传统的大模型训练面对的显著挑战之一,就是高质量的训练数据稀缺的问题。通常,这些模型在训练阶段都会依赖公开可用的数据集,比如维基百科、书籍、源代码等。而最近研究表明,高质量的语言数据有可能在2026年达到枯竭点,而更低质量的数据也将在2030年到2050年间耗尽。
5、(3)若借助远端的大模型训练,即将本地的原始数据发送给远端,存在数据泄露给远端的风险。
6、(4)不同用户之间存在着巨大的差异,包括但不限于兴趣、行为模式、地理位置等方面。当前的联邦学习方法未能有效地处理这些个体差异,导致模型在满足个体用户需求方面性能不尽如人意。该现象在大模型场景下会因工作节点个体资源有限不能承载个性化模型而突显。
技术实现思路
1、本发明提供一种针对终端资源受限的联邦大模型个性化训练方法,旨在解决本地终端进行大模型训练时存在的问题。
2、本发明提供一种针对终端资源受限的联邦大模型个性化训练方法,包括:
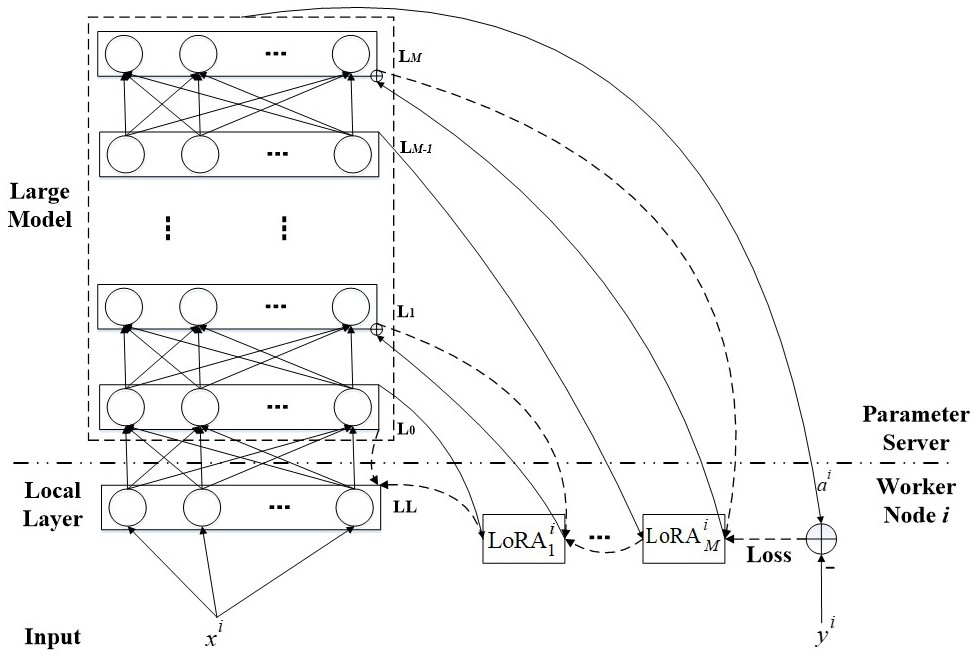
3、参数服务器端:位于参数服务器端的大模型包含多个层级,且每个大模型的层级设有一个权重矩阵;
4、本地终端:对应大模型中的每个权重矩阵,在本地终端的每个工作节点部署一个对应的lora模块,并在本地终端增设一个local layer层;
5、本地终端通过参数服务器端进行联邦大模型训练过程包括:
6、s1.前向传播:输入数据x经本地终端的local layer层传输给参数服务器端的大模型,中间数据沿大模型各层进行前向传播,并输出最终数据a;
7、s2.计算loss:通过大模型的输出数据a与本地标签y计算得到loss;
8、s3.反向传播:所得到的loss经过多个lora模块进行反向梯度传播,对本地终端的lora模块进行迭代更新。
9、作为本发明的进一步改进,本地终端的lora模块与大模型的权重矩阵属于并行关系。
10、作为本发明的进一步改进,数据在并行关系的lora模型和权重矩阵的传播过程为:
11、两个权重矩阵的输出数据在大模型处相加后,再加上大模型处的偏置,经激活函数进入大模型的下一层。
12、作为本发明的进一步改进,所述步骤s1中,在进行前向传播的同时,大模型第m层的输出向量am传递给工作节点i的且该lora模块的输出传给大模型第m+1层后,与带权输入zm+1相加,并经激活函数σ(·)得到
13、其中,大模型包含m+1层,即l0层至lm层,zm和am分别表示层lm的带权输入和输出,m∈{0,1,…,m};表示工作节点i在第m层的lora模块,即是一个矩阵;表示的输出。
14、作为本发明的进一步改进,所述步骤s2中,通过输出数据a与本地标签y计算得到loss的方式包括:
15、输出数据a与本地标签y的数值直接相减并取绝对值作为loss值;或者取输出数据a与本地标签y的数差值的均方作为loss值。
16、作为本发明的进一步改进,所述步骤s3中,反向传播具体包括:
17、令表示传给参数服务器端输出,反向传播公式为δl=((wl+1)tδl+1)⊙σ'(zl),其中δl和δl+1分别为第l层和第l+1层的误差,wl+1为第l+1层的权重矩阵,⊙表示hadamard积,σ'(zl)表示激活函数在输入为zl的导数值;反向传播链式法则需值,参数服务器端将值由大模型中的第m层传递到本地终端对应工作节点i的
18、作为本发明的进一步改进,所述步骤s3中,模型更新时只遍历本地终端的lora模型。
19、作为本发明的进一步改进,参数服务器端提供大模型的前向传播计算,loss在本地终端进行反向传播及更新。
20、本发明的有益效果是:利用参数服务器的计算、存储资源来帮助资源受限的多个终端实现对大模型的联邦训练。为防止数据泄露给ps,在本地端数据输出前布置一层神经网络;为实现各终端的个性化,在各节点布置并行的深度学习网络;为减轻对终端的资源冲击,并行深度学习网络采用lora。本发明在各终端节点部署与大模型并列的lora模块来最大化的降低对本地端资源的需求,使得平板、手机等可借助ps进行个性化的联邦大模型训练。
技术特征:1.一种针对终端资源受限的联邦大模型个性化训练方法,其特征在于,包括:
2.根据权利要求1所述针对终端资源受限的联邦大模型个性化训练方法,其特征在于,本地终端的lora模块与大模型的权重矩阵属于并行关系。
3.根据权利要求2所述针对终端资源受限的联邦大模型个性化训练方法,其特征在于,数据在并行关系的lora模型和权重矩阵的传播过程为:
4.根据权利要求1所述针对终端资源受限的联邦大模型个性化训练方法,其特征在于,所述步骤s1中,在进行前向传播的同时,大模型第m层的输出向量am传递给工作节点i的且该lora模块的输出传给大模型第m+1层后,与带权输入zm+1相加,并经激活函数σ(·)得到
5.根据权利要求1所述针对终端资源受限的联邦大模型个性化训练方法,其特征在于,所述步骤s2中,通过输出数据a与本地标签y计算得到loss的方式包括:
6.根据权利要求1所述针对终端资源受限的联邦大模型个性化训练方法,其特征在于,所述步骤s3中,反向传播具体包括:
7.根据权利要求1所述针对终端资源受限的联邦大模型个性化训练方法,其特征在于,所述步骤s3中,模型更新时只遍历本地终端的lora模型。
8.根据权利要求1所述针对终端资源受限的联邦大模型个性化训练方法,其特征在于,参数服务器端提供大模型的前向传播计算,loss在本地终端进行反向传播及更新。
技术总结本发明涉及信息安全技术领域,特别涉及一种针对终端资源受限的联邦大模型个性化训练方法。包括:参数服务器端:位于参数服务器端的大模型包含多个层级,且每个大模型的层级设有一个权重矩阵;本地终端:对应大模型中的每个权重矩阵,在本地终端的每个工作节点部署一个对应的LoRA模块,并在本地终端增设一个Local Layer层;本地终端通过参数服务器端进行联邦大模型训练过程包括:S1.前向传播;S2.计算Loss;S3.反向传播。本发明利用参数服务器的计算、存储资源来帮助资源受限的多个终端实现对大模型的联邦训练。技术研发人员:代明军受保护的技术使用者:喀什大学技术研发日:技术公布日:2024/12/2本文地址:https://www.jishuxx.com/zhuanli/20241204/341750.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。