一种融合关键帧和多任务混合模型的视频异常检测方法及系统
- 国知局
- 2025-01-10 13:31:23
本发明涉及视频异常检测,尤其涉及一种融合关键帧和多任务混合模型的视频异常检测方法及系统。
背景技术:
1、视频异常检测是指通过算法检测出视频中不符合人们预期的行为或事件,例如人群聚集、纵火、抢劫、逆向行驶、横穿马路等。随着社会的快速发展与大量高清摄像机的部署,视频异常检测已经成为国内外研究的热点领域。随着数据量的增加,传统机器学习算法无法捕获数据样本之间的复杂结构,在检测异常值时出现大幅度的性能下降。而基于深度学习的方法在视频异常检测中具有巨大的优势,不仅可以利用构建好的深层次卷积神经网络模型自主学习数据样本之间的分层判别特征,而且有着优异的自适应能力和数据处理能力。
2、视频可以看作许多连续图像按照时间顺序叠加而成,由于监控视频中不仅包含了行为动作信息,而且包含了大量重复帧,这导致了大量的内存消耗以及信息冗余,增加了模型的计算量,降低了视频异常检测效率和识别率。
3、目前,视频异常检测主要采用基于重构和预测的方法,其中重构方法中主要使用自编码器来完成编码和解码,但其强大的编码和解码能力导致异常数据样本被很好地重构,使得异常数据的误判率较高。而基于预测的方法主要通过学习历史帧来预测未来帧,并与真实的未来帧进行对比,但是该方法容易受到数据变化和环境噪声的影响,尤其是对于实时视频流的处理,这会导致模型的不稳定和误差增加,影响检测性能。
4、另一方面,当前主流的基于重构和预测的视频异常检测方法大多是通过学习历史帧来重构和预测未来帧,但场景变化和遮挡等会导致预测不准确,并且该方法会导致过去时间段异常行为的漏检,因此基于未来帧重构和预测的方法仍存在一定缺陷。
技术实现思路
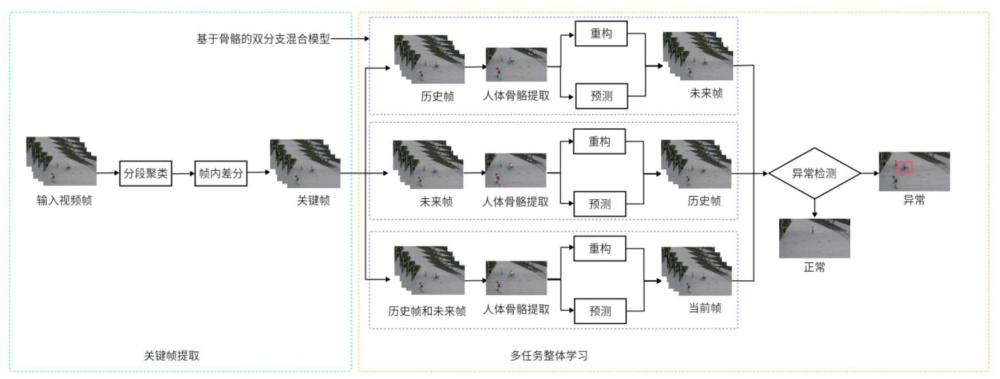
1、本发明针对上述问题,提出一种融合关键帧和多任务混合模型的视频异常检测方法及系统。该方法首先使用分段聚类的帧间差分关键帧提取技术,将提取的关键帧作为模型输入,节省了存储空间,提升检测效率。然后,在人体骨骼特征提取的基础上,融合了基于重构的方法和基于预测的方法,构建一个混合模型。并且在多任务学习方面,综合利用历史帧重构和预测未来帧(ftr)、利用未来帧重构和预测历史帧(pst)、利用历史帧和未来帧重构和预测当前帧(prs)。
2、为了实现上述目的,本发明采用以下技术方案:
3、本发明一方面提出一种融合关键帧和多任务混合模型的视频异常检测方法,包括:
4、步骤1:获取视频数据集;
5、步骤2:构建融合关键帧和多任务学习的混合模型;所述混合模型包括关键帧提取模块和基于骨骼的双分支混合模型;所述关键帧提取模块用于提取视频的关键帧;所述基于骨骼的双分支混合模型包括重构和预测两个分支,每个分支均包括人体骨骼提取模块、编码器、记忆模块、记忆增强模块、解码器和卷积注意模块;
6、步骤3:将提取到的关键帧分为历史帧、当前帧和未来帧,以进行多任务学习;
7、步骤4:基于构建的所述双分支混合模型,利用历史帧重构和预测未来帧、利用未来帧重构和预测历史帧、利用历史帧和未来帧重构和预测当前帧;
8、步骤5:基于获取的视频数据集对各任务的双分支混合模型进行训练,从而获得训练好的融合关键帧和多任务学习的混合模型;
9、步骤6:基于训练好的融合关键帧和多任务学习的混合模型,进行视频异常检测。
10、进一步地,所述关键帧提取模块具体用于根据需求对原始视频进行分段和特征提取,然后使用k-means聚类方法进行聚类,将特征向量分成k个簇,其中每个簇都由一个代表性的中心点表示,之后差分图像,计算帧像素强度绝对差值,并根据阈值选择关键帧。
11、进一步地,所述人体骨骼提取模块具体用于利用人体姿态估计算法从输入的视频帧中提取出人体骨骼数据。
12、进一步地,所述编码器的梯度损失为:
13、
14、其中lb是编码器的梯度损失,ti、表示时间位置,z、i分别表示重建位置、真实位置和时间序列,是正类样本对,是软负类样本对,是硬负类样本对,γ是一个边界超参数。
15、进一步地,所述记忆模块中,使用softmax函数计算记忆寻址权重:
16、
17、其中ri表示第i行记忆矩阵的记忆寻址权重,si为第i行记忆矩阵的记忆存储,n为记忆矩阵的行数,y为编码特征向量,d(·)是一种近似值度量的方法。
18、进一步地,所述记忆增强模块包括自注意力模块和特征投影模块,所述特征投影模块用于将输入数据映射到另一个空间的操作。
19、进一步地,当输入为历史帧时,所述解码器的损失为:
20、
21、其中ld表示解码器的损失,t表示时间步数,ti、t表示时间位置,和分别表示预测的未来帧和真实的未来帧。
22、进一步地,所述多任务学习的最终损失为:
23、l=lb+λld
24、其中,l是多任务学习的最终损失,lb是编码器的梯度损失,ld是解码器的损失,λ是一个超参数,根据骨骼关节点和边界框角轨迹进行调整。
25、本发明另一方面提出一种融合关键帧和多任务混合模型的视频异常检测系统,包括:
26、视频数据集获取单元,用于获取视频数据集;
27、混合模型构建单元,用于构建融合关键帧和多任务学习的混合模型;所述混合模型包括关键帧提取模块和基于骨骼的双分支混合模型;所述关键帧提取模块用于提取视频的关键帧;所述基于骨骼的双分支混合模型包括重构和预测两个分支,每个分支均包括人体骨骼提取模块、编码器、记忆模块、记忆增强模块、解码器和卷积注意模块;
28、关键帧划分单元,用于将提取到的关键帧分为历史帧、当前帧和未来帧,以进行多任务学习;
29、多任务学习单元,用于基于构建的所述双分支混合模型,利用历史帧重构和预测未来帧、利用未来帧重构和预测历史帧、利用历史帧和未来帧重构和预测当前帧;
30、混合模型训练单元,用于基于获取的视频数据集对各任务的双分支混合模型进行训练,从而获得训练好的融合关键帧和多任务学习的混合模型;
31、视频异常检测单元,用于基于训练好的融合关键帧和多任务学习的混合模型,进行视频异常检测。
32、与现有技术相比,本发明具有的有益效果:
33、1.使用基于k-means分段聚类的帧间差分关键帧提取技术,该方法通过分段聚类和差分图像计算帧像素强度绝对差值来提取关键帧,在人体识别中具有较少冗余信息,更好的表征和泛化,提高鲁棒性,计算效率高等优势。因此使用此方法对原始视频帧进行关键帧提取,并作为模型的输入,可以降低实际应用中的内存消耗并提高视频异常检测的效率。
34、2.在关键帧提取的基础上,提取人体骨骼数据,并构建基于重构方法和预测方法的混合模型,有效解决了重构方法和预测方法异常数据误判率较高和有易受环境噪声影响的问题,通过混合模型综合利用多源信息,结合两种方法的优势,提高模型的实用性、准确率。
35、3.基于混合模型的多任务异常检测方法,即综合利用历史帧重构和预测未来帧、利用未来帧重构和预测历史帧、利用历史帧和未来帧重构和预测当前帧。采用多任务学习的方法,挖掘丰富的时序信息,弥补以往采用单一时序片段检测方式漏检和准确率低的问题,全面捕捉异常信号,增强异常检测的预测能力。
本文地址:https://www.jishuxx.com/zhuanli/20250110/353674.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。