基于部分连通可微架构搜索和残差自编码器的合成语音检测方法
- 国知局
- 2024-06-21 10:38:31
本发明涉及合成语音检测,具体涉及基于部分连通可微架构搜索和残差自编码器的合成语音检测方法。
背景技术:
1、自动说话人验证系统asv是一种依托声纹特征开发的系统,广泛应用于各种现实场景,如银行、社交网络和智能家居等。然而,随着合成语音技术的迅速发展,相关的攻击问题也在不断涌现。合成语音技术包括文字转语音和语音转换,这类攻击会被用于非法获取目标用户的访问权限,对基于语音的安全访问控制系统带来严重威胁。因此,为保护asv系统免受欺骗攻击,检测合成语音技术变得十分必要和紧迫。
2、现有的合成语音检测模型通常由前端特征提取函数和后端模型分类器组成,存在着模型对未知语音攻击识别能力较差的问题。在合成语音检测任务中,常用的特征提取方法多数是依据专家经验手工设计的特征提取函数,而使用依赖经验设计的手工制作特征会丢失大部分语音信息。后端分类模型的设计也十分重要,但现有模型的网络架构通常依据专家经验手动设计,其需要消耗大量时间和资源寻找手动设计的网络架构最优解。合成语音检测任务常用的多任务学习训练策略也存在着问题,即在现实情况下,难以获取标注数据。因此,设计一个能有效保留原始语音信息、自动设计网络架构、有着较高识别能力的合成语音检测模型是亟待解决的问题。现有技术通常从以下两个方面对合成语音检测模型进行改进:
3、(1)基于手动设计的后端分类网络架构。例如使用res2net网络作为分类器,该网络在一个块内的不同特征组之间设计了一个类似残差的连接,这增加了可能的接受域,有助于模型更好地检测未知攻击。又如一种新的深度神经网络架构称为to-rawnet,该架构结合了正交卷积和tcn的优点,对rawnet2进行了改进。上述基于手动设计的后端分类网络架构通常依据专家经验,因此优化网络架构以及寻找网络架构的最优解需要消耗大量时间和资源,并且这是一个长期的试错过程。
4、(2)基于多任务学习的训练策略。例如基于多任务学习方法,设计了合成语音伪造类型分类任务,提升了检测模型的性能。又如设计三个辅助任务提升resnet主任务网络的检测性能。上述方式通常依赖标注数据,也就说需要提供任务标签,而在现实生活中,数据的标签难以获取或者需要花费时间和金钱对数据进行标注。
技术实现思路
1、本发明的目的在于,提出一种合成语音检测方法,其基于pc-darts寻找合成语音检测模型的最优架构以节省时间开销,并设计cfa模块进一步改进pc-darts由于部分通道连接方法导致的网络学习能力差的问题。
2、为实现上述目的,本申请提出的基于部分连通可微架构搜索和残差自编码器的合成语音检测方法,包括:
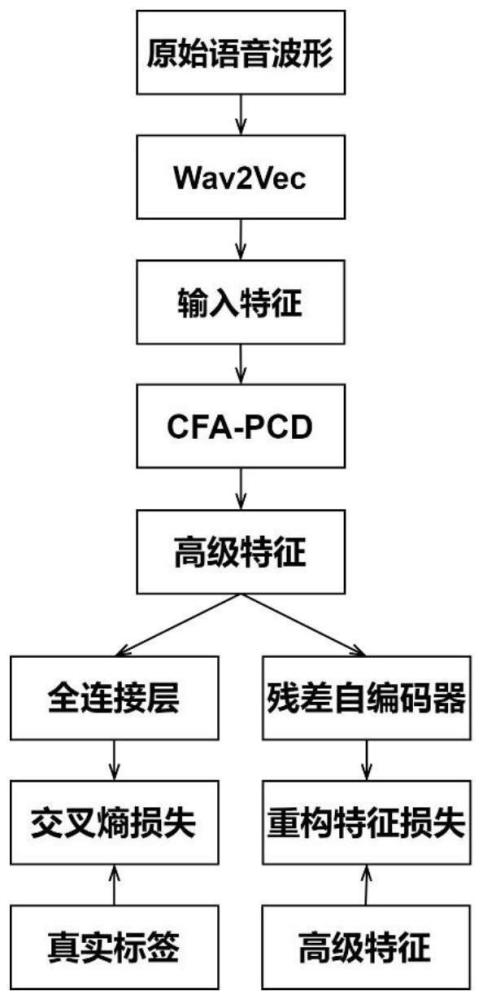
3、使用wav2vec预训练模型对原始语音波形进行特征提取,得到合成语音检测模型cfa-pcd的输入特征;
4、所述合成语音检测模型cfa-pcd对输入特征进行学习,得到真实语音与合成语音之间的差异性特征,然后将学习到的差异性特征输入至全连接层得到分类结果,通过分类结果与分类标签获取训练损失;
5、通过rae网络对所述差异性特征进行重构,并得到特征重构损失;将训练损失和特征重构损失进行加权融合并使其最小化,对合成语音检测模型cfa-pcd更新以促进学习更加泛化的特征。
6、进一步地,所述合成语音检测模型cfa-pcd的总损失包括训练损失和特征重构损失;
7、所述训练损失lossce,使用交叉熵ce损失函数获取:
8、lossce=ce(yi′,yi) (1)
9、其中,yi′表示模型对输入样本的预测值,yi表示输入样本对应的真伪标签;
10、所述特征重构损失lossfeature,使用l2损失函数获取:
11、lossfeature=l2(fi′,fi) (2)
12、其中,fi′表示rae网络重构的特征,fi表示w2v特征;
13、因此总损失表示loss为:
14、
15、其中,λ是辅助任务的权衡系数。
16、进一步地,所述合成语音检测模型cfa-pcd第一个阶段是架构搜索阶段,使用部分连通架构搜索策略搜索出适用于合成语音检测任务的最优正常细胞和最优还原细胞。
17、进一步地,所述合成语音检测模型cfa-pcd第二个阶段堆叠架构搜索后得到的最优正常细胞和最优还原细胞并形成网络架构,针对合成语音检测任务重新开始训练。
18、进一步地,所述合成语音检测模型cfa-pcd第二个阶段的每个最优正常细胞、最优还原细胞后添加cfa模块,以学习全局信息。
19、更进一步地,所述cfa模块包括挤压激励块se和特征注意力块fa;所述挤压激励块se用于确定通道之间的相互依赖性,自适应地重新校准通道特征响应;这种相互依赖性为通道分配了不同的影响权重;所述特征注意力块fa在通道注意力向量的基础上再次进行特征维度的注意力加权,以标记出特征图上的重要信息。
20、更进一步地,所述cfa模块中输入特征fi首先经过挤压激励块se以及跳跃连接得到通道注意力向量fc,如下式所示:
21、fc=se(fi)+fi (4)
22、然后,特征注意力块fa对通道注意力向量fc进行特征注意力操作,抑制特征图中和判别特征无关的信息;在特征注意力块fa中沿着通道维度使用avgpool函数对通道注意力向量fc特征进行挤压操作得到特征向量favg,接着进行7*7的二维卷积以及sigmoid激活得到特征注意力矩阵fatt,然后与通道注意力向量fc相乘得到特征注意力向量ffa,最后经过跳跃连接得到通道特征注意力向量fcf,如式(5)所示:
23、
24、更进一步地,所述rae网络先使用全连接层fc对差异性特征进行重构得到升维后的特征。
25、作为更进一步地,所述rae网络分为四层,其第一层包括三个rae架构块,其对升维后的特征进一步扩充;第二层包括一个rae架构块和一个上采样函数;第三层包括两个rae架构块和一个上采样函数;第四层包括三个rae架构块和一个上采样函数;第二层、第三层、第四层对特征降维并进行上采样,得到与输入特征维度一致的重构特征。
26、作为更进一步地,所述上采样函数使用双线性插值方法对特征进行上采样。
27、本发明采用的以上技术方案,与现有技术相比,具有的优点是:本方法减少了手动设计网络架构对合成语音检测模型的影响,而cfa模块解决了部分连通方法导致的模型学习能力不足问题,关注了特征中更有用的信息,提升模型对输入特征的学习能力。本发明将预训练模型wav2vec和cfa-pcd模型联合使用,减少了手动调参对模型性能的影响。基于多任务学习方法设计多任务模型框架,通过rae辅助任务进一步提升了cfa-pcd对未知语音攻击的识别能力。
技术特征:1.基于部分连通可微架构搜索和残差自编码器的合成语音检测方法,其特征在于,包括:
2.根据权利要求1所述基于部分连通可微架构搜索和残差自编码器的合成语音检测方法,其特征在于,所述合成语音检测模型cfa-pcd的总损失包括训练损失和特征重构损失;
3.根据权利要求1所述基于部分连通可微架构搜索和残差自编码器的合成语音检测方法,其特征在于,所述合成语音检测模型cfa-pcd第一个阶段是架构搜索阶段,使用部分连通架构搜索策略搜索出适用于合成语音检测任务的最优正常细胞和最优还原细胞。
4.根据权利要求3所述基于部分连通可微架构搜索和残差自编码器的合成语音检测方法,其特征在于,所述合成语音检测模型cfa-pcd第二个阶段堆叠架构搜索后得到的最优正常细胞和最优还原细胞并形成网络架构,针对合成语音检测任务重新开始训练。
5.根据权利要求4所述基于部分连通可微架构搜索和残差自编码器的合成语音检测方法,其特征在于,所述合成语音检测模型cfa-pcd第二个阶段的每个最优正常细胞、最优还原细胞后添加cfa模块,以学习全局信息。
6.根据权利要求5所述基于部分连通可微架构搜索和残差自编码器的合成语音检测方法,其特征在于,所述cfa模块包括挤压激励块se和特征注意力块fa;所述挤压激励块se用于确定通道之间的相互依赖性,自适应地重新校准通道特征响应;这种相互依赖性为通道分配了不同的影响权重;所述特征注意力块fa在通道注意力向量的基础上再次进行特征维度的注意力加权,以标记出特征图上的重要信息。
7.根据权利要求6所述基于部分连通可微架构搜索和残差自编码器的合成语音检测方法,其特征在于,所述cfa模块中输入特征fi首先经过挤压激励块se以及跳跃连接得到通道注意力向量fc,如下式所示:
8.根据权利要求1所述基于部分连通可微架构搜索和残差自编码器的合成语音检测方法,其特征在于,所述rae网络先使用全连接层fc对差异性特征进行重构得到升维后的特征。
9.根据权利要求8所述基于部分连通可微架构搜索和残差自编码器的合成语音检测方法,其特征在于,所述rae网络分为四层,其第一层包括三个rae架构块,其对升维后的特征进一步扩充;第二层包括一个rae架构块和一个上采样函数;第三层包括两个rae架构块和一个上采样函数;第四层包括三个rae架构块和一个上采样函数;第二层、第三层、第四层对特征降维并进行上采样,得到与输入特征维度一致的重构特征。
10.根据权利要求9所述基于部分连通可微架构搜索和残差自编码器的合成语音检测方法,其特征在于,所述上采样函数使用双线性插值方法对特征进行上采样。
技术总结本发明公开了基于部分连通可微架构搜索和残差自编码器的合成语音检测方法,获取一个具有自动搜索架构功能的、具有较高识别能力的合成语音检测模型;该模型使用Wav2Vec作为特征提取器,基于多任务框架提出了改进的基于CFA模块的PC‑DARTS网络和构建了RAE网络,其中提出的CFA模块旨在解决PC‑DARTS中部分连通方法导致的模型学习能力不足问题,构建的RAE网络迫使CFA‑PCD学习语音的通用特征,防止其过拟合,最终实现了对未知语音攻击的高效识别能力。技术研发人员:张强,赵腊生,程银清受保护的技术使用者:大连大学技术研发日:技术公布日:2024/1/15本文地址:https://www.jishuxx.com/zhuanli/20240618/20876.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表