一种智能语音识别系统
- 国知局
- 2024-06-21 10:38:34
本发明涉及语音识别,具体为一种智能语音识别系统。
背景技术:
1、语音识别是一种技术,它可以将人类语音转换为文本形式。这项技术对于许多应用非常有用,包括语音助手、语音指令和语音转写等。语音识别的工作原理通常涉及以下步骤:录音:使用麦克风或其他录音设备捕获人类的语音输入。声音预处理:对录音进行处理以消除噪音、调整音量等。特征提取:从预处理的声音中提取特征,常用的特征包括音频频谱、梅尔频率倒谱系数(mfcc)等。建模:使用机器学习算法构建一个语音模型,该模型可以根据输入的特征预测相应的文本输出。常见的建模方法包括隐马尔可夫模型(hmm)、深度神经网络(dnn)和长短期记忆网络(lstm)等。解码:根据语音模型的预测结果,使用解码算法将其转换为最终的文本输出。
2、现有的语音采集设备,无法灵活调整角度,对发声位置进行准确采集声音,且杂音量较多时,会导致语音识别效果差,为此提出一种智能语音识别系统。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术不足,本发明提供了一种智能语音识别系统,解决了:现有的语音采集设备,无法灵活调整角度,对发声位置进行准确采集声音,且杂音量较多时,会导致语音识别效果差的问题。
3、(二)技术方案
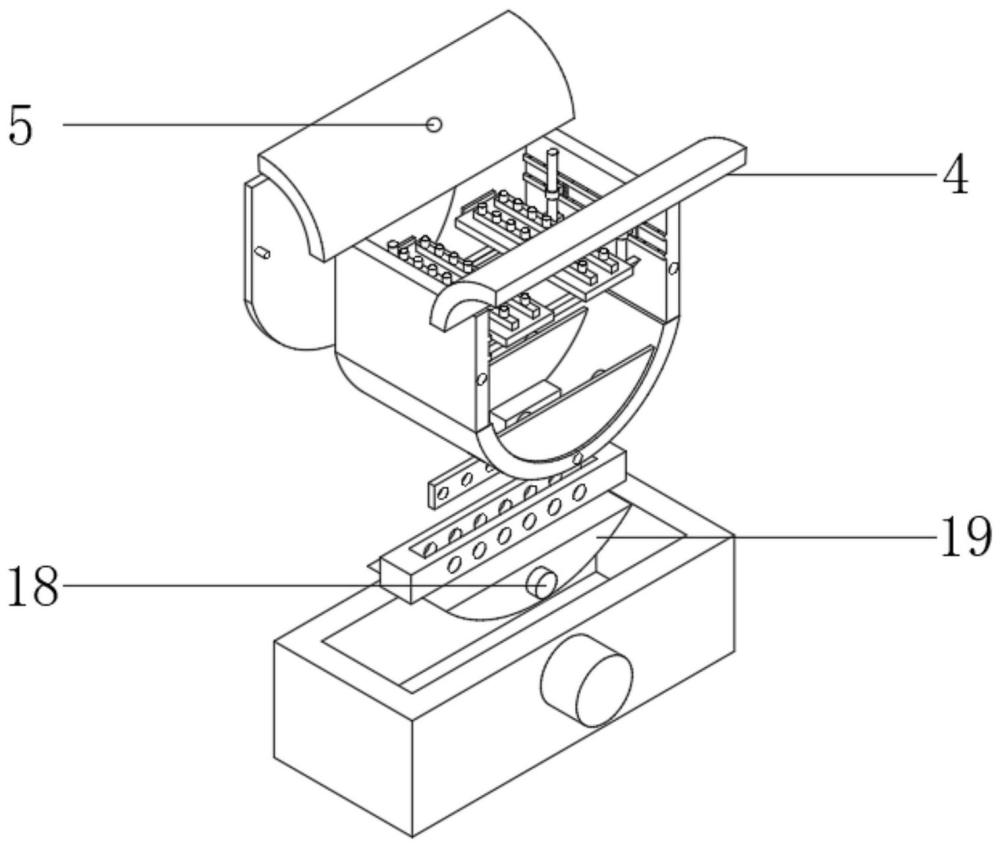
4、为实现以上目的,本发明通过以下技术方案予以实现:一种智能语音识别系统,包括有语音采集结构、设置于语音结构底部且用于调向的收纳框,所述语音采集结构包括有呈u字状的收纳盒,所述收纳盒的正面及背面均可拆式连接有卡盖,位于所述收纳盒的顶端呈敞开式,且收纳盒的顶部对称连接有弧形的导板一,所述导板一上设置有声音传感器,位于所述收纳盒的内部设置有消音结构,且收纳盒的内壁上对称设置有滑槽,所述滑槽中嵌入有两个导向结构,且收纳盒的底端设置有两个呈弧形的挡板,且两个挡板的中间位置处设有主控芯板。
5、作为本发明的进一步优选方式,所述消音结构包括有若干个扣板,且相邻的扣板之间等距设置有间隙,位于所述扣板的顶部对称设置有凸条,所述凸条的顶端等距设置有若干个消音管,若干个扣板的底部连接有卡板,所述卡板的两端与收纳盒内壁相连接。
6、作为本发明的进一步优选方式,所述导向结构包括有滑动块,所述滑动块的外侧连接有轴套,且轴套中插设有导杆,所述导杆的底端连接有铸块,所述铸块向下倾斜且外壁保持光滑。
7、作为本发明的进一步优选方式,所述收纳盒的底端连接有条状的柱条板,所述柱条板上等距开设有若干个安装孔,所述收纳框的外壁上设置有电机,且电机的输出端连接有联动轴,所述联动轴上连接有活动块,位于所述活动块的顶端连接有卡槽框,所述卡槽框与柱条板插接,且卡槽框的外壁等距开设有若干个通孔。
8、作为本发明的进一步优选方式,所述主控芯板包括有预处理模块、深度学习模块、解码器模块、语言模块、网络通讯模块,所述预处理模块、深度学习模块、解码器模块、语言模块、网络通讯模块均相互连通。
9、作为本发明的进一步优选方式,所述预处理模块包括分帧、窗函数处理、快速傅里叶变换(fft)和梅尔频率倒谱系数(mfcc)提取操作,将语音信号转换为可用于深度学习模型输入的特征向量。
10、作为本发明的进一步优选方式,所述深度学习模块,采用深度神经网络(dnn)、卷积神经网络(cnn)、循环神经网络(rnn)或长短时记忆网络(lstm)深度学习模型进行训练,以实现对语音特征向量的自动学习和识别。
11、作为本发明的进一步优选方式,所述语言模块:采用n-gram、循环神经网络语言模型(rnnlm)方法建立语言模型,辅助解码器模块进行文本信息的生成。
12、(三)有益效果
13、本发明提供了一种智能语音识别系统。具备以下有益效果:
14、(1)本发明的智能语音识别系统,通过使用语音采集结构进行采集和转化识别语音,并使用其底部的收纳框进行调整角度方向,收纳盒的底端连接有条状的柱条板,柱条板上等距开设有若干个安装孔与底部的卡槽框进行插接快速安装,收纳框的外壁上设置有电机,声音传感器检测到声音来源,启动电机带动联动轴和活动块转动,从而促使整个卡槽框上的语音采集结构进行调向,对准声音方向进行采集。
15、(2)本发明的收纳盒的顶部对称连接有弧形的导板一,可以将声音导入至收纳盒的内部,并且收纳盒的内部设置有消音结构,消音结构采用有若干个扣板,且相邻的扣板之间等距设置有间隙,扣板的顶部对称设置有凸条,使用凸条的顶端的消音管可以将较小的杂音进行吸收,保留较大的声音,且收纳盒的内壁上对称设置有滑槽,滑槽中嵌入有两个导向结构,剩余较大的声音,可以通过铸块进行导向传输扩散,并起到简单扩音效果,从而传输至主控芯板处,然后进行语音转化和识别。
技术特征:1.一种智能语音识别系统,包括有语音采集结构、设置于语音结构底部且用于调向的收纳框(1),其特征在于:所述语音采集结构包括有呈u字状的收纳盒(2),所述收纳盒(2)的正面及背面均可拆式连接有卡盖(3),位于所述收纳盒(2)的顶端呈敞开式,且收纳盒(2)的顶部对称连接有弧形的导板一(4),所述导板一(4)上设置有声音传感器(5),位于所述收纳盒(2)的内部设置有消音结构,且收纳盒(2)的内壁上对称设置有滑槽,所述滑槽中嵌入有两个导向结构,且收纳盒(2)的底端设置有两个呈弧形的挡板(6),且两个挡板(6)的中间位置处设有主控芯板(7)。
2.根据权利要求1所述的一种智能语音识别系统,其特征在于:所述消音结构包括有若干个扣板(8),且相邻的扣板(8)之间等距设置有间隙,位于所述扣板(8)的顶部对称设置有凸条(9),所述凸条(9)的顶端等距设置有若干个消音管(10),若干个扣板(8)的底部连接有卡板(11),所述卡板(11)的两端与收纳盒(2)内壁相连接。
3.根据权利要2所述的一种智能语音识别系统,其特征在于:所述导向结构包括有滑动块(12),所述滑动块(12)的外侧连接有轴套(13),且轴套(13)中插设有导杆(14),所述导杆(14)的底端连接有铸块(15),所述铸块(15)向下倾斜且外壁保持光滑。
4.根据权利要求3所述的一种智能语音识别系统,其特征在于:所述收纳盒(2)的底端连接有条状的柱条板(16),所述柱条板(16)上等距开设有若干个安装孔,所述收纳框(1)的外壁上设置有电机(17),且电机(17)的输出端连接有联动轴(18),所述联动轴(18)上连接有活动块(19),位于所述活动块(19)的顶端连接有卡槽框(20),所述卡槽框(20)与柱条板(16)插接,且卡槽框(20)的外壁等距开设有若干个通孔。
5.根据权利要求1所述的一种智能语音识别系统,其特征在于:所述主控芯板(7)包括有预处理模块、深度学习模块、解码器模块、语言模块、网络通讯模块,所述预处理模块、深度学习模块、解码器模块、语言模块、网络通讯模块均相互连通。
6.根据权利要求5所述的一种智能语音识别系统,其特征在于:所述预处理模块包括分帧、窗函数处理、快速傅里叶变换(fft)和梅尔频率倒谱系数(mfcc)提取操作,将语音信号转换为可用于深度学习模型输入的特征向量。
7.根据权利要求5所述的一种智能语音识别系统,其特征在于:所述深度学习模块,采用深度神经网络(dnn)、卷积神经网络(cnn)、循环神经网络(rnn)或长短时记忆网络(lstm)深度学习模型进行训练,以实现对语音特征向量的自动学习和识别。
8.根据权利要求5所述的一种智能语音识别系统,其特征在于:所述语言模块:采用n-gram、循环神经网络语言模型(rnnlm)方法建立语言模型,辅助解码器模块进行文本信息的生成。
技术总结本发明公开了一种智能语音识别系统,包括有语音采集结构、设置于语音结构底部且用于调向的收纳框,所述语音采集结构包括有呈U字状的收纳盒,所述收纳盒的正面及背面均可拆式连接有卡盖,位于所述收纳盒的顶端呈敞开式,且收纳盒的顶部对称连接有弧形的导板一,所述导板一上设置有声音传感器,位于所述收纳盒的内部设置有消音结构,且收纳盒的内壁上对称设置有滑槽,所述滑槽中嵌入有两个导向结构,且收纳盒的底端设置有两个呈弧形的挡板,且两个挡板的中间位置处设有主控芯板。本发明可以配合声音传感器灵活调整方向,同时可以滤除较多杂音,提高语音识别的准确度。技术研发人员:李守军,郑清青受保护的技术使用者:宿迁学院技术研发日:技术公布日:2024/1/15本文地址:https://www.jishuxx.com/zhuanli/20240618/20885.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。