基于交互注意力机制的多级声学信息的语音情感识别方法
- 国知局
- 2024-06-21 11:29:54
本发明涉及计算机语音识别,具体为一种基于交互注意力机制的多级声学信息的语音情感识别方法。
背景技术:
1、语音情感的应用广泛,可以帮助人类去判断因情感所导致的不必要风险的发生;近年来,随着工作的压力增大,抑郁症成为越来越值得关注的病症。语音情感识别旨在通过情感识别,分析用户现有的情感,一旦发现抑郁症相关的情感时,及时介入,达到预防的目的。此外,还有更多的研究者会在语音情感与其他的方面,比如文字、视频等进行融合,以得到应用。但是,目前更多的研究专注于多模态情感识别,这就必须有一个文本或视频的输入,会使得语音情感识别变得更为复杂。语音中包含音色、音调、音素等多方面的特征,通过对以上信息的整合,对语音进行单模态识别,亦是一种有效的获取语音情感信息的方法。
2、随着人工智能和机器学习技术的不断发展,越来越多的研究者开始关注语音情感识别领域的研究。在传统的语音情感识别中,判别性特征的提取已经成为了一个非常重要的研究方向。然而,在情感特征提取过程中,存在一些不相关的噪声,这些噪声可能存在多种来源,如背景噪声、说话人的呼吸声等。这些不相关的因素会使提取的特征包含这些因素的变化,从而影响情感分类的效果。研究表明可以通过机器学习的语音情感识别模型达到良好的效果。
3、目前,将语音识别和语音情感识别相结合的场景有很多,这些应用场景包括客服、语音助手,亦可以帮助管理员做作业的安全管控等措施。但目前更多的技术聚焦于多模态的研究,即需要文字或视频作为输入一同与语音进行识别,这样会造成对语音识别时的复杂化以及资源的浪费,降低识别性能。
技术实现思路
1、针对现有技术的不足,本发明提出了一种基于交互注意力机制的多级声学信息的语音情感识别方法,通过多级声学信息的综合利用和交互式注意力机制的引入,提高了语音情感识别的性能,使其在实际应用中更加有效和可靠。
2、本发明为解决其技术问题所采用的技术方案是:
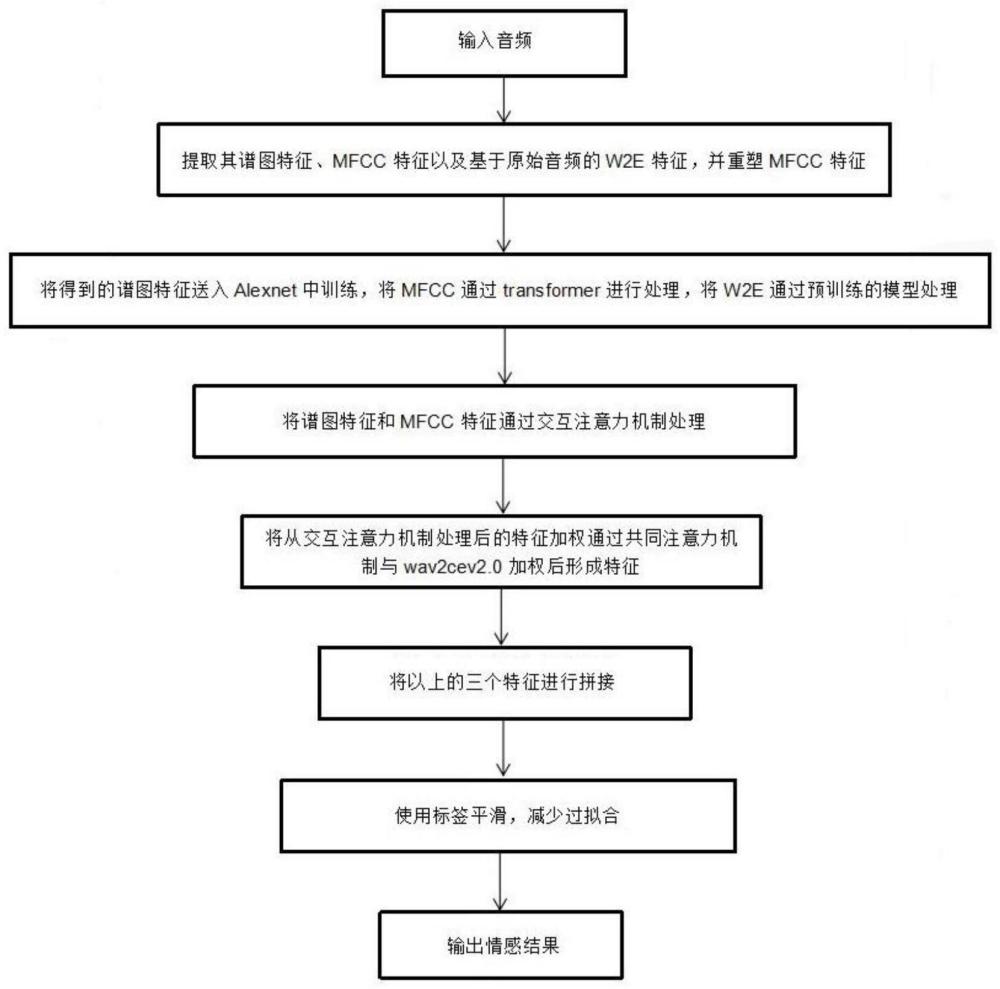
3、一种基于交互注意力机制的多级声学信息的语音情感识别方法,步骤包括:
4、s1、将语音情感数据集区分训练集与测试集,并对训练集和测试集进行特征提取,所述特征包括基于卷积神经网络cnn的谱图特征、梅尔频率倒谱系数mfcc特征和高级声学信息w2e特征;
5、s2、设计包含transformer模块和交互式注意力机制模块的用于多级声学信息的网络模型;对提取的谱图特征、mfcc特征和w2e特征进行特征处理;
6、s3、将特征处理后的谱图特征、mfcc特征输入至交互式注意力机制模块进行融合处理;
7、s4、将交互式注意力机制模块输出的处理后的谱图特征和mfcc特征与特征提取的w2e特征加权,并通过共同注意力机制模块形成最终的wav2vec2.0特征;
8、s5、将步骤s2得到的经过网络处理后的谱图特征、mfcc特征以及步骤s4得到的最终的wav2vec2.0特征进行拼接处理,形成最终的网络模型;
9、s6、利用训练集对步骤s5形成的最终的网络模型进行训练;
10、s7、利用测试集对步骤s6训练后的网络模型进行调整;
11、s8、将待识别的音频数据输入至步骤s7调整后的网络模型,对待识别的音频数据进行情感识别。
12、通过上述方法构建一个进行语音情感识别的网络模型,使用多级声学信息的融合处理识别,获取最终的情感,充分利用信息之间的相关性,从而提高任务的性能,交互式注意力机制的引入能够有效提高网络的特征表达能力,提高语音情感识别精度。
13、进一步的,步骤s1具体包括:
14、s11、将语音情感数据集按照十折交叉验证的方式区分训练集与测试集,将训练集与测试集中的音频等分为每段3秒的音频,不足3秒的音频进行填充处理;
15、s12、对每段音频通过卷积神经网络cnn提取其谱图特征;
16、s13、对每段音频提取其mfcc特征,并对提取后的mfcc特征进行张量重塑和排序;
17、s14、对每段音频提取其w2e特征。
18、通过上述方法可以将多级声学信息特征提取,提取后的特征以便送入网络中学习处理。十折交叉验证的方式可以增加数据的有效使用,每个样本都有机会出现在测试集和训练集中,有助于更全面地评估模型的性能;将音频等分为3秒的段落以及填充处理有助于使数据集更加均匀,避免数据不平衡问题。卷积神经网络(cnn)提取谱图特征,有助于捕捉音频中的频谱信息,包括声音的频率和强度分布,从而为情感识别提供更丰富的声学特征。mfcc特征提取对有助于捕捉音频的语音特征,张量重塑和排序可以将时间步和特征维度分开,有利于在不同的维度下独立地处理这些特征。提取w2e特征可以捕捉更高级的声学信息,有助于提高情感识别的性能,因为它可以包括音频中的语义和情感信息。这些细分步骤有助于准备丰富、均匀的声学特征数据,为后续的情感识别模型提供了更多有用的信息和更好的性能,提高情感识别系统的准确性和鲁棒性。
19、进一步的,步骤s2具体包括:
20、s21、对步骤s12中所提取的谱图特征通过alexnet神经网络进行特征处理;
21、s22、对步骤s13中张量重塑和排序后的mfcc特征通过transformer模块进行特征处理;
22、s23、对步骤s14中所提取的w2e特征通过wav2vec2.0模型进行特征处理。
23、通过使用这些方法,可以对提取的信息进行进一步的处理和学习,从而能够从多级声学信息中学习和理解更复杂的特征,更好地理解声音的特性。通过alexnet神经网络对谱图特征进行特征处理,可以进一步提取和加工谱图特征的抽象表达,有助于提高特征的表征能力和区分度,增强模型对谱图特征的理解。利用transformer模块对mfcc特征进行处理,能够捕捉mfcc特征中的长期依赖关系和重要的时序信息。transformer模块具有良好的序列建模能力,有助于更好地表示mfcc特征。通过wav2vec2.0模型对w2e特征进行处理,可以进一步提取高级声学信息,包括语义和情感特征,提高模型对语音信号的理解能力。通过不同的神经网络模型对各类声学特征进行特征处理,有助于提取更高层次的抽象特征,增强模型对不同特征的理解能力,从而提高情感识别模型的性能和准确度。这种细致的特征处理有助于使模型更具有表现力和泛化能力,使其更适用于多种情感识别任务。
24、进一步地,所述的mfcc特征进行张量重塑,具体为:
25、mfcc特征输入张量tinput,其维度为b*n*w*d;接下来定义一个新的张量toutput,同时,定义一个映射函数f:(i,j,k,l)→(i′,j′,k′,l′),将输入张量中的元素索引映射到新的张量元素上,具体来说,映射函数定义为:
26、i′=i
27、j′=j
28、
29、l′=(j-1)mod n+1
30、通过这个映射函数,将输入张量重新排列为新的张量,具体来说,新的张量中元素t′i′j′k′l′
31、通过以下方式计算:
32、t′i′j′k′l′=tijkl
33、其中(i′,j′,k′,l′)=(i,j,k,l)。
34、进一步的,将张量重塑后形成的mfcc特征值,按照时间步维度和特征维度区分,重新排序,使网络模型在不同的维度上独立处理特征。
35、进一步的,步骤s3具体包括:
36、s31、交互式注意力机制模块通过其线性层将输入维度转换为目标维度;
37、s32、利用softmax函数将注意力分数转换为概率分布;
38、s33、将概率分布应用于输入。
39、通过使用这些方法,能够有效地调整输入的权重,使得模型能够动态地关注输入序列中不同部分的信息,从而提高了对关键特征的感知和利用能力,这种交互式注意力机制有助于改进模型的表达能力和整体性能。通过线性层将输入维度转换为目标维度,确保注意力机制模块能够处理输入的维度,使得输入能够有效地与后续处理步骤相结合;线性层可以映射输入特征到一个更有助于注意力计算的空间。通过softmax,将注意力分数映射到概率分布上,确保所有分数在0到1之间,且和为1,以便有效地表示相对权重,softmax函数强调了注意力机制中分数较高的部分,使得模型更专注于重要的输入信息。将概率分布应用于输入相当于对输入进行加权,更关注具有高概率的部分,有助于提高模型对关键信息的敏感性。将概率分布应用于输入,模型能够在整个输入序列上建立上下文关系,有助于更全面地理解和利用输入信息。
40、进一步的,所述的交互式注意力机制模块包含线性层、注意力层、计算模块以及分数;在后续输入过程中通过加权相乘的方式进行使用;
41、首先,通过一个线性层将输入的维度从input_dim转换为attention_dim,这个线性层用
42、一个权重矩阵w和一个偏置向量b来表示;对于input_1,其线性变换表示为:
43、z1=w·input1+b
44、其中,w的维度为(attention_dim,input_dim),b的维度为attention_dim;
45、同样地,对于input_2,其线性变换表示为:
46、z2=w·input2+b
47、然后,将z1和z2拼接在一起,得到一个新的向量z:
48、z=[z1;z2]
49、其中,z的维度是2*attention_dim;
50、接下来,使用softmax函数将这些注意力分数z转换为概率分布p:
51、p=softmax(z)
52、softmax函数转换为概率分布,其计算公式为:
53、
54、其中:xi表示拼接后z的第i个元素;xj表示拼接后z的第j个元素;n表示向量z的维度;
55、最后,将概率分布p应用于输入:其中概率分布p包含两部分:p1和p2,它们分别对应于input_1和input_2;进行加权得到加权向量atts,这个加权向量综合考虑了input_1和input-2的重要性;
56、atts=p1input1+p2input2。
57、通过引入交互注意力机制,可以深度关注两个来自同一段语音的频域特征之间的关系,这种关注使得模型能够更好地理解和利用这些特征,从而在语音处理效果上实现显著提升。
58、进一步的,步骤s5中将拼接处理后的特征通过标签平滑机制形成最终的网络模型。
59、通过引入标签平滑机制,可以提高模型的泛化能力、鲁棒性,降低过拟合的风险,从而使最终的网络模型更适应于实际应用场景,并在各类别间保持了良好的平衡与稳定性。
60、本发明的有益效果包括:
61、综合特征提取:通过使用卷积神经网络(cnn)的谱图特征、梅尔频率倒谱系数(mfcc)特征和高级声学信息(w2e)特征,该方法能够综合不同类型的声学特征,提供更全面的情感信息。
62、交互式注意力机制:采用交互式注意力机制,能够有效地捕捉不同声学特征之间的关联和互动,从而提高情感识别的性能。
63、多级声学信息:通过设计包含transformer模块的网络模型,能够处理多级声学信息,包括谱图特征、mfcc特征和w2e特征,使得模型更富有表现力。
64、共同注意力机制:引入共同注意力机制,有助于有效融合不同特征,并生成最终的高级声学信息w2e特征,提高了情感识别的准确性。
65、训练和调整:采用训练集对网络模型进行训练,并通过测试集进行调整,可以确保模型在不同数据集上的性能稳定和可靠。
66、情感识别性能:通过上述方法,最终的网络模型能够对待识别的音频数据进行情感识别,提供更准确的情感分类结果。
67、总的来说,这种方法通过多级声学信息的综合利用和交互式注意力机制的引入,提高了语音情感识别的性能,进一步提高了语音情感识别的准确率,使其在实际应用中更加有效和可靠。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21854.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表