基于YOLOv8-Swin-Transformer-BiFPN神经网络的羊脸图像检测方法与流程
- 国知局
- 2024-07-31 22:43:21
本发明涉及畜牧图像识别,具体来说是基于yolov8-swin-transformer-bifpn神经网络的羊脸图像检测方法。
背景技术:
1、当前智慧农业的发展要求农场建设大数据中心和应用系统,并结合智能技术和设备建设监控系统,实现精准化、智能化管理。对个体牲畜的检测和鉴定有很多研究。传统的方法主要有耳部印记、耳部标签和rfid(射频识别)。
2、耳部印记需要全程手工打标,耗费大量人力物力。它会对牲畜造成更大的生理损伤,并引发应激反应,严重时可能导致牲畜暴力。耳标造成的损害相对较小,但在实际应用中发现,耳标的使用会导致牲畜对某些疾病的易感性增加,耳标很容易损坏和丢失。射频技术可以使用无线电波根据编号信息识别和跟踪目标,但成本高昂,鲁棒性较差。同时,在山羊和绵羊的精准养殖中,实时快速准确地识别动物是进一步分析其健康状况、行为信息和面部表情的基础,也是产品追溯、计划实施等管理工作的重要组成部分。但是,基于自然环境中颜色和纹理相似的纯色山羊和绵羊的外观特征,导致羊头检测存在较大困难。
3、因此,如何利用图像识别技术进行羊脸面部的准确识别已经成为急需解决的技术问题。
技术实现思路
1、本发明的目的是为了解决现有技术中难以针对羊群面部进行精准识别的缺陷,提供一种是基于yolov8-swin-transformer-bifpn神经网络的羊脸图像检测方法来解决上述问题。
2、为了实现上述目的,本发明的技术方案如下:
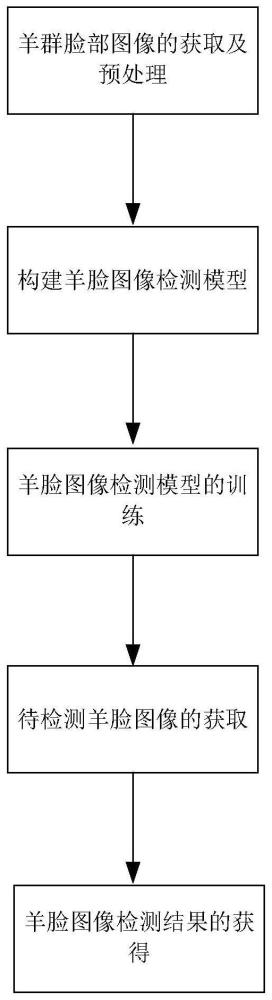
3、一种基于yolov8-swin-transformer-bifpn神经网络的羊脸图像检测方法,包括以下步骤:
4、羊群脸部图像的获取及预处理:利用移动摄像设备在牧场拍摄不同尺寸、角度、密度的羊群脸部图像,并进行数据预处理;
5、构建羊脸图像检测模型:基于yolov8基础框架构建羊脸图像检测模型;
6、羊脸图像检测模型的训练:将预处理后的羊群脸部图像输入羊脸图像检测模型进行训练;
7、待检测羊脸图像的获取:获取待检测羊脸图像并进行预处理;
8、羊脸图像检测结果的获得:将预处理后的待检测羊脸图像输入训练后的羊脸图像检测模型,获得羊脸图像检测结果。
9、所述构建羊脸图像检测模型包括以下步骤:
10、基于yolov8基础框架构建羊脸图像检测模型,将羊脸图像检测模型设定为四层:
11、第一层为input:输入图像size为640×640的图片,通过cbl模块扩充通道,缩小特征图,提取深层特征;
12、第二层为backbone:
13、backbone网络骨干包括conv、c2f结构和sppf模块,conv表示卷积层,其参数指定输出通道数、卷积核大小和步长;c2f结构具有更丰富的梯度流,并对不同尺度模型调整不同的通道数,用于提高网络计算速度并降低内存消耗;sppf模块是具有残差结构的连续三次最大池化,最后将池化前和每次池化后的结果concat;
14、第三层为neck:
15、neck部分定义了模型的检测头,用于最终目标检测,采用upsample+concat+c2f的检测结构,upsample表示上采样层,用于放大特征图,concat表示连接层,用于合并来自不同层的特征,c2f层再次出现,用于进一步处理合并后的特征;
16、第四层为detect:
17、detect层是最终的检测层,负责输出检测结果;利用bbox损失函数计算差异,通过计算均方误差mse预测边界框和真实边界框之间的差异,引导模型在训练过程中减少预测框和真实框之间的差距;
18、在第二层backbone最后一个c2f模块末端加入swin-transformer模块;
19、设定swin-transformer特征提取模块包含两个子模块,分别是窗口多头自注意力机制w-msa和滑动窗口多头自注意力机制sw-msa,每个子模块均包含两个归一化层、一个注意力模块和一个mlp层,并使用了残差连接;
20、w-msa的方法为将图层划分为不重叠的窗口,在各自窗口中计算自注意力,sw-msa则引入了滑动窗口,在窗口滑动的同时进行移动填补,实现窗口之间的信息交互,提升了感受野的作用,注意力attention(q,k,v)计算如下:
21、q=fq(x),k=fk(x),v=fv(x)
22、
23、式中:x为特征图,fq(·)、fk(·)、fv(·)为线性变换函数,q、k、v称为查询向量、键向量、值向量,b为相对位置偏差,dk为输入数据维度,kt为键向量的转置;
24、在第三层neck层融入bifpn模块,实现对骨干的多层特征图进行加权组合,
25、设定bifpn特征融合模块:
26、设定的bifpn采用双向跨尺度连接,在自顶向下和自底向上路径之间建立双向连接,允许不同尺度特征间的信息流动和融合;
27、设定的bifpn采用加权融合机制,为每个输入添加一个额外的权重,并让网络学习每个输入特征的重要性,
28、o=∑iωi·ii
29、式中:o为加权融合后的输出特征,ωi为权重,ii为输入特征;
30、设定的bifpn通过移除只有一个输入边的节点、添加同一层级的输入输出节点之间的额外边,并将每个双向路径视为一个特征网络层,来优化跨尺度连接。
31、所述羊脸图像检测模型的训练包括以下步骤:
32、搭建python=3.9.0、cuda=10.2版本的pytorch神经网络训练环境;
33、设置图像输入尺寸为640×640,标置信度阈值为0.5,初始学习率为0.01,权重衰减系数为0.0005,模型训练批量尺寸batch size为8,训练迭代周期epoch为500,动量0.937,sgd作为优化器;
34、将羊群头部图像输入羊脸图像检测模型,训练完成并生成权重文件:
35、第一层input输入端基于mosaic数据增强方式,选择图像色度、饱和度、亮度随机调整,以及图像翻转、错切、缩放、平移数据增强方法,并按照概率转换成的单幅图像缩放至640×640标准尺寸作为每次的输入图像,并送入第二层;
36、第二层backbone骨干层,
37、首先利用其focus对图片进行切片操作,将羊脸特征信息送入通道空间;然后对输入图像特征进行若干卷积操作,再通过csplaver层和swin-transformer模块进行特征提取;最终通过sppf模块进行快速的金字塔池化,完成主干网络部分的特征提取,sppf模块通过具有残差结构的连续三次最大池化多尺寸特征图转化为neck层输入的固定大小特征图和特征向量;
38、第三层neck层,
39、使用bifpn模块替换panet模块,将backbone骨干层不同阶段输出的特征,通过自下而上部分对两个特征图进行融合和自上而下部分采用三个特征图和两个特征图进行融合的方式,使得网络捕捉不同大小目标,提升整体的性能;
40、将neck层的输出转换为预测的边界框和类别概率,利用bbox损失函数计算差异,通过计算均方误差mse预测边界框和真实边界框之间的差异,引导模型在训练过程中减少预测框和真实框之间的差距;每八次训练完成后计算精度并生成权重文件;
41、循环上述步骤,五百次迭代,训练完成后,生成平均精度和各项评价指标,并在所有权重文件中保留最佳权重文件用于羊脸图像脸部的检测识别。
42、有益效果
43、本发明的基于yolov8-swin-transformer-bifpn神经网络的羊脸图像检测方法,与现有技术相比针对视图小、遮挡、光线、背景复杂等环境因素干扰,以及多个羊头重叠时存在着的漏检、误检,采用改进的yolov8模型进行羊脸目标检测,在主干网络中融入swin-transformer模块,增强模型捕获全局信息及排除干扰因素的能力,同时利用bifpn网络对主干网路提取的不同特征图进行多尺度特征融合,提出了yolov8-swin-transformer-bifpn模型。本发明可快速有效地对复杂场景下羊的脸部进行精准检测及定位。
44、实验结果表明,改进后的模型在平均精度(map)和每秒帧数(fps)方面都有显著提升,同时参数量也大幅减少。该模型成功实现了对羊脸、多目标、小目标以及在复杂环境下的检测。结合swin transformer和bifpn的yolov8模型在羊脸检测任务上能够提供较高的准确率和实时性能,同时也表现出了良好的鲁棒性。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194297.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表