一种基于程序分析的跨过程错误处理代码识别方法
- 国知局
- 2024-07-31 22:43:23
本发明涉及大型软件中的缺陷检测领域,具体涉及一种基于程序分析的跨过程错误处理代码识别方法。
背景技术:
1、随着时间的发展,软件由最初的科学与工程计算工具发展成了如今多种多样的应用,人类越来越依赖各种软件,自然而然地,软件的安全问题也越发被重视。错误处理(error handling,eh)作为软件正常运行的保障,是软件的重要组成部分,也是衡量软件质量的一个重要指标。软件在运行过程中出现错误时,需要进行错误处理及时地将软件恢复正常运行或是停止软件运行,防止造成严重的损失,保障生产生活有序进行。但是当软件的错误处理代码出现问题时(error handling bug,eh bug),软件无法对在运行过程中出现的错误(如数组越界、空指针引用等)进行处理,这可能会导致软件崩溃等严重后果。
2、对软件中的eh bug进行检测已成为一个重要的研究课题,但目前仍然存在错误处理代码识别不完整不准确的问题。当软件的代码规模较小时,尚能利用人工来检测eh bug,但随着软件的代码行数不断增加,传统的人工检测的方式变得不可行。当前的大量工作利用软件内已有的错误处理代码,结合机器学习或数据挖掘的方法,通过学习这些错误处理代码的特征,得到相应的规则,接着利用这些学习到的规则帮助检测eh bug,若符合相应的规则,则表明软件错误处理代码不存在bug,相反软件则可能存在eh bug。因此,为了提高检测eh bug的准确性,在现有工作第一步,即识别软件中已有的错误处理代码时,对错误处理代码的识别提出了极高的要求:首先是高准确性,要确保识别的代码是真实的错误处理代码,而不是一些与错误处理代码相似的其它代码,否则将会影响后续学习规则;其次是完整性,识别的代码需要完整,不完整的错误处理代码可能会缺少重要信息,对规则的学习造成影响。
3、软件内的错误处理通常是跨过程的,即从错误的发生到错误被处理往往会经过多个函数,然而,传统的基于机器学习和数据挖掘的eh bug检测工作在第一步识别软件中已有的错误处理代码时通常只关注错误处理代码的执行部分,例如log函数和print函数,而忽略了错误产生的根源和错误在软件中的传播路径。尽管现有工作通过学习部分错误处理代码,即错误处理代码的执行部分,能够得到不错的结果,但软件中仍有部分eh bug无法被检测出,同时也会导致软件中一些正确的代码被误判为eh bug。如果不改进错误处理代码的识别方式,这些误报和漏报将难以避免。
4、因此,如何设计一种能够跨过程对错误处理代码进行识别的方法对提高当前ehbug检测的准确率具有重要意义,目前还没有公开技术方案涉及跨过程对错误处理代码进行识别的技术方案。
技术实现思路
1、本发明要解决的技术问题是针对目前错误处理代码识别不完整不准确导致ehbug检测的准确率较低这一问题,提供一种基于程序分析的跨过程错误处理代码识别方法。本发明利用开源工具srcml,对软件代码进行分析,通过分析变量的赋值关系,逆向识别并收集错误处理代码。
2、为解决上述技术问题,本发明的技术方案为:首先,构建跨过程错误处理代码识别系统,跨过程错误处理代码识别系统由代码预处理模块、错误处理分支定位模块、错误关键变量判定模块、错误传播路径追踪模块构成;然后,代码预处理模块读入待检测代码文件m,对m进行预处理,得到标准化代码文件a、a的程序分析文件b、a的变量使用和赋值关系表c、函数范围表d;错误处理分支定位模块读入a和b,根据关键字识别定位错误处理分支,生成错误处理分支集合s和错误处理语句列表r;错误关键变量判定模块读入错误处理分支集合s和变量使用和赋值关系表c,通过比较错误处理分支集合s与变量使用和赋值关系表c,得到错误关键变量集合t;最后,错误传播路径追踪模块根据错误关键变量集合t、错误处理分支集合s、错误处理语句列表r、文件a、文件c和函数范围表d对错误传播路径进行追踪,得到错误处理代码h。
3、本发明包括以下步骤:
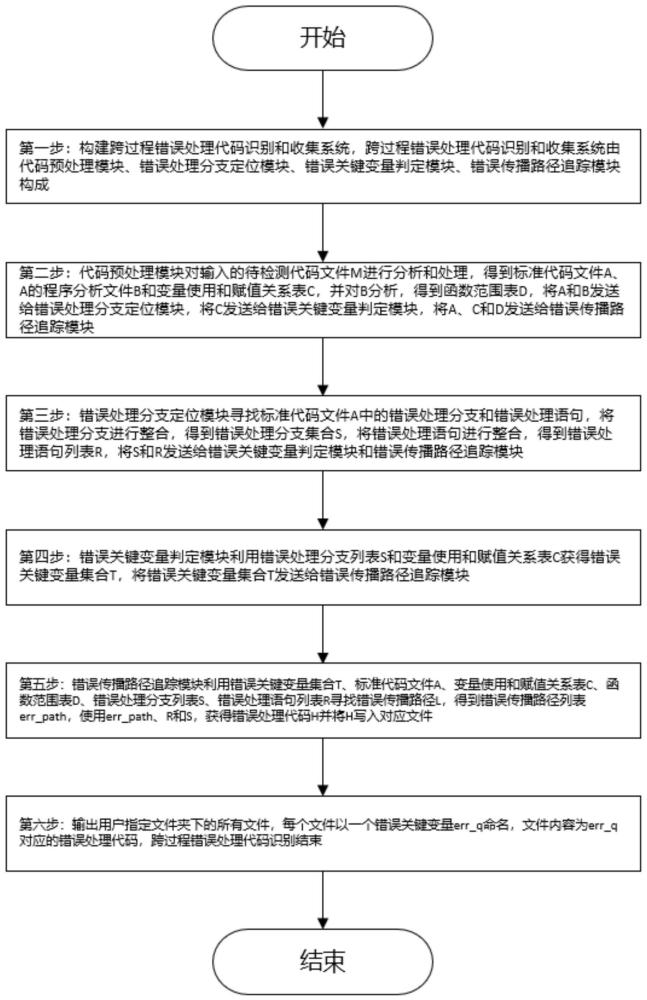
4、第一步,构建跨过程错误处理代码识别系统,跨过程错误处理代码识别系统由代码预处理模块、错误处理分支定位模块、错误关键变量判定模块、错误传播路径追踪模块组成。
5、代码预处理模块与错误处理分支定位模块、错误关键变量判定模块、错误传播路径追踪模块相连,代码预处理模块对用户输入的待检测代码文件m进行分析和处理,得到标准代码文件a、a的程序分析文件b和变量使用和赋值关系表c,并对b分析,得到函数范围表d,将a和b发送给错误处理分支定位模块,将c发送给错误关键变量判定模块,将a、c和d发送给错误传播路径追踪模块。
6、错误处理分支定位模块与代码预处理模块、错误关键变量判断模块、错误传播路径追踪模块相连,从代码预处理模块接收标准代码文件a和程序分析文件b,通过用户自定义的关键字在标准代码文件a中寻找与错误处理相关的代码片段,得到错误处理语句列表r,在程序分析文件b中寻找与错误处理相关的代码片段对应的位置并获得代码片段所在的错误处理分支,将错误处理分支打包成集合s,将s和r发送给错误关键变量判定模块和错误传播路径追踪模块。
7、错误关键变量判定模块与代码预处理模块、错误处理分支定位模块、错误传播路径追踪模块相连,从错误处理分支定位模块接收错误处理分支集合s,从代码预处理模块接收变量使用和赋值关系表c,通过比较错误处理分支集合s与变量使用和赋值关系表c获得错误关键变量集合t,并将错误关键变量集合t发送给错误传播路径追踪模块。
8、错误传播路径追踪模块与代码预处理模块、错误关键变量判定模块、错误处理分支定位模块相连,从错误处理分支定位模块接收错误处理分支集合s和错误处理语句列表r,从错误关键变量判定模块接收错误关键变量集合t,从代码预处理模块接收标准代码文件a、变量使用和赋值关系表c、函数范围表d,在变量使用和赋值关系表c和函数范围表d中跟踪错误关键变量集合t的赋值情况,得到错误传播的路径p,在标准代码文件a中提取错误传播的路径p和错误处理分支集合s所在的代码,并将所提取的代码进行整合,得到错误处理代码h。
9、第二步:代码预处理模块对用户输入的待检测代码文件m进行分析和处理,得到标准代码文件a、a的程序分析文件b和变量使用和赋值关系表c,并对b分析,得到函数范围表d,将a和b发送给错误处理分支定位模块,将c发送给错误关键变量判定模块,将a、c和d发送给错误传播路径追踪模块,方法是:
10、2.1代码预处理模块读入用户输入的待检测代码文件m;
11、2.2代码预处理模块使用程序分析工具(例如srcml(https://www.srcml.org/,v1.0.0))分析待检测代码文件m的代码结构,得到m的程序分析文件m_1,m_1为m中的每一行代码标注其组成和属性,包括函数、函数的类型、函数参数类型、函数参数名称、if-else结构、switch结构、调用函数的结构调用函数的名称,调用函数的函数参数,调用函数的函数参数操作符;以m_1中任意一行(<function pos:start="128:5"pos:end="147:5"><typepos:start="128:5"pos:end="128:32"><specifier pos:start="128:5"pos:end="128:10">static</specifier><name pos:start="128:12"pos:end="128:32"><namepos:start="128:12"pos:end="128:15">enum</name><name pos:start="128:17"pos:end="128:32">scrcpy_exit_code</name></name></type><name pos:start="128:34"pos:end="128:43">event_loop</name><parameter_list pos:start="128:44"pos:end="128:61">(<parameter pos:start="128:45" pos:end="128:60"><decl pos:start="128:45"pos:end="128:60"><type pos:start="128:45"pos:end="128:60"><namepos:start="128:45" pos:end="128:57"><name pos:start="128:45"pos:end="128:50">struct</name> <name pos:start="128:52"pos:end="128:57">scrcpy</name></name> <modifier pos:start="128:59"pos:end="128:59">*</modifier></type><namepos:start="128:60"pos:end="128:60">s</name></decl></parameter>)</parameter_list>)为例来说明m_1的内容:
12、<function pos:start="128:5"pos:end="147:5">表示在文件m中从第128行第5个字符到第147行第5个字符定义了一个函数;
13、<type pos:start="128:5"pos:end="128:32"><specifier pos:start="128:5"pos:end="128:10">static</specifier><name pos:start="128:12"pos:end="128:32"><name pos:start="128:12"pos:end="128:15">enum</name><name pos:start="128:17"pos:end="128:32">scrcpy_exit_code</name></name></type>表示函数的类型为static enum scrcpy_exit_code;
14、<name pos:start="128:34"pos:end="128:43">event_loop</name>表示函数名为event_loop;
15、<type pos:start="128:45"pos:end="128:60"><name pos:start="128:45"pos:end="128:57"><name pos:start="128:45"pos:end="128:50">struct</name><name pos:start="128:52"pos:end="128:57">scrcpy</name></name><modifier pos:start="128:59"pos:end="128:59">*</modifier></type>表示函数参数类型是structscrcpy*;
16、<name pos:start="128:60"pos:end="128:60">s</name>表示函数参数名称是s;
17、除此之外,m_1中还存在这样的语句:<if_stmt pos:start="119:9"pos:end="126:9">表示在m中从第119行第9个字符开始到第126行第9个字符结束是一个if-else结构;<switchpos:start="133:13"pos:end="144:13">表示在m中从第133行第13个字符开始到第144行第13个字符结束是一个switch结构;<call pos:start="58:19"pos:end="58:39"><name pos:start="58:19"pos:end="58:31">sdl_pushevent</name><argument_list pos:start="58:32"pos:end="58:39">(<argument pos:start="58:33"pos:end="58:38"><expr pos:start="58:33"pos:end="58:38"><operator pos:start="58:33"pos:end="58:33">&;</operator><name pos:start="58:34"
18、pos:end="58:38">event</name></expr></argument>)</argument_list></call>表示在文件m的第58行从第19到第39个字符调用了一个函数,函数名称为sdl_pushevent,函数参数为event,参数操作符为&。
19、2.3代码预处理模块对m进行格式化,方法是:
20、2.3.1初始化p=1,p为m_1的行数;
21、2.3.2若p>p,说明已经找到所有注释,转2.3.4;若p≤p,查找m_1中第p行内容,令p=p+1,检查是否出现注释标注:<comment type=type pos:start="start_1:start_2"pos:end="end_1:end_2">,其中type可以为line或block,表示注释的类型为多行注释或单行注释,start_1、start_2、end_1、end_2表示注释从m的第start_1行第start_2个字符开始,结束于m的第end_1行第end_2个字符,若不出现注释标注,转2.3.2;若出现注释标注,转2.3.3;
22、2.3.3将m中从第start_1行第start_2个字符到第end_1行第end_2个字符的内容换成空格,转2.3.2;
23、2.3.4使用文本编辑器(例如visual studio code(https://code.visualstudio.com/,v1.87))的格式化功能,将m_1格式化,得到标准代码文件a;
24、2.4代码预处理模块再次使用程序分析工具(例如srcml)对a进行分析,得到a的程序分析文件b以及变量使用和赋值关系表c,b与m_1格式相同,即为a中的每一行代码标注其组成和属性,c由n行文本组成,每行包括文件名、函数名、变量名、赋值、使用五个域,中间由逗号隔开,例如../adb.c,sc_adb_select_device,ok,def{552,625},use{553,626},表示在./adb.c文件中的sc_adb_select_device函数中的ok变量会在./adb.c文件的第552和625行被赋值,在./adb.c文件的第553和626行被使用;
25、2.5代码预处理模块对b分析,得到函数范围表d,方法如下:
26、2.5.1初始化函数范围表d为空,d用于存放a中所有被定义函数的名称及其范围;初始化函数列表func为空,func用于存放a中所有被定义函数的名称;初始化变量i=1,1≤i≤n,n为变量使用和赋值关系表c中的文本行数;
27、2.5.2若i>n,说明所有函数寻找完毕,跳转到2.6;若i≤n,令i=i+1,在b中寻找第i-1个形如<function pos:start="start_1:start_2"pos:end="end_1:end_2">的字符串,start_1、start_2、end_1、end_2均为整数,表示第i个函数func_i从文件a的第start_1行的第start_2个字符开始,到文件a的第end_1行的第end_2个字符结束,转2.5.3;
28、2.5.3从<function pos:start="start_1:start_2"pos:end="end_1:end_2">字符串向后继续寻找<name pos:start="start_3:start_4"pos:end="end_3:end_4">f_name</name>字符串,该字符串表示func_i的名字为f_name,f_name从文件a的第start_3行的第start_4个字符开始,到文件a的第end_3行的第end_4个字符结束,若f_name在func中,则转2.5.2;若f_name不在func中,则将f_name加入func,将二元组(f_name,(start_1,end_1))加入d,转2.5.2;
29、2.6将a和b发送给错误处理分支定位模块,将c发送给错误关键变量判定模块,将a、c和d发送给错误传播路径追踪模块;
30、第三步,错误处理分支定位模块寻找标准代码文件a中的错误处理分支和错误处理语句,将错误处理分支进行整合,得到错误处理分支集合s,将错误处理语句进行整合,得到错误处理语句列表r,将s和r发送给错误关键变量判定模块和错误传播路径追踪模块,方法是:
31、3.1错误处理分支定位模块从代码预处理模块接收a和b;
32、3.2错误处理分支定位模块通过b构建if-else树list_tree,list_tree表示a中if-else结构的控制范围,方法是:
33、3.2.1初始化list_tree为空,list_tree用于存放a中每个if-else结构在文件中的开始和结束范围,初始化变量j=1,1≤j≤j,j为a中所有if-else结构的数量;
34、3.2.2若j>j,说明a中的所有if-else结构被找到,转3.3;若j≤j,令j=j+1,在b中寻找第j-1个形如<if_stmt pos:start="start_1:start_2"pos:end="end_1:end_2">的字符串,start_1、start_2、end_1、end_2均为整数,表示第j-1个if-else结构从文件a的第start_1行的第start_2个字符开始,到文件a的第end_1行的第end_2个字符结束,转3.2.3;
35、3.2.3判断二元组(start_1,end_1)是否在list_tree中,若(start_1,end_1)在list_tree中,则直接转3.2.2,继续寻找下一个if-else结构;若(start_1,end_1)不在list_tree中,则将(start_1,end_1)加入list_tree,转3.2.2;
36、3.3错误处理分支定位模块利用a和b确定a中的错误处理语句的位置,方法是:
37、3.3.1初始化错误处理语句列表r为空,用于存放错误处理语句在a中的位置,例如文件第5行有错误处理语句则将5加入r,初始化变量k=1,1≤k≤k,k为a中所有函数调用的数量;
38、3.3.2若k>k,说明所有函数调用被找到,转3.4;若k≤k,令k=k+1,在b中寻找第k–1个形如<call pos:start="start_1:start_2"pos:end="end_1:end_2">的字符串,表示a中从第start_1行第start_2个字符到第end_1行第end_2个字符中发生了函数调用,转3.3.3;
39、3.3.3读取第k–1个<callpos:start="start_1:start_2"pos:end="end_1:end_2">字符串之后的形如<name pos:start="start_1:start_2"pos:end="end_1:end_2">f_name</name>的字符串,表示a中第k-1个函数调用的名字为f_name,f_name为字符串,若f_name中不含有用户自定义的关键字,例如“print”、“log”,转3.3.2;若f_name中含有用户自定义的关键字,转3.3.4;
40、3.3.4读取第k–1个<callpos:start="start_1:start_2"pos:end="end_1:end_2">字符串之后的形如<argument pos:start="start_1:start_2"pos:end="end_1:end_2">
41、argument_tmp</argument>的字符串,表示函数调用f_name使用了参数argument_tmp,若argument_tmp中包含用户自定义的关键字(在文件中写入即可),例如“error”、“fail”、“unexpected”和“could not”,将start_1加入list_chain,转3.3.2;若argument_tmp中不包含用户自定义的关键字,转3.3.2;
42、3.4初始化错误处理语句临时列表list_chain=r,用于存储错误处理语句;
43、3.5错误处理分支定位模块利用list_tree和list_chain定位错误处理分支,方法是:
44、3.5.1初始化错误处理分支列表list_err_domain为空,用于存放错误处理分支在文件a中的范围;
45、3.5.2若list_chain为空,说明m中没有错误处理语句或错误处理语句全部被处理,转3.5.6;若list_chain不为空,则从list_chain中任意取出一个错误处理语句在a中的位置,记作position,并将其从list_chain中删除,转3.5.3;
46、3.5.3初始化二元组domain=(min,max),通常min初始值设置为0,max初始值设置为a的行数a_loc,用于表示错误处理分支在a中的范围,初始化变量l=1,1≤l≤l,l为list_tree中元素数量;
47、3.5.4令l=l+1,从list_tree中取出第l-1个元素,令其为(start_l,end_l),若min≤start_l≤position≤end_l≤max,则将domain更新为(start_l,end_l),令min=start_l,max=end_l,若不满足min≤start_l≤position≤end_l≤max,则不更新domain以及min、max;若l>l,转3.5.5;若l≤l,转3.5.4;
48、3.5.5若domain不等于(0,a_loc),将domain加入到list_err_domain中,转3.5.2;若domain等于(0,a_loc),直接转3.5.2;
49、3.5.6去除list_err_domain中的重复元素,得到错误处理分支列表s,s中存放着形如(min,max)这样的二元组,每个二元组表示一个错误处理分支在a中的范围,(min,max)表示错误处理分支开始于a的第min行,结束于a的第max行,转3.6;
50、3.6将s发送给错误关键变量判定模块和错误传播路径追踪模块,将r发送给错误传播路径追踪模块;
51、第四步:错误关键变量判定模块利用错误处理分支列表s和变量使用和赋值关系表c获得错误关键变量集合t,将错误关键变量集合t发送给错误传播路径追踪模块:
52、4.1错误关键变量判定模块从代码预处理模块接收c,从错误处理分支定位模块接收s;
53、4.2初始化错误关键变量列表err_para为空,用于存放错误关键变量,初始化错误关键变量位置列表err_para_position为空,用于存放错误关键变量位置;
54、4.3错误关键变量判定模块遍历错误处理分支列表s,确定错误处理分支的错误关键变量,方法是:
55、4.3.1若s为空,说明a中没有错误处理分支或错误处理分支已经处理完毕,转4.4;若s不为空,则从错误处理分支列表s中取出一个错误处理分支,记为domain,domain为形如(min,max)的二元组,将domain从s中删除,转4.3.2;
56、4.3.2从c中找到在a中第min行被使用的变量,记为p1、p2…、pn、…pn,将变量列表[p1、p2…、pn、…pn]作为一个元素加入错误关键变量列表err_para,同时将min加入err_para_position,转4.3.1;
57、4.4根据err_para和err_para_position得到错误关键变量和错误关键变量在a中的位置集合t,方法是:
58、4.4.1初始化t为空,用于存放错误关键变量和错误关键变量在a中的位置,初始化f=1,1≤f≤f,f为err_para中元素个数;
59、4.4.2若f>f,说明所有错误变量被处理,转4.5;若f≤f,令f=f+1,从err_para中取出第f-1个元素,标记为[pf1、pf2…、pfn、…pfn],从err_para_position中取出第f-1个元素,标记为low_f,转4.4.3;
60、4.4.3将二元组(pf1,low_f)、…、(pfn,low_f)…、(pfn,low_f)加入t,转4.4.2;
61、4.5将错误关键变量集合t发送给错误传播路径追踪模块;
62、第五步:错误传播路径追踪模块利用错误关键变量集合t、标准代码文件a、变量使用和赋值关系表c、函数范围表d、错误处理分支列表s、错误处理语句列表r寻找错误传播路径l,得到错误传播路径列表err_path,使用err_path、r和s,获得错误处理代码h并将h写入对应文件,方法是:
63、5.1初始化错误传播路径列表err_path为空,用于存放获得的错误传播路径;
64、5.2遍历错误关键变量集合t,利用变量使用和赋值关系表c寻找错误传播路径,方法如下:
65、5.2.1初始化q为t中元素的个数,初始化q=1,初始化临时错误传播路径列表err_path_temp为空,用于临时存放错误传播路径;
66、5.2.2若q>q,说明所有错误关键变量被处理完毕,转5.3;若q≤q,令q=q+1,从t中选择第q-1个元素,记为(err_q,position_q),position_q表示错误关键变量err_q在a中的位置,转5.2.3;
67、5.2.3在变量使用和赋值关系表c中寻找错误关键变量err_q和err_q所在函数f_name,在函数范围表d中得到f_name的范围,f_name的范围为形如(start_1,end_1)的二元组;
68、5.2.4在变量使用和赋值关系表c中找到在position_q处被使用的变量q;
69、5.2.5令q为待跟踪变量,在变量使用和赋值关系表c中找到q在函数f_name中所有被赋值的位置,令为p1、…pm、…pm,其中p1、…pm、…pm表示q在a中第p1、…pm、…pm行被赋值,在a中寻找p_q_i,要求p_q_i满足:p_q_i<position_q,且对于任意pm,若pm<position_q,则pm≤p_q_i;将p_q_i加入err_path_temp,若p_q_i等于start_1,转5.2.7;若p_q_i不等于start_1,转5.2.6;
70、5.2.6在c中寻找在p_q_i处被使用的变量x,令q=x,转5.2.5;
71、5.2.7在b中寻找形如<callpos:start="start_1:start_2"pos:end="end_1:end_2">
72、<name pos:start="start_3:start_4"pos:end="end_3:end_4">f_name</name>的字符串,表示f_name在文件a的第start_1行被调用,其中f_name为5.2.3中得到,若不存在这样的字符串,将(err_q,err_path_temp)加入err_path,转5.2.2;若存在这样的字符串,转5.2.8;
73、5.2.8令position_q=start_1,在c中寻找在start_1处被赋值的变量y,若不存在y,将(err_q,err_path_temp)加入err_path,转5.2.2;若存在y,令q=y,转5.2.5;
74、5.3将错误传播路径列表err_path、错误处理语句列表r和错误处理分支列表s进行整合,得到错误处理代码列表list_all,方法是:
75、5.3.1初始化错误处理代码所在位置列表list_all为空,用于存放错误处理代码所在位置以及对应的错误关键变量,初始化错误处理代码所在位置临时列表list为空,用于存放单个错误关键变量对应的错误处理代码位置,初始化变量s=1;
76、5.3.2若s>s_len,s_len为s中元素数量,说明所有错误处理分支被处理完毕,转5.4;若s≤s_len,令s=s+1,从s中取出第s-1个元素s_s,s_s形式为二元组,形如(low,high),初始化变量t_l=1,初始化变量z=1,转5.3.3;
77、5.3.3若t_l>t_l,t_l为r中元素数量,说明所有错误处理语句被处理完毕,转5.3.4;从r取出第t_l个元素,判断t_l是否满足low≤t_l≤high,若t_l满足low≤t_l≤high,将t_l加入list,令t_l=t_l+1,转5.3.3;若t_l不满足low≤t_l≤high,令t_l=t_l+1,转5.3.3;
78、5.3.4若z>z,z为err_path中元素数量,说明所有错误传播路径被处理完毕,转5.3.2;若z≤z,令z=z+1,从err_path中取出第z-1个元素w,w形式为二元组,由变量名err_q与临时错误传播路径列表err_path_temp组成,若low在err_path_temp中,将err_path_temp中的元素加入list,将二元组(err_q,list)加入list_all,转5.3.4;若low不在err_path_temp中,转5.3.4;
79、5.4对list_all进行处理,获得错误处理代码h并将h写入对应文件,方法是:
80、5.4.1初始化变量l_a=1;
81、5.4.2若l_a>l_a,l_a为list_all中元素数量,说明所有错误处理代码被处理完毕,转第六步;若l_a≤l_a,令l_a=l_a+1,从list_all中取出第l_a-1个元素list_l_a,list_l_a为形如(err_q,list)的二元组,err_q为错误关键变量,list中的元素为err_q对应的错误处理代码在a中的位置,在用户指定文件夹下创建名为err_q的文件,将list中的元素按从小到大的顺序排列,接着从a中获得list中元素对应的语句h,将h写入名为err_q的文件,例如list为(11,12,13),err_q为ok,则将a中第11、12、13行代码写入名为ok的文件,转5.4.2;
82、第六步:输出用户指定文件夹下的所有文件,每个文件以一个错误关键变量err_q命名,文件内容为err_q对应的错误处理代码,跨过程错误处理代码识别结束。
83、与现有技术相比,采用本发明能达到以下有益效果:
84、1、采用本发明能有效识别错误处理代码。采用本发明在开源项目scrcpy的源码文件中进行识别,能够获取86组错误处理代码,其中超过80%的错误处理代码跨越多个函数。说明本发明在识别错误处理代码,尤其是识别跨过程错误处理代码方面具有优势。
85、2、本发明基于srcml工具对代码进行分析,可以跨过程识别和收集代码文件中的错误处理代码,具有良好的应用前景。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194302.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。