一种视频人物动作特征的典型模式挖掘方法
- 国知局
- 2024-07-31 22:59:08
本发明涉及一种针对视频人物频繁出现的典型模式动作特征挖掘方法,更具体来说,本发明是一种基于图卷积的肢体动作单元识别模型联合apriori算法的视频人物动作特征的典型模式挖掘方法,属于计算机视觉与数据挖掘领域。
背景技术:
1、随着计算机技术的飞速发展以及移动智能设备的普及,视频已经成为传播信息的重要途径。其中,以视频人物为媒介的信息传递形式已经渗透到生活的方方面面,例如视频博主通过自己的专业特长以及性格特点,创作了大量不同类型的视频作品,并通过网络平台推送给大众群体。视频博主所传达的信息方式主要分为两种:语言行为和非语言行为。明确的语言行为在人类交流中占据着主导地位,它可以直接表达人类内心的想法和目的。同样,非语言行为在传递人类信息、表达思想方面也起着十分重要的作用。非语言行为主要由不同的身体动作构成,例如面部表情、手势、身体姿势等,这些动作可独立存在,同时也可伴随着语言行为而发生。有心理学研究表明,有些意识或潜意识下所进行的身体动作隐藏了人类内心的心理活动。例如,摊手表示无奈、搓手表示焦虑;在一个害怕或撒谎的人的嘴唇应该表现什么形状。
2、人们在交流过程中,主要通过语言行为和非语言行为两种方式来进行传递信息以及表达思想。在语言行为方面,人们之间可能会有一些不同的习惯用语,例如“口头禅”,它是人们的一个典型模式。同样,在非语言行为方面,人们之间也会产生一些频繁的行为习惯,例如面部动作习惯和肢体动作习惯,这些动作习惯也是人们其中的典型模式。在现有基于视频数据的人物动作特征研究中,传统的方法大多数是对人物的行为识别或动作识别,而对视频中具体人物频繁出现的动作特征研究相对较少。非语言行为在传递人类信息、表达思想方面十分重要,本发明通过挖掘人物动作特征的典型模式,有以下意义:(1)有助于分析人物的性格特点;(2)便于从典型动作角度识别人物个体;(3)更进一步深入探究面向视频中人物个体的典型动作挖掘方法。
技术实现思路
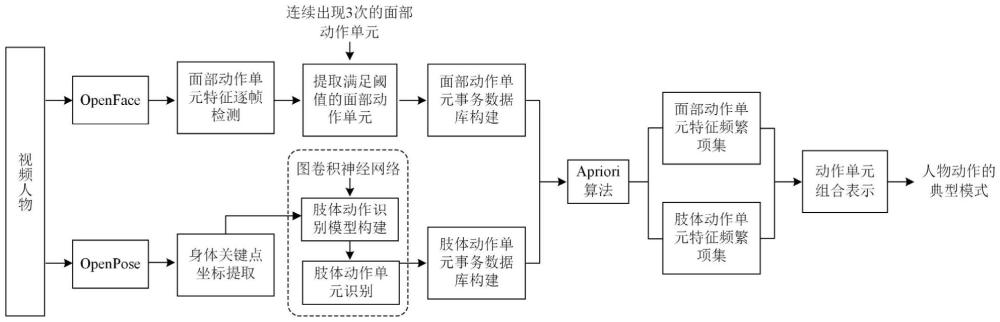
1、针对视频中人物个体频繁出现的动作特征挖掘问题,本文提出了一种图卷积神经网络联合apriori算法的人物个体动作特征的典型模式挖掘方法。首先,使用面部分析工具(openface)和姿态估计工具(openpose)来分别提取视频人物的面部动作单元特征以及人体关键点坐标特征;接着,设计多帧判断策略来完成面部动作单元的提取,另外引入姿态矫正模块(pose correction module,pcm),改进所采用的主干网络来提高肢体动作单元识别准确性;然后,根据动作单元识别结果分别构建面部动作单元事务数据库和肢体动作单元事务数据库,并使用apriori算法挖掘出动作特征的频繁项集;最后,采用相同序列组合方式,将同时域内发生的面部动作单元和肢体动作单元进行组合,以表示视频人物整体动作特征的典型模式。通过对不同的视频人物进行挖掘测试,实验结果证明了本发明能够有效提取出人物频繁出现的动作特征。
2、为实现上述目的,本发明采用的技术方案:一种视频人物动作特征的典型模式挖掘方法,针对单个视频人物动作特征的典型模式挖掘,包括以下步骤:
3、s1.人物个体动作单元定义,采用面部编码系统中面部分析工具openface识别出的面部动作编码作为人物的面部动作单元,采用了imigue数据集中的动作类别作为人物个体的肢体动作单元;
4、s2.使用openface提取视频人物的面部动作单元特征:
5、使用openface以逐帧的方式对人物视频进行检测,得到每帧出现的面部动作单元特征文件;在此基础上,再以l帧为检测步长,依次对面部动作单元特征检测文件进行筛选,提取出相邻帧中连续出现3次及以上的面部动作单元,作为最终的提取结果;
6、s3.对imigue数据集进行预处理,构建基于骨架的图卷积肢体动作单元识别模型,在时空图卷积算法主干网络中引入了姿态矫正模块;所述姿态矫正模块包括卷积层、图卷积层、时间卷积层,其中图卷积层和时间卷积层均采用了数据批处理层和残差连接,具体包括以下步骤:
7、对imigue数据集进行预处理;构建基于骨架的图卷积肢体动作单元识别模型,在时空图卷积算法主干网络中引入了姿态矫正模块;
8、所述姿态矫正模块包括卷积层、图卷积层、时间卷积层,其中图卷积层和时间卷积层均采用了数据批处理层和残差连接,具体包括以下步骤:
9、基于骨架的图卷积肢体动作单元识别模型,使用st-gcn算法作为主干网络;在基于骨架的动作识别中,每个骨架序列被表示为一个时空图g(v,e);其中,顶点v是由坐标表示的身体关节;边e包括空间边和时间边,空间边是每帧上的顶点之间的连接,而时间边是相邻帧上的相同关节的连接;
10、图卷积层:图卷积对预定义的图结构进行操作,在空间维度上,每个顶点的图卷积可以表示为:
11、
12、式中,f(v)为顶点v的特征,fin为输入特征,fout为输出特征,w为权重;vi为目标顶点,bi是包括vi在内的相邻节点的集合;vj为vi相邻顶点,li为映射函数,它将邻居节点映射到一组预定义的组中,包括顶点本身、靠近重心的顶点以及远离重心的顶点;其中zij是顶点本身、靠近重心的顶点以及远离重心的顶点的基数(包括vj);网络中输入的骨架序列表示为一个张量(c,t,n),c为通道数,t为序列的长度,n为顶点数;因此公式(1)转换为:
13、
14、式中,kv=3是空间维度的核大小,矩阵表示顶点连接,在顶点vj∈βi时为非零值;
15、为归一化对角矩阵,α设置为0.001;wk是一个1×1卷积运算的权值向量;注意力地图mk表示每个顶点的重要性,通过一个元素级乘积⊙应用于每个顶点时间卷积层:时间卷积是一个kt×1卷积,其中kt=3是时间维度上的核大小;
16、所述在主干网络中引入姿态矫正模块,通过姿态估计工具来获取每个关节的x和y坐标以及关节估计的置信度并作为输入,来估计关节点的偏移量(δx,δy),其中图卷积层利用关节之间的空间关系,而时间卷积层则利用时间的一致性进行姿态细化,再将偏移量(δx,δy)添加到每个关节的二维坐标当中;矫正后的骨架坐标表示为:
17、xi=xi+δxi (3)
18、式中,xi为矫正后的坐标,xi为原始坐标,δxi为原始坐标的偏移量;
19、通过估计每个关节的偏移量,并将这些偏移量添加到原始骨架坐标上,以此来矫正每个骨架坐标数据;
20、s4.将数据集中的图像数据作为输入,输入引入了姿态矫正模块的时空图卷积算法主干网络中进行训练,得到训练好的肢体动作单元识别模型;
21、s5.将待检测的人物视频图像送入到训练好的肢体动作单元识别模型中,得到人物的肢体动作单元类别;
22、s6.根据openface和肢体动作单元识别模型识别出的人物视频中所出现的面部动作特征和肢体动作特征,分别构建面部动作单元事务数据库和肢体动作单元事务数据库;
23、s7.通过使用apriori算法分别挖掘出视频人物肢体动作特征和面部动作特征的频繁项集;
24、s8.根据肢体和面部动作特征频繁项集的挖掘结果,将同一时间区间内的肢体动作和面部动作进行组合来表示视频人物个体动作的典型模式。
25、进一步地,所述步骤s3中的数据集预处理包含如下步骤:
26、s3.1根据数据集标签文件,对源视频数据进行剪辑,生成独立的动作视频片段,并比例划分训练集和测试集;
27、s3.2使用openpose分别提取训练集和测试集中人体关键点坐标特征数据,合并样本每帧中提取的json特征文件,同时将特征数据的x和y坐标归一化到0-1;
28、s3.3将通过处理后的特征文件分别生成符合网络的输入格式的训练集文件、测试集文件以及对应的训练集标签文件、测试集标签文件。
29、本发明技术方案能够取得以下技术效果:视频人物动作特征的典型模式挖掘方法通过使用“3帧序列”判断策略进一步筛选出面部动作单元,解决了openface逐帧检测,从而难与肢体动作单元检测结果对应的问题。将原有肢体动作单元识别模型中引入姿态矫正模块,通过估计每个关节的偏移量,并将偏移量添加到原始骨架坐标上,优化了姿态估计算法在提取人体关节特征时可能存在的误差,提升了识别肢体动作单元的准确性。提出视频人物动作特征事务数据库的构建方法并引入apriori算法,解决了视频人物面部动作单元和肢体动作单元的频繁项集挖掘问题。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195601.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。