一种基于强化学习的无人机辅助配送系统及方法
- 国知局
- 2024-07-31 23:30:14
本发明涉及无人机航迹领域,具体而言,涉及一种基于强化学习的无人机辅助配送系统及方法。
背景技术:
1、近年来,在物流和无人机领域的研究成果很多。但将这两个领域结合起来的研究成果很少。研究无人机领域与物流领域的结合具有理论意义,具体如下:
2、(1)无人机因其较快的飞行速度和轻便灵巧特性,非常适合物流配送服务的最后一公里的交付。
3、(2)由于无人机不受道路基础设施的限制,能够相对轻松地穿过山、丛林、河流等地区,走更短的路线,相比于其他运输方式有更快的效率。
4、(3)地面车辆在交付途中遇到许多障碍,有时需要支援穿越海上等其他无法通行的地区,但无人机在飞往目的地的途中不受阻碍。
5、(4)由于无人机能够有效避免交通拥堵,因此被用于城市地区提供快速、精准的交付服务。无人机还可以用于救灾物资运送到灾区,其中很多是地面车辆甚至徒步救援人员无法到达的。此外,在灾区救灾交付任务中也不存在二次伤害的担忧。
6、路径规划对于无人机执行任务、避免其作业环境中出现威胁至关重要。规划的路径应在应用所定义的特定准则下最优。对于航空摄影、测绘和地面检查等大多数应用来说,标准通常是尽量减少无人机访问地点之间的飞行距离,以减少所需时间和燃料。该准则还可以像动态目标搜索那样最大化探测概率,像监视和救援那样最小化飞行时间,或者寻找多目标导航的pareto解。此外,规划的路径还需要满足无人机对作业环境施加的安全约束和可行性约束。
7、无人机物流系统具有区别于一般地面物流的一些基本特征,如飞行时间有限、载重能力强、货物重量对飞行能力的影响等。因此,有效的物流系统和任务分配策略对降低物流企业的运营成本、提高运输效率具有重要作用。
技术实现思路
1、发明目的:为了降低物流企业的运营成本、提高运输效率,本发明提供一种基于强化学习的无人机辅助配送系统及方法,用于无人机在交付物流中的应用。
2、技术方案:一种基于强化学习的无人机辅助配送方法,包括如下步骤:
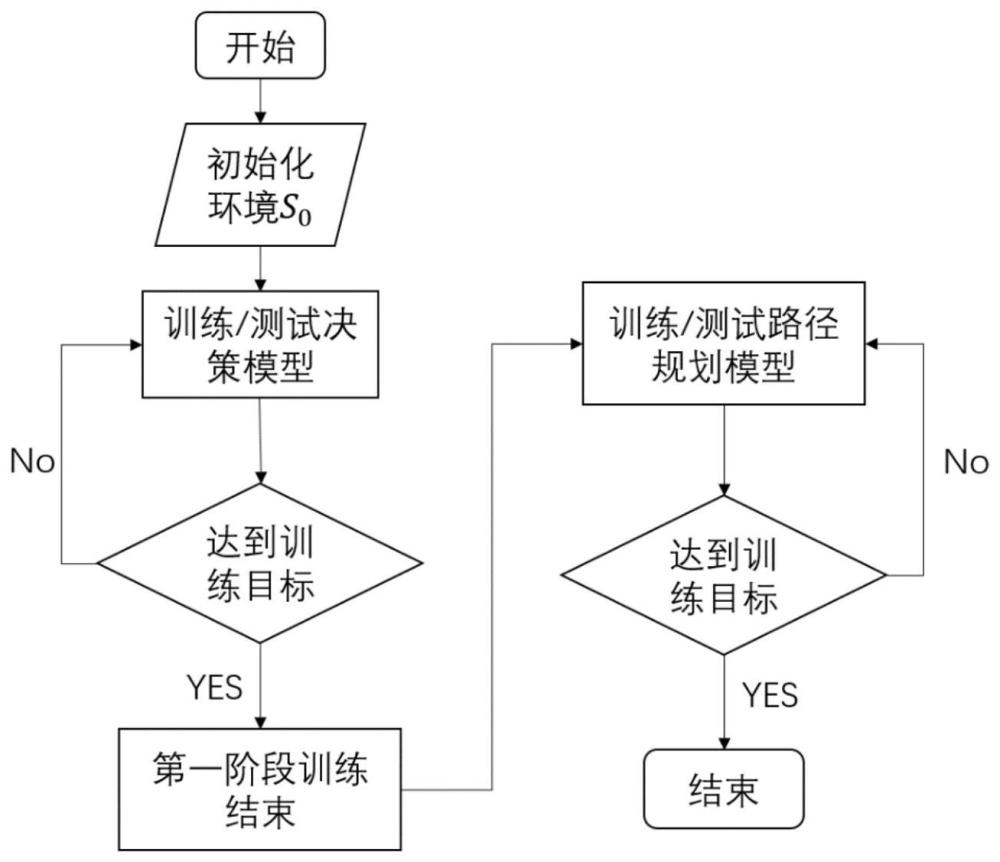
3、步骤一、构建用于无人机辅助配送的数学模型,即无人机配送调度问题模型;所述无人机配送调度问题模型采用马尔可夫决策过程模型为基础模型进行构建,包括无人机任务分配模型和无人机路径规划模型;
4、所述无人机辅助配送过程为:车辆填装待配送物品到无人机装填仓,无人机按照规划出的最优路径将无人机装填仓内的待配送物品配送到距离用户最近的快递柜,无人机在完成最近的快递柜的交付时便会立即飞向另一个快递柜,无人机全部配送完成后回到无人机装填仓;
5、步骤二、基于ppo-pso算法,采用lstm–cnn神经网络架构,分别设计用于无人机任务分配模型的任务分配算法和用于无人机路径规划模型的航线规划算法;
6、步骤三、构建自主制导与跟踪避障模型,使无人机能够适应对象和环境的不确定性,具有变参数、变结构的能力,实现地面随机运动目标的连续跟踪和合理避障;
7、步骤四、将自主制导与跟踪避障模型在pybullet平台上进行训练,将训练好的神经网络架构部署到设计好的实验环境上,采用ros系统进行仿真验证。
8、进一步的,所述步骤一中,无人机配送调度问题模型应满足如下优化目标和约束条件如下:
9、(1)定义优化目标a为用户对配送服务的满意度:
10、
11、式中,ti为包裹pi的实际送达时间,为包裹pi的最佳送达时间;pi表示第i个包裹;n表示包裹的数量;
12、(2)定义优化目标b为所有包裹的总配送时长:
13、
14、式中,为无人机uk完成它所有的任务所耗费的时间,uk为第k个无人机;
15、(3)将多目标优化问题转化为单目标优化问题,把对总配送时长b和用户对配送服务的满意度a的优化目标转化为对目标c的优化:
16、c=bmax×a+b (3)
17、式中,bmax为所有包裹配送完成时间的最大值;
18、(4)约束条件,包括单个包裹的最大重量限制约束、无人机单次飞行的总载重量限制约束、单次配送的运输距离限制约束;
19、(4.1)单个包裹的最大重量限制约束为:
20、
21、式中,wi表示包裹pi的重量,表示任意无人机以及飞行趟数,c表示无人机载荷上限;
22、(4.2)无人机单次飞行的总载重量限制约束为:
23、
24、式中,tk,f为无人机uk第f趟飞行中需要配送的包裹总数,pk,f,b为无人机uk第f趟飞行中第b个配送的包裹,表示包裹pk,f,b的重量;
25、(4.2)单次配送的运输距离限制约束为:
26、
27、式中,表示无人机uk第f趟飞行中所有包裹的目的地,s0表示初始站点;v表示无人机平均飞行功率,e表示无人机最大续航时间;lk,f,b表示无人机uk第f趟飞行中第b个包裹的目的地;
28、(5)期望在满足步骤(4)中限制条件的情况下最小化c,则配送包裹数可通过公式(7)-(10)计算得到:
29、
30、式中,无人机uk完成它所有的任务所耗费的时间,表示无人机uk飞行的开始时间,表示无人机uk飞行的总耗时;
31、
32、式中,tk,f表示无人机uk第f趟飞行的开始时间;tk,f-1表示无人机uk第f-1趟飞行的开始时间;qk,f-1表示无人机uk第f-1趟的总耗时;
33、
34、式中,qk,f表示无人机uk第f趟的总耗时;td表示无人机在s0装载包裹所需要的时间;tc表示无人机在s1,...,sm投放包裹所需要的时间;s1,...,sm表示第1,…,m个站点;
35、
36、式中,pk,f,b表示无人机uk第f趟飞行中第b个配送的包裹;xk,f,b,i为决策变量,b表示第b个包裹;
37、(6)无人机配送调度问题模型的决策公式以及约束条件为(11)和(12):
38、
39、
40、其中xk,f,b,i为决策变量,取0或1,分别代表执行动作与不执行动作;表示任意的i。
41、进一步的,所述步骤一中,马尔可夫决策过程模型的马尔可夫决策mdp,用五元组(s,a,r,p,γ)来描述;其中s为状态空间,a为作用空间,r为奖励,p为状态转移概率,γ为衰减系数,且γ处于区间[0,1]内;
42、在第n个周期内,状态s∈s记为sn,无人机控制信号a∈a记为an,无人机动作对应的累计回报记为rn+1(sn,an);无人机在状态s中动作a后,环境状态向s'过渡的概率p记为pass′;
43、马尔可夫决策过程的奖励如公式(13)所示,训练目标是使reward最大化:
44、reward=r1+γr2+γ2r3+…+γn-2rn-1+γn-1rn (13)
45、在马尔可夫决策mdp的基础上引了状态观测函数o和置信度b;置信度b的更新公式如下:
46、
47、式中,η为常数表示为:η=1/pr(o∣b,a),pr(o∣b,a)可用下式表示:
48、
49、pomdp的优化目标为值函数,在置信度为b0,策略为π时值函数可被表示为:
50、
51、因此,可以得到最优策略为:
52、
53、进一步的,所述步骤二中:
54、所述任务分配算法,用于配送方案的生成;所述航线规划算法用于无人机的航线规划调度;
55、所述ppo-pso算法是指基于标准ppo算法和粒子群算法的特点,将粒子群算法融入ppo算法,对ppo算法进行改进的算法;
56、所述任务分配算法和航线规划算法,采用相互独立的lstm–cnn神经网络架构,基于ppo-pso算法利用粒子优化对智能体迭代方式进行修改,结合使用cnn网络对agent进行参数化,利用长短时记忆网络计算奖励值,通过状态信息更新网络参数并进行自适应优化迭代,同时考虑无人机接收到的时间序列数据和环境上下文信息。
57、进一步的,所述步骤三中:
58、所述自主制导与跟踪避障模型,用于无人机目标跟踪,具有远距离自主制导和短距离自主跟踪避障两个阶段,采用马尔可夫决策过程模型为基础模型进行构建。
59、本发明还公开了一种基于强化学习的无人机辅助配送系统,包括配送中心、无人机装填仓、配送终点和调度中心;
60、所述配送中心的待配送物品,由车辆运输至无人机装填仓;所述无人机装填仓,用于装填待配送物品,无人机将无人机装填仓内的待配送物品配送到配送终点;所述调度中心,设立在无人机装填仓,用于调度无人机,调度软件实时更新物流状态和无人机状态,同时生成无人机配送路径规划结果供工作人员参考;在执行复杂场景任务时,可分配多架无人机协同执行任务。
61、有益效果:
62、1)为使规划的路径满足无人机对作业环境施加的安全约束和可行性约束,本发明构建了无人机配送调度问题模型;
63、本发明通过改进的近端策略优算法ppo-pso,利用长短时记忆(lstm)网络计算奖励值,通过状态信息(如无人机与目标的实时位置关系)更新网络参数并进行自适应优化迭代,同时考虑无人机接收到的时间序列数据和环境上下文信息,获得了最优解所需的时间,相比ppo低约15%,且鲁棒性较好,能够降低物流企业的运营成本、提高运输效率。
64、2)针对无人机对地面动态目标的性能问题,开发了具有远距离自主制导和短距离自主跟踪避障模型,能够实现地面随机运动目标的连续跟踪和合理避障。
本文地址:https://www.jishuxx.com/zhuanli/20240730/197804.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表