一种面向多障碍物环境的多自主水下航行器协同围捕方法、系统、设备及介质
- 国知局
- 2024-07-31 23:35:28
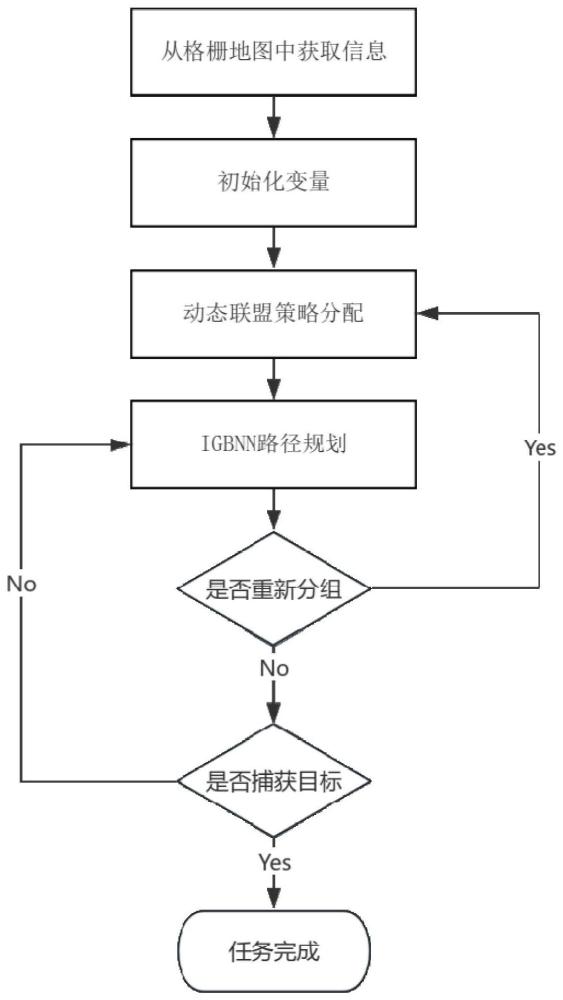
本发明属于多智能体围捕多目标任务领域,设计一种在多障碍物环境下基于igbnn算法及动态联盟的非匀质自主水下航行器围捕方法。
背景技术:
1、自主水下航行器(autonomous underwater vehicle,auv)是一种智能机器人,由于具有较高的智化程度,可以在没有操作者的情况下,独自在海洋中完成任务,被广泛应用于民用领域(深海探测、水下设备维护等)和军事领域。
2、面对复杂的水下环境、不可预知的潜在危险和多样化的任务分配,单个auv受限于携带的燃料以及有限的环境感知范围,围捕能力十分有限。同时,由多艘自主水下航行器构成的多auv系统,可以动态的协同合作,具有更强的灵活性、更高的效率和更广的作业范围,在深海探测、水下协同搜索和军事领域发挥着越来越重要的作用。
3、多自主水下机器人协同寻猎是一种重要的研究课题。研究者们对多auv系统进行了大量的研究,包括水下协同搜索,扫雷,编队控制,协同寻猎等,其中协同寻猎的研究更为全面,其包括三个子任务:搜索逃避者,形成动态狩猎联盟,以及路径规划,直到成功捕获。
4、korf提出了一种手动导出的贪婪策略,属于非学习算法,通过使用适应度函数使得每个狩猎者被目标吸引。denzinger等人提出了结合临近规则的遗传算法方法,采用邻近法对当前状态进行分类,通过遗传算法确定最优解。y.c.chen等人提出的“基于合同网交互协议的多智能体追逃算法”属于分布式算法,但在追捕过程中追捕者之间的通信会过于繁重,导致追捕效率不高。
5、以上讨论的所有策略均是在地面搜索问题上进行研究的,无法应用到水下三维环境的协同狩猎,而且,目前对于水下三维环境中狩猎问题的研究还很少。
6、nguyen等人建立的auv的寻雷模型,采用完全覆盖的方法来实现寻雷,然而,被围捕的目标是静态的,当目标存在逃跑策略时会失效。
7、水下环境是一种独特的情况,通信范围狭窄,容易出错。水下环境似乎也不能提供谈判的通信要求。大多数的研究都是针对同质auv的寻猎问题。到目前为止,对非均匀多auv和智能规避器的狩猎问题几乎没有研究,对于非均匀多auv狩猎问题中的任务分配研究较少。更重要的是,许多研究并没有讨论逃避者是否有逃避策略的问题。
8、在军事应用中,多auv狩猎系统往往需要捕获具有一定智能的入侵者,如微型机器鱼,它们的智能逃避策略将帮助它们逃脱。在实际应用中,参与狩猎的水下机器人往往是不同类型的,具有不同的能力,如不同的航行速度或不同的安全距离,逃避者也可能具有一定的智能逃避策略。因此,实现水下环境中对智能逃避者的围捕策略就显得尤为重要。
技术实现思路
1、本发明的目的在于提供一种面向多障碍物环境的多自主水下航行器协同围捕方法、系统、设备及介质,能够基于igbnn算法及动态联盟策略实现非匀质自主水下航行器的围捕,解决现有技术的多自主水下航行器无法应用到水下三维环境的协同狩猎,以及非均匀多auv狩猎问题中的任务分配问题和待围捕的逃避者有逃避策略,导致难以围捕的问题。
2、一种面向多障碍物环境的多自主水下航行器协同围捕方法,包括:
3、步骤1:采集逃逸者位置集合、围捕者位置集合和障碍物位置集合;
4、步骤2:对步骤1中的各个集合进行初始化;
5、步骤3:根据初始化后的围捕者位置集合和逃逸者位置集合,采用动态联盟策略,获得本地任务集合;
6、步骤4:每个围捕者采用igbnn算法进行路径规划,得到对应的围捕任务;
7、步骤5:判断围捕任务是否满足动态联盟的条件,若不满足,则解散原有联盟,执行步骤3-步骤5,直至形成新的满足动态联盟条件的围捕任务;若满足,则进行围捕;
8、步骤6:当某一逃逸者被捕获,对应的围捕者停止围捕运动;
9、步骤7:待所有逃逸者被捕获后,所有围捕者停止围捕运动,围捕完成。
10、更进一步地,提供优选方案:所述逃逸者位置集合、围捕者位置集合和障碍物位置集合,在多障碍物的栅格地图中提取。
11、更进一步地,提供优选方案:所述步骤1包括:
12、步骤1.1:遍历所述格栅地图,初始化地形矩阵,存在障碍物的地形矩阵的对应位置设为1,否则设为0,并记录为障碍物位置集合;
13、步骤1.2:遍历所述格栅地图,得到目标逃逸者的位置信息并记录为逃逸者位置集合;
14、步骤1.3:遍历所述格栅地图,得到围捕者的位置信息,并记录为围捕者位置集合。
15、更进一步地,提供优选方案:所述步骤2包括:
16、步骤2.1:初始化逃逸者集合,得到需要被围捕的逃逸者数量;
17、步骤2.2:初始化围捕者集合,得到参与围捕任务的围捕者数量;
18、步骤2.3:初始化障碍物集合。
19、更进一步地,提供优选方案:所述步骤3包括:
20、步骤3.1:获取围捕者的速度信息,得到围捕者速度集合;
21、步骤3.2:根据逃逸者位置信息集合和围捕者位置信息集合,计算距离矩阵;
22、步骤3.3:根据所述距离矩阵和围捕者速度集合,计算平均代价矩阵;
23、步骤3.4:生成hunter_flag列表,用于存放该标号的围捕者是否被分配了任务的标志;
24、步骤3.4.1:若第i个围捕者被分配了任务,则hunter_flag的第i个位置为true,否则为false,1≤i≤hunter_num,hunter_num为围捕者数量;
25、步骤3.4.2:循环步骤3.4.1,直至每个围捕者的标号都生成完毕;
26、步骤3.5:初始化team_list列表,用于存放对应于每个逃逸者的围捕任务;
27、步骤3.5.1:第i个位置存放的信息为:参与围捕第i个逃逸者的围捕者的标号集合;
28、步骤3.5.2:初始化设置team_list的每个位置为空集;
29、步骤3.6:获取所述平均代价矩阵的最小值,遍历所述平均代价矩阵,找到该最小值所在的位置,对应围捕者的标号和逃逸者的标号,若当前位置的围捕者还未被分配任务,将得到的围捕者和目标放入team_list[j]中,同时将hunter_flag[i]设为true,并将所述平均代价矩阵设置为最大值;
30、步骤3.7:当hunter_flag不全为true,且每个逃逸者被分配的围捕者数量不超过三个时,循环执行步骤3.6,得到本地任务集合。
31、更进一步地,提供优选方案:所述步骤5包括:
32、当围捕任务不满足动态联盟的条件时,根据评判规则,决定是否解散原有联盟,若解散,则将步骤3中计算所需的位置信息更改为当前时刻的逃逸者的位置信息和围捕者的位置信息,并重复执行步骤3,直至形成新的满足条件的动态联盟,然后执行步骤4,否则仍然执行旧的联盟策略。
33、更进一步地,提供优选方案:所述步骤4包括:
34、步骤4.1:初始化偏置点列表、任务分配点、三维价值矩阵、时间戳和igbnn算法所需标志;
35、步骤4.1.1:设置偏置点列表;
36、步骤4.1.2:设置任务分配点为用于存放围捕者通过igbnn算法得出的目标任务点;
37、步骤4.1.3:初始化价值矩阵为0矩阵,该矩阵用于为航行器选择下一步路径点时提供权重,初始化时间戳(time_stamp)为0;
38、步骤4.1.4:初始化是否开始收缩的标志,用于双联盟策略中执行条件的生成;
39、步骤4.1.5:初始化双联盟标志,用于体现当前动态联盟的状态是否为双联盟状态;
40、步骤4.2:检查两个逃逸者的位置信息,若两个逃逸者的距离小于设定的条件半径,执行步骤4.4,否则,执行步骤4.3;
41、步骤4.3:在不满足双联盟条件时,计算航行器的任务分配点;
42、步骤4.4:在满足双联盟条件时,计算航行器的任务分配点;
43、步骤4.5:根据得到的任务分配点进行路径规划,得到对应的围捕任务。
44、本发明还提出一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机程序,当所述处理器运行所述存储器存储的计算机程序时,所述处理器执行上述任意一种方案组合所述的一种面向多障碍物环境的多自主水下航行器协同围捕方法。
45、本发明还提出一种计算机可读存储介质,所述计算机可读存储介质用于储存计算机程序,所述计算机程序执行上述任意一种方案组合所述的一种面向多障碍物环境的多自主水下航行器协同围捕方法。
46、本发明还提出一种面向多障碍物环境的多自主水下航行器协同围捕系统,所述系统包括:
47、采集装置:用于采集逃逸者位置集合、围捕者位置集合和障碍物位置集合;
48、初始化装置:用于对各个集合进行初始化;
49、联盟装置:用于根据初始化后的围捕者位置集合和逃逸者位置集合,采用动态联盟策略,获得本地任务集合;
50、规划装置:用于采用igbnn算法进行路径规划,得到对应的围捕任务;
51、判断装置:用于判断围捕任务是否满足动态联盟的条件,若不满足,则解散原有联盟,执行步骤3-步骤5,直至形成新的满足动态联盟条件的围捕任务;若满足,则进行围捕;当某一逃逸者被捕获,对应的围捕者停止围捕运动;待所有逃逸者被捕获后,所有围捕者停止围捕运动,围捕完成。
52、相比于现有技术,本发明的优势在于:
53、本发明提出的方法设计了一种适合不同航速的非匀质auv之间的任务分配方法,用于分配寻猎任务。首先,将满足一定条件的目标逃逸者和围捕者放入一个团队形成动态联盟,构成多auv系统,进而提高围捕效率。然后,设计一种基于激励矩阵和信任度矩阵的路径规划方法,该方法结合了gbnn(glasius bio-inspired neural network),不需要先验知识和学习过程,提高了运算速度。激励矩阵可以控制auv的运动方向,对障碍物有较好的规避效果;信任度矩阵可以局部影响auv轨迹,使其路径更加合理,克服激励矩阵信息传播的时延,提高围捕效率。同时,本发明针对的目标逃逸者存在逃逸策略,使得围捕任务变得动态、复杂、困难,对于实际应用有重要意义。
54、本发明采用igbnn算法,并与动态联盟算法相结合,意在实现多障碍物环境下非匀质水下自主航行器对多个目标的狩猎问题,能够根据航行器的航行速度分配适合的目标任务,并对高速移动的智能体有较好的围捕效果,智能体与航行器速度比最高可达到0.85。
55、本发明通过对目标智能体周围的目标分配点改进,使得在动态联盟围捕过程中围捕者可以保持一定的队形,并针对两个智能体距离较近的情况设计了双联盟策略,降低了围捕任务的不确定性。
56、本发明通过改进gbnn算法,使新算法可以实现在过程中规避障碍物的效果;同时,在路径选择策略中,新算法考虑了航行器航向角的变化,使得规划路径更符合无人航行器的运动特性,提高了围捕效率,节省了系统能量消耗。
57、本发明中设计的围捕联盟是动态的,实时对环境以及目标智能体的状态进行评估,并在必要时解散联盟,形成新的联盟,从而保证航行器资源的有效利用,并提高围捕任务的效率。
本文地址:https://www.jishuxx.com/zhuanli/20240730/197931.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表