一种基于改进的MADDPG算法的车辆路径规划方法及系统
- 国知局
- 2024-07-31 23:44:21
本发明属于路径规划,涉及一种基于改进的maddpg算法的车辆路径规划方法及系统。
背景技术:
1、路径规划是运动规划的主要研究内容之一。运动规划由路径规划和轨迹规划组成,连接起点位置和终点位置的序列点或曲线称之为路径,构成路径的策略称之为路径规划。路径规划在很多领域都具有广泛的应用。在高新科技领域的应用有:车辆行驶路程归还:机器人的自主无碰行动;无人机的避障突防飞行;巡航导弹躲避雷达搜索、防反弹袭击、完成突防爆破任务等。在日常生活领域的应用有:gps导航;基于gis系统的道路规划;城市道路网规划导航等。在决策管理领域的应用有:物流管理中的车辆路径问题(vehiclerouting problem,vrp)及类似的资源管理资源配置问题。通信技术领域的路由问题等。凡是可拓扑为点线网络的规划问题基本上都可以采用路径规划的方法解决。目前车辆的路径规划算法大部分研究在单车路径规划方面。
2、公开号为cn116358594a的中国发明专利公开了一种车辆路径的规划方法和装置,该方法的一具体实施方式包括:响应于车辆路径的规划请求,获取车辆途经点信息和多个规划目标;按照预先设置的规划参数,根据车辆途经点信息生成第一路径集合;对第一路径集合进行进化处理和变邻域操作处理,生成第二路径集合;基于多个规划目标,通过第一路径集合和第二路径集合,生成车辆路径的规划结果。该实施方式能够设置多个规划目标,并基于进化处理和变邻域操作处理,针对多个规划目标进行路径规划,并降低路径规划的时间复杂度,提高实时响应度。但是上述专利在实施的过程中仍存在以下问题:
3、上述专利公开的一种车辆路径的规划方法和装置,虽然通过设置多个规划目标,并基于进化处理和变邻域操作处理,针对多个规划目标进行路径规划,降低了路径规划的时间复杂度,提高实时响应度,但是仍然没法在复杂环境和变数较多的问题中求解出最优路径。
技术实现思路
1、本发明的目的是提供一种基于改进的maddpg算法的车辆路径规划方法及系统,能够覆盖环境中大部分的行驶重点以及避免障碍和高坡度点,获得较高的总奖励值。
2、为解决上述技术问题,本发明是采用下述技术方案实现的。
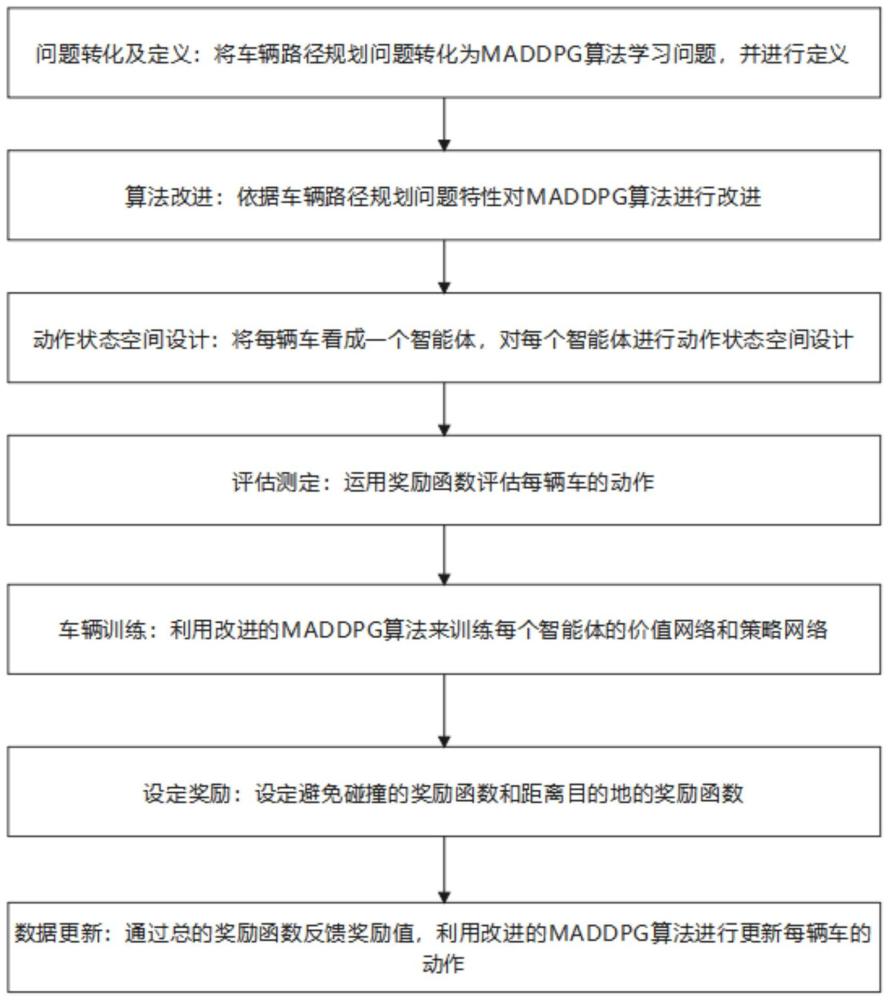
3、第一方面,本发明提出了一种基于改进的maddpg算法的车辆路径规划方法,包括:
4、将车辆路径规划问题转化为maddpg算法学习问题,并进行定义;
5、根据车辆路径规划问题特性对maddpg算法进行改进;
6、将每辆车看成一个智能体,对每辆车进行动作状态空间设计;
7、运用奖励函数评估每辆车的动作;
8、利用改进的maddpg算法来训练每辆车的价值网络和策略网络;
9、设定避免碰撞的奖励函数和距离目的地的奖励函数;
10、基于避免碰撞的奖励函数和目的地距离的奖励函数,得到总的奖励函数,通过总的奖励函数反馈奖励值,利用改进的maddpg算法进行更新每辆车的动作。这样每个智能体通过奖惩函数得到最大reward值,进而协同规划多个智能体的路径,以到达各自的目的地。
11、其中,所述问题特性包括上报事件点、路上障碍情况以及建筑面积分布情况中会存在的问题。
12、结合第一方面,进一步地,将车辆路径规划问题转化为maddpg算法学习问题,并进行定义的具体步骤为:
13、将车辆行驶区域进行栅格化,并将每个栅格点的坐标及对应的栅格属性特征作为智能体所处的状态;定义智能体在栅格化的车辆行驶区域具有的总计动作,根据所述总计动作来确定输出动作的维度,依据车辆行驶区域的栅格属性特征定义奖励函数。
14、其中,所述智能体所处的状态指智能体的位置信息。所述栅格属性特征指栅格大小代表空间分辨率,值代表该位置的属性。
15、结合第一方面,进一步地,对maddpg算法进行改进的方法为:
16、将价值网络和策略网络输出层的激活函数修改为自适应激活函数,并在自适应激活函数中加入平滑性约束。
17、结合第一方面,进一步地,对每辆车进行动作状态空间设计的方法为:
18、对于第i辆车的第t时刻速度信息所有车辆的动作集合构成了整个系统的动作空间;
19、对于第i辆车的第t时刻位置信息整个系统的状态是所有车辆的状态的集合;
20、其中,i表示第i个车辆的编号;t表示时间,t=1,2,…,t。
21、结合第一方面,进一步地,运用奖励函数评估每辆车的行为的方法为:
22、统计每辆车与目的地的距离,同时避免碰撞,根据总的奖惩函数中的避免碰撞和距离目的地得出奖励值;
23、其中,每辆车与目的地的距离越近,则获得奖励值越大;每辆车与其他车辆的距离小于最小距离,则获得负的奖励值。
24、结合第一方面,进一步地,利用改进的maddpg算法来训练每辆车的价值网络和策略网络的具体方法为:
25、通过利用改进的maddpg算法来训练每辆车的价值网络和策略网络,通过多次训练和演示,使得每辆车能够学习到在多车辆环境中的最优策略,以利于后续计算。
26、结合第一方面,进一步地,通过总的奖励函数反馈奖励值,利用改进的maddpg算法进行更新每辆车的动作方法为:
27、让多辆车根据当前状态选择下一步的动作,之后进行车辆动作上的统析,并根据总的奖励函数进行反馈,然后利用改进的maddpg算法得出奖励值,最后进行更新每辆车的动作。
28、其中,所述当前状态指当前自身车辆速度信息位置信息以及其他智能体的速度信息和位置信息。
29、结合第一方面,进一步地,设定避免车辆碰撞的奖励函数和距离目的地的奖励函数的方法为:
30、引入平滑惩罚函数,设定避免车辆碰撞的奖励和目的地距离的奖励,同时为了简化和增加对路径偏离的平滑惩罚,采用一个与路径偏差成正比的惩罚项,同时引入一个非线性项以避免小的偏差导致大的惩罚;通过引入一个平滑的惩罚函数,以避免因两车距离变小而导致的奖惩值急剧变化,这样可以使学习过程更加平稳;
31、所述平滑惩罚函数(即避免车辆碰撞的奖励函数)的表达式如下:
32、
33、上式中,r'collision表示惩罚值;α是控制衰减速度的参数,为预设值;dsafe是安全距离,根据经验设定得到;pi(t)表示车辆自身的位置;pj(t)表示其他车辆的位置;n表示共有n个车辆;i、j皆表示车辆的编号;i=1,2,......,n,j=1,2,......,n-1,i≠j;t表示时间,t=1,2,…,t;当两车的距离大于dsafe时,惩罚值接近0;而当两车的距离小于dsafe时,惩罚值增大;
34、距离目的地的奖励函数的表达式如下:
35、
36、上式中,r'path表示距离目的地的奖励值;pi,target表示对于第i个车辆的目的地;||pi(t)-pi,target||依然表示车辆i在时间t的位置与其在路径上的目标位置点之间的欧式距离;γ是一个正的缩放参数,为调节因子,用于调整目标位置与智能体位置之间距离的惩罚强度,即用于调整路径偏差的影响程度;上式中的log部分用于确保即使距离误差小,从而允许存在偏差,使得学习过程更加平滑和鲁棒。
37、第二方面,本发明提供一种基于maddpg算法的车辆路径规划系统,包括:
38、问题转化及定义模块,被配置用于将车辆路径规划问题转化为maddpg算法学习问题,并进行定义;
39、算法改进模块,被配置用于根据车辆路径规划问题特性对maddpg算法进行改进;
40、动作状态空间设计模块,被配置用于将每辆车看成一个智能体,对每辆车进行动作状态空间设计;
41、评估测定模块,被配置用于运用奖励函数评估每辆车的动作;
42、车辆训练模块,被配置用于利用改进的maddpg算法来训练每辆车的价值网络和策略网络;
43、设定奖励模块,被配置用于设定避免碰撞的奖励函数和距离目的地的奖励函数;
44、数据更新模块,被配置用于基于避免碰撞的奖励函数和目的地距离的奖励函数,得到总的奖励函数,通过总的奖励函数反馈奖励值,利用改进的maddpg算法进行更新每辆车的动作。
45、第三方面,本发明提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时,实现上述的基于改进的maddpg算法的车辆路径规划方法的步骤。
46、第四方面,本发明提供一种计算机设备,包括:
47、存储器,用于存储计算机程序;
48、处理器,用于执行所述计算机程序以实现上述的基于改进的maddpg算法的车辆路径规划方法的步骤。
49、第五方面,本发明提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现上述的基于改进的maddpg算法的车辆路径规划方法方法的步骤。
50、与现有技术相比,本发明所达到的有益效果:
51、(1)本发明解决了如何在复杂环境和变数较多的问题中求解出最优路径的问题,能够覆盖环境中大部分的行驶重点以及避免障碍和高坡度点,获得较高的总奖励值。
52、(2)本发明基于改进的maddpg算法综合考虑了多种因素的影响,规划的最优路径的长度短,灵活性高。
本文地址:https://www.jishuxx.com/zhuanli/20240730/198369.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表