一种基于最大熵强化学习的耙吸挖泥船挖掘装舱控制方法
- 国知局
- 2024-08-01 00:18:23
本发明设计涉及耙吸船挖泥装舱工艺优化领域,尤其涉及一种基于最大熵强化学习的耙吸挖泥船挖掘装舱控制方法。
背景技术:
1、耙吸挖泥船是一种应用广泛的疏浚装备,具备高稳定性和高效率的挖泥装舱能力。耙吸挖泥船的疏浚作业过程由多个子系统共同完成,其中包括耙头挖掘过程、管线输送过程和泥舱沉积过程等。耙吸船子系统之间、各子系统内部存在复杂的相互制约和耦合关系,难以使用数学模型进行准确描述,随着人工智能技术的快速发展,基于数据驱动建模为耙吸挖泥装舱控制及工艺寻优提供了可行的技术方案。
2、目前在耙吸挖泥船疏浚作业过程中,施工人员往往依赖人工经验进行施工,疏浚效率容易受到施工人员状态和经验影响,限制了疏浚设备最大效率发挥。因此,迫切需要一种能够自适应疏浚工况的智能疏浚系统及其控制方法,提高挖泥装舱的效率。
3、在前人的研究中,利用挖泥船的挖泥装舱纯机理模型对施工参数进行寻优的方法较为常见,通过启发式寻优算法和限定施工参数合理范围,在环境模型中进行持续搜索,以获取一组更优的挖泥装舱初始施工参数。这些优化方法在取得一定效果的同时,也存在一些问题:1)纯机理模型对挖泥船非线性疏浚过程进行了简化,控制精度及效果不佳,不能对现实作业进行精确指导;2)数据驱动的启发式寻优算法无法根据挖泥船疏浚工况的变化自适应调整,导致控制模型泛化性能不够。
4、中国专利202311356424.7提出了一种基于强化学习的耙吸船泥舱沉积过程控制方法。该方法通过建立挖泥船装舱环境的机理模型,并利用强化学习对模型进行自主寻优控制,以获取最优参数轨迹,从而实现疏浚效率的最优化。然而,该方法存在一定的弊端,数学机理模型未能完全反映真实的疏浚环境,导致智能体在实际施工过程中会产生累积偏差,从而降低了挖泥船的疏浚效率。由于耙吸挖泥船挖泥工艺的复杂性,耙头部分的多种参数组合可能对泥舱沉积产生相同的影响,使得智能体在输出动作参数时,参数会产生偶然性的跳变,仅对泥舱进行过程控制无法准确指导现实作业,导致智能体控制不稳定和效果不佳。
技术实现思路
1、针对现有技术中的不足,本发明提供了一种基于最大熵强化学习的耙吸挖泥船挖掘装舱控制方法,以解决现有技术中寻优过程探索不充分、复杂导致耙吸挖泥船挖掘装过程控制参数不合理的技术问题。
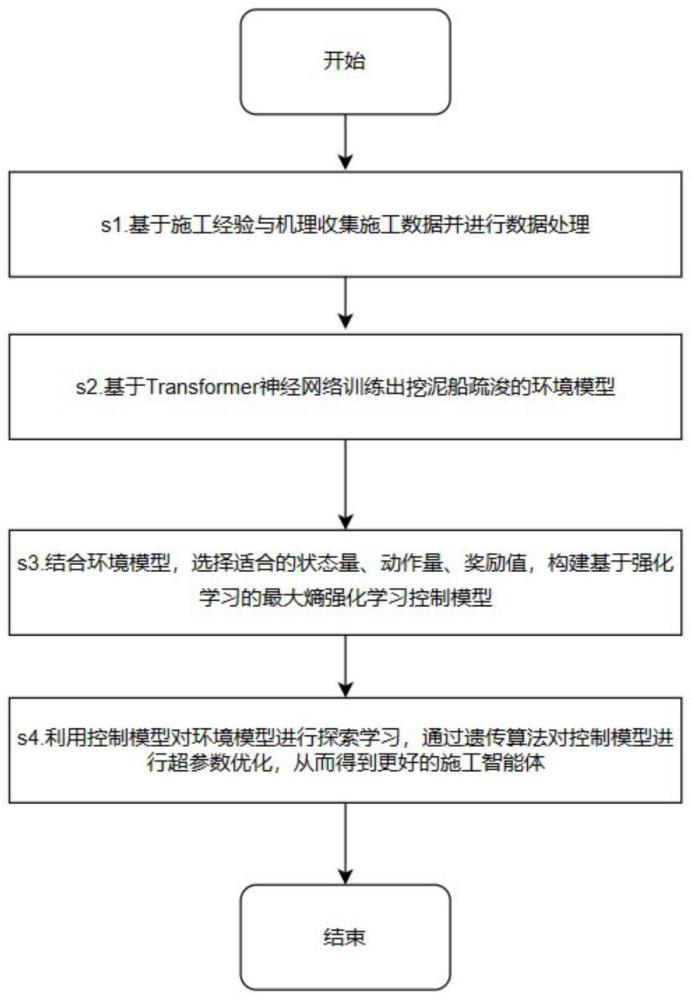
2、本发明提供了一种基于最大熵强化学习的耙吸挖泥船挖掘装舱控制方法,包括如下步骤:
3、步骤1:获取连续天数的耙吸船挖掘装舱施工数据,并对数据进行预处理;
4、步骤2:基于transformer模型构建耙吸船的环境量预测模型,并用步骤1获取的数据对环境量预测模型进行训练,通过环境量预测模型对环境量进行预测;
5、步骤3:构建最大熵强化学习控制模型,将环境预测模型输出结果作为最大熵强化学习控制模型的状态量;
6、步骤4:训练最大熵强化学习控制模型,用训练好的最大熵强化学习控制模型根据实际的耙吸船挖掘装舱施工数据获取挖掘装舱最优控制动作,对耙吸船挖掘装舱进行控制。
7、进一步地,所述环境量包括:装舱质量、装舱体积、土方量。
8、进一步地,所述步骤2中,环境量预测模型中的概率稀疏注意力模块的函数为:
9、
10、式中,a(qi,k,v)为第i个查询q的注意力;k(qi,kj)第i个查询q的key值;vj为第i个查询q的注意力的value值;a(q,k,v)为第i个稀疏自注意力得分;q为所有键映射的查询矩阵,k为所有键映射的键矩阵,v为所有值映射的值矩阵;为稀疏查询矩阵;softmax()为归一化指数函数。
11、进一步地,所述步骤3中,最大熵强化学习控制模型的奖励函数为:
12、
13、式中,vt为当前时刻环境中的土方量;max(vt,vt+δvs(t))为当前模型控制得到的最大土方量;α、β为奖惩因子;vlimit为波动函数vgap的限制范围;δvs(t)limit为土方增量δvs(t)限制范围;δ为d的乘数项系数;d为该时刻的控制参数与上一时刻控制参数的欧氏距离偏差。
14、进一步地,所述步骤3中,最大熵强化学习控制模型中策略熵为:
15、hp=-log[π(am|sm)]
16、策略网络的损失函数为:
17、
18、式中,m为训练批次的经验样本总数;hp为通过策略网络计算的策略熵;q2,m为将第m个经验样本输入价值神经网络q2后得到的价值;q1,m为将第m个经验样本输入价值神经网络q1后得到的价值;τ为温度系数;hp为策略熵。
19、进一步地,所述步骤3中,最大熵强化学习控制模型包括两个价值网络。
20、进一步地,两个所述价值网络中的一个价值网络的损失函数为:
21、
22、式中,m为训练批次的经验样本总数;γ为折扣因子;q1,m为将第m个经验样本输入价值神经网络q1后得到的价值;r(sm,am)为第m个经验样本的奖励值;q′target,1,m为将第m个经验样本输入目标价值神经网络q′1后得到的价值;q′target,2,m为将第m个经验样本输入目标价值神经网络q′2后得到的价值;τ为温度系数;hp为策略熵。
23、进一步地,所述步骤3中,温度系数的损失函数为:
24、
25、式中,m为训练批次的经验样本总数;hp为通过策略网络计算的策略熵;htarget,p为初始目标策略熵。
26、进一步地,所述步骤4中,在训练最大熵强化学习控制模型的过程中,通过遗传算法对最大熵强化学习控制模型的超参数进行优化。
27、进一步地,所述遗传算法的适应度函数为:
28、
29、式中,m为一轮训练中智能体与环境的交互次数;ri(sm,am)为每次智能体与环境交互得到的奖励值。
30、本发明的有益效果:
31、本发明发挥transformer神经网络建模的优点,挖泥船的挖掘装舱作业涉及到复杂的水底情况、泥沙颗粒的特性以及水流等多种因素,transformer神经网络可以帮助捕捉这些复杂的环境序列特征,从而更好地模拟挖泥船挖泥装舱作业中的各种情况和变化。降低了环境建模的难度,增加了模型的真实性与准确性。
32、本项发明采用概率稀疏注意力机制和知识蒸馏的思想,通过进一步简化transformer模型,显著减少数据中的冗余信息,从而大幅提高了模型的训练速度。这不仅降低了模型的复杂度,还在不损失性能的前提下提高了训练效率,可以快速搭建一个精度较高的土方量预测模型。
33、本发明采用最大熵强化学习对环境模型进行控制策略寻优,对比于现有在挖泥船使用的强化学习控制技术,最大熵强化学习算法可以引导控制模型对环境进行充分探索,超参数不敏感,无需大量调整模型参数,更具有鲁棒性和泛化性。
34、本发明添加自适应的温度系数,确保智能体在学习过程中既能够利用当前已知的策略来最大化累积奖励,又能够探索未知的状态和动作空间,以更全面地学习环境的特性。
35、本发明引入了欧式距离和奖惩因子到模型的奖励函数中,以优化挖泥船疏浚工况下的强化学习。通过考虑挖泥船不同时间下动作的空间位置关系,欧式距离提供了更准确的位置信息,限制两次输入信号之间的变化幅度,防止控制参数剧烈跳变,而奖惩因子则实现了对模型反馈的动态调节。这使得奖励函数更为精细、灵活,能够更好地满足挖泥船在实际工作中的需求,提高操作效率和适应。
本文地址:https://www.jishuxx.com/zhuanli/20240730/200527.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。