用于增强图像质量的方法和系统与流程
- 国知局
- 2024-08-19 14:33:04
本公开涉及视频压缩方案,该视频压缩方案可以通过有效去除压缩伪影提升编码效率。更具体地,本公开涉及用于提供弱连接密集注意力神经网络(weakly-connected-dense-attention-neural-network,wcdann)框架以提升压缩视频/图像的图像质量的系统和方法。
背景技术:
1、常见的图像和视频压缩方法包括使用(例如,用于静态图像的)联合图像专家组(joint photographic experts group,jpeg)标准,以及(例如,用于视频的)高效视频编码(high efficiency video coding,hevc)和通用视频编码(versatile video coding,vvc)标准的方法。在这些方法中,在编码过程中执行了量化和预测过程,导致压缩图像/视频中不可逆的信息损失和各种压缩伪影,例如,块效应(blocking)、模糊(blurring)、以及色带(banding)。这一缺点在使用高压缩比时尤为明显。
2、为了解决上述缺点,使用了多种基于深度学习的方法。这些方法包括基于金字塔结构的框架/网络。这类网络首先提取输入图像不同尺度的特征,对小尺度特征进行连续上采样,然后将上述小尺度特征与大尺度特征融合,最后获取与输入图像尺度相同的输出。这种方法通常复杂并且需要许多卷积操作,从而处理不同尺度的信息。这些方法对输入图像的大小也有严格的要求,并且因此不能适用于所有大小的图像。
3、其他方法包括基于块堆叠(block stacking)的框架/网络。最常见的是基于密集块或残差块的网络。通过堆叠多个块,可以学习并使用特征信息以增强图像质量。然而,这类网络在结构上相对简单并且需要大量的网络参数。此外,因为仅使用单一类型的块,所以网络的学习能力和特征选择能力也受到限制。
4、现有的残差学习方法的缺点包括没有充分利用网络中的残差特征,而只是在时间上部分选择残差特征。因此,网络学习的残差图像仅包括输入图像中的一小部分失真区域。因此,改进的系统和方法有利于解决前述缺点。
技术实现思路
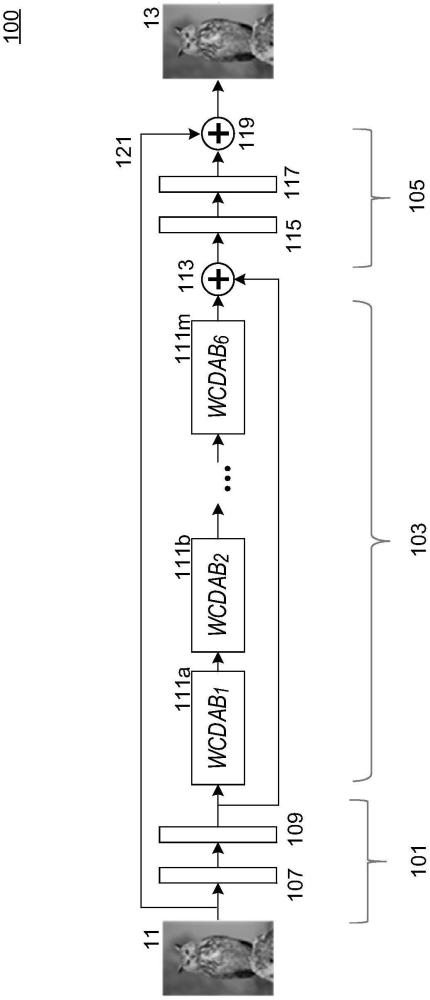
1、本公开涉及用于基于残差信息改进视频的图像质量的系统和方法。可以通过深度学习和/或人工智能方案训练残差信息。本公开提供了一种用于基于训练的残差信息提升输入图像的图像质量的弱连接密集注意力神经网络(weakly-connected-dense-attention-neural-network,wcdann)框架(例如,图1)。wcdann框架通过消除或减轻图像和视频中的压缩伪影(例如,块效应、模糊、以及色带)提升压缩的图像(例如,通过jepg)和/或视频(例如,通过hevc或vvc)的整体图像质量。例如,测试结果(图8a至图8e和图9a至图9e)显示wcdann框架可以有效地消除各种压缩伪影并相应地增强图像质量。
2、wcdann框架使用残差信息提升输入图像的质量。wcdann框架包括多个弱连接密集注意力块(weakly connected dense attention block,wcdab),以从输入图像中提取有用的残差信息(图1)。连接多个wcdab,使得可以循环并依次处理残差信息。多个wcdab中的每一个wcdab还包括多个残差注意力块(residual attention block,rab)(图2)。
3、在一些实施例中,wcdann框架包括两个注意力模块,(rab中的)通道注意力块(channel attention block,cab)模块和(wcdab中的)通道空间注意力块(channel-spatial attention block,csab)模块,以增强rab(例如,图3)和wcdab(例如,图2b)的输出中的残差特征。wcdann框架使用“深度(depth-wise)”可分离卷积方法处理rab(图3),大大减少了模型参数的数量(图4a和图4b),因此是一种“轻量级”网络。“轻量级”rab可以用作从大感受野中提取特征的基本单元(图5),并从提取的特征中强调重要通道。通过这种布置,本方法可以在减少计算资源的情况下有效提升图像质量。
4、在一些实施例中,本方法可以通过有形、非暂时性、计算机可读的介质实现,该介质上存储有处理器指令,当被一个或多个处理器执行时,上述处理器指令使得一个或多个处理器执行本文描述的方法的一个或多个方面/特征。
技术特征:1.一种用于视频处理的方法,包括:
2.根据权利要求1所述的方法,其中,所述wcdab包括两个或两个以上残差注意力块(rab)。
3.根据权利要求2所述的方法,其中,所述rab包括双分支结构,其中,所述双分支结构的卷积层是深度可分离卷积层,并且其中,所述深度可分离卷积层包括深度部分和点部分。
4.根据权利要求3所述的方法,其中,所述双分支结构包括第一分支和第二分支,其中,所述第一分支包括具有第一维度的第一卷积层,并且其中,所述第二分支包括具有第二维度的两个第二卷积层。
5.根据权利要求4所述的方法,其中,所述第一维度与所述第二维度相同。
6.根据权利要求5所述的方法,其中,所述第一维度为三乘三(3×3)。
7.根据权利要求4所述的方法,其中,具有所述第一维度的所述第一卷积层对应于第一感受野,并且其中,所述两个第二卷积层对应于第二感受野。
8.根据权利要求7所述的方法,其中,所述第二感受野大于所述第一感受野。
9.根据权利要求7所述的方法,其中,所述第一感受野是三乘三(3×3)的野,并且其中,第二感受野是五乘五(5×5)的野。
10.根据权利要求7所述的方法,其中,所述rab用于执行通道混洗操作以整合来自所述第一感受野和所述第二感受野的特征。
11.根据权利要求10所述的方法,其中,所述rab用于在所述通道混洗操作之后形成普通卷积层,其中,所述普通卷积层用于执行通道降维操作以形成特征图。
12.根据权利要求11所述的方法,其中,所述rab包括用于强调所述特征图中的通道的通道注意力块(cab)模块。
13.根据权利要求1所述的方法,其中,所述wcdab包括用于增强所述残差特征的所述部分的csab模块,并且其中,所述csab模块包括通道注意力块(cab)分支和空间注意力块(sab)分支。
14.根据权利要求13所述的方法,其中,所述cab分支用于处理来自所述wcdab的两个或两个以上rab的输入特征以形成通道注意力图,并且其中,所述sab分支用于处理所述输入特征以形成空间注意力图。
15.根据权利要求14所述的方法,还包括合并所述通道注意力图和所述空间注意力图以形成通道空间联合注意力图。
16.根据权利要求13所述的方法,其中,所述sab分支包括两个不同大小的并行卷积层以卷积输入特征。
17.一种用于视频处理的系统,包括:
18.根据权利要求17所述的系统,其中,所述指令还用以:
19.一种用于视频处理的方法,包括:
20.根据权利要求19所述的方法,其中,所述csab模块包括通道注意力块(cab)分支和空间注意力块(sab)分支,其中,所述cab分支用于处理来自所述rab的输入特征以形成通道注意力图,并且其中,所述sab分支用于处理来自所述rab的所述输入特征以形成空间注意力图,并且其中,通过合并所述通道注意力图和所述空间注意力图形成通道空间联合注意力图。
技术总结提供了用于视频处理的方法和系统。在一些实施例中,该方法包括(i)接收输入图像(1201);(ii)通过头部网络提取输入图像的浅层特征(1203);(iii)基于浅层特征确定输入图像的残差特征,并由两个或两个以上弱连接密集注意力块(WCDAB)增强残差特征的一部分(1205);(iv)重建残差特征以形成残差图(1207);以及(v)将残差图与输入图像相加以生成重建图像(1209)。技术研发人员:郑喆坤,张豪受保护的技术使用者:OPPO广东移动通信有限公司技术研发日:技术公布日:2024/8/16本文地址:https://www.jishuxx.com/zhuanli/20240819/275597.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表