一种基于OPTICS算法的跨轮次对抗后门恶意攻击的联邦机器学习方法
- 国知局
- 2024-09-11 14:22:29
本发明属于人工智能联邦学习领域,尤其涉及联邦学习中的对抗后门恶意攻击方法。
背景技术:
1、联邦学习(federated learning)是一种分布式机器学习技术,其核心思想是通过在多个拥有本地数据的数据源之间进行分布式模型训练,在不需要交换本地个体或样本数据的前提下,仅通过交换模型参数或中间结果的方式,构建基于虚拟融合数据下的全局模型,从而实现数据隐私保护和数据共享计算的平衡,即“数据可用不可见”、“数据不动模型动”的应用新范式。
2、联邦机器学习算法是在分散的用户处通过用户的本地数据和中心服务器下发的数据训练和维护本地模型,并定期将本地模型参数传输到中心服务器。中心服务器通过某种方法对来自不同用户的模型参数进行聚合得到中心模型参数,再将中心模型参数下发给各用户用于其本地模型的更新。
3、自联邦学习方法问世以来,由于其分布式、多客户端通讯的特点,后门恶意攻击的威胁就持续存在。如果在聚合不同客户端的本地模型时,遭遇了后门恶意攻击,中心服务器将会把恶意攻击者发送的虚假参数与诚信节点上传的参数一起聚合,导致模型收到污染,训练效果变差,在攻击者数量较多时,模型甚至会被彻底破坏。因此,需要设计合理有效的方法应对联邦学习中的后门攻击问题,识别并消除恶意攻击者的影响,从而保证训练模型的有效性。多年来研究人员在fedavg基础上提出了大量的算法来解决这一问题。比如multikrum,foolsgold等算法,但这些算法中的分析模块在一些数据集,比如银行信用卡数据集这样的二分类数据集上,表现欠佳;并且这些算法适用于采样率c=1,即每一轮都是全部节点参训的情况,然而在实际的生产应用中,联邦学习参训节点众多,中心服务器每一轮只需采取部分节点上传的结果即可完成聚合,即采样率c<1,在这种情况下,上述算法难以适用。
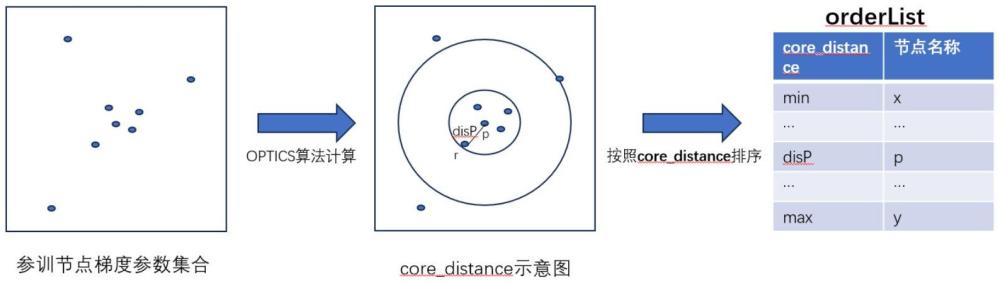
4、optics(ordering points to identify the clustering structure)算法是一种聚类算法,它是基于dbscan算法进行了一些改进得到的新算法。它指出dbscan算法在某些情况下会忽视一些实际可形成簇的“噪点”的缺陷,并加以改进。optics算法在dbscan算法的基础上,引入了两个新概念:核心距离(core distance)与可达距离(reachabilitydistance)。其中,核心距离指的是该样本点与要形成簇所需的至少minpts个样本点之间的距离。可达距离指的是两点之间的距离。利用这两个距离,optics算法会构建两个列表,分别储存每个点的核心距离,以及利用可达距离进一步计算而来的可达分列表,根据可达分的分值高低形成的波峰与波谷来划分聚类。现有技术中,尚没有将optics算法用于联邦学习算法的先例。
技术实现思路
1、技术问题:在基于联邦机器学习的联邦学习算法中,各个节点用户分别根据各自的数据库训练本地数据集得出本地模型参数,然后向中心服务器传输本地模型参数,中心服务器对所有用户的模型参数进行聚合从而生成中心模型,再下发给用户进行下一轮的模型训练。
2、由于其分布式、多客户端通讯的特点,中心服务器易于遭受到恶意攻击者发起的后门攻击,此时直接聚合得到的模型是被严重污染的。
3、针对上述技术问题,本发明提供了一种基于optics算法的跨轮次对抗后门恶意攻击的联邦机器学习方法,利用optics算法计算的核心距离core distance来对每轮参训节点进行排序,再利用信用分机制进行跨轮次的模型诚信程度比较,最终消除恶意攻击者。
4、技术方案
5、一种基于optics算法的跨轮次对抗后门恶意攻击的联邦机器学习方法,其特征在于:利用optics算法对参训节点的诚实情况进行评价并计算其信用分,排除信用分低于阈值的节点,尽可能消除恶意节点的影响;
6、具体包括如下步骤:
7、步骤10:系统随机选取的参训用户接收到中心服务器发送的全局参数,利用机器学习算法进行本地模型的训练和更新,并将更新后的本地模型参数上传给中心服务器;
8、步骤20:中心服务器接收到用户的本地模型参数后,使用optics算法对接收到的本地模型参数进行计算,根据计算结果更新每个节点的信用分;
9、步骤30:中心服务器根据系统设置的阈值和各参训用户的信用分,排除信用分低于阈值的节点,将其余节点根据联邦平均算法进行聚合,得到新一轮的全局参数。
10、进一步:所述步骤20中使用optics算法对本地模型参数进行计算,根据计算结果更新每个节点的信用分的方法为:
11、步骤201:中心服务器使用optics算法对接收到的本地模型参数进行计算,得到本轮参训节点的排序结果orderlist;
12、步骤202:中心服务器根据排序结果orderlist,更新本轮所有参训节点的信用分credits;
13、进一步:所述步骤201中计算上传节点的排序结果orderlist的方法为:
14、步骤2011:中心服务器加载上传节点的模型参数数据
15、步骤2012:使用optics算法对模型参数数据进行聚类计算,得到各节点的核心距离core distance;
16、步骤2013:对各节点的核心距离core distance进行升序排序,得到排序结果orderlist。
17、进一步:所述步骤202中根据排序结果orderlist,更新本轮所有参训节点的信用分credits的方法为:
18、步骤2021:计算本轮信用分变动的节点数量nprop
19、nprop=th×c×k
20、其中,th为总体威胁程度,其取值应为后门恶意攻击者占总训练节点数量的比例(不能超过50%);c为采样率,即每一轮参训节点占总节点数量的比例;k为节点总数量。
21、步骤2022:根据排序结果orderlist更新本轮参训节点的信用分,对orderlist前nprop个节点增加信用分α,对orderlist后nprop个节点减少信用分α,得到更新后的各参训节点信用分credits;α的取值由节点在orderlist中的位次i决定,具体为:
22、
23、其中,β为参数,一般取1;
24、步骤2023:规范限制更新后的各节点信用分credits在范围[-2β,2β]内,避免极端值干扰后续计算。
25、进一步:所述步骤30中排除信用分低于阈值的节点,将其余节点根据联邦平均算法进行聚合,得到新一轮的全局参数的方法为:
26、步骤301:计算本轮参训节点中的最低信用分min credits;
27、步骤302:遍历本轮参训所有节点的信用分credits,如果参训节点的信用分等于最低信用分min credits且小于系统的设置的阈值m,则将该节点从本轮参与聚合计算的集合sr中删除。其中,阈值m一般取值为m=1。
28、步骤303:对其余节点进行联邦平均计算,得到新一轮的全局参数:
29、
30、有益效果
31、本发明通过optics算法计算出每一轮参训节点的排序情况,再通过全局有效的信用分机制,从而跨轮次对所有节点进行诚信度比较,从而有效识别恶意攻击者,保护联邦学习模型免受或降低恶意攻击者的影响。
本文地址:https://www.jishuxx.com/zhuanli/20240911/290446.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。