基于多目标多智能体的深度强化学习交通信号控制方法
- 国知局
- 2024-09-14 15:02:37
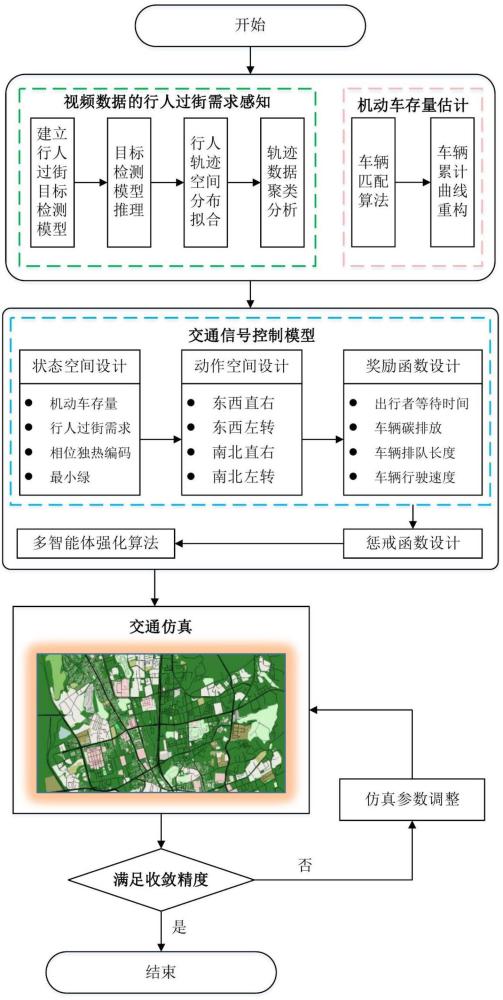
本文发明涉及一种基于多目标多智能体的深度强化学习信号控制方法,用于城市交通信号控制领域,属于智能交通领域。
背景技术:
0、技术背景
1、随着人工智能技术的快速发展,基于数据驱动的强化学习(reinforcementlearning,rl)在智能交通信号控制领域应用广泛。强化学习无需对复杂环境进行建模,其灵活性和适应性使之与多变的交通环境相得益彰。这为基于模型的交通信号控制提供了新的思路和方法。目前,现有的交通信号控制工作大多数以车辆作为优化目标,没有考虑到车辆尾气排放和行人在交叉口的过街需求。本发明提出一种基于多目标多智能体的深度强化学习交通信号控制方法,以缓解交通拥堵,减少车辆尾气排放和行人的等待时间,提高交叉口的通行效率。
技术实现思路
1、本发明针对上述的问题,提出一种基于多目标多智能体的深度强化学习信号控制方法。本发明在满足交叉口斑马线处行人的过街需求的同时减少车辆在交叉口处的停车次数和等待时间,进而降低交叉口处的车辆尾气排放,缩短行人的等待时间。
2、本发明的基本步骤如下。
3、s1:构建交叉口仿真路网模型。
4、s2:基于视频数据的交叉口斑马线行人过街需求感知。
5、s3:构建基于深度强化学习定义的交通系统的状态、动作、奖励。
6、s4:构建多目标多智能体的深度强化学习模型。
7、步骤s1的过程包括。
8、使用sumo仿真软件构建交叉口路网模型。使用netedit构建路网模型,设置路段与交叉口的属性,设置路网中交通流属性(速度、车辆类型等)。
9、步骤s2的过程包括。
10、s21:建立基于视频数据的行人过街目标检测模型。
11、s22:对行人过街目标检测模型进行推理,处理模型推理输出的标签数据。
12、s23:对行人轨迹的空间分布进行估计,分析行人空间轨迹特征。
13、s24:对轨迹数据进行聚类分析,提取行人过街的起讫点,根据不同时间的过街人数,提取行人过街的动态 od 矩阵。
14、s3的过程包括。
15、s31:状态空间设计。
16、基于视频数据的行人过街需求的估计结果的基础上,使用独热编码方法,对交通信号控制的相位信息进行编码,同时考虑各相位的最小绿灯信息和路段机动车动态存量,设计强化学习的状态。
17、s32:动作空间设计。
18、智能体通过执行器与环境进行交互,并执行相应的行动。在智能信号控制领域中,动作集合通常是离散的,主要分为固定相序和可变相序两种。在实际路网中,相位的选择主要取决于交叉口的实际交通状况,包括其几何形状、渠化设计、交通流量以及其他特定的控制目标,相位可以根据具体需求进行设计。目前,对于常见的十字路口,通常采用东西直行、东西左转、南北直行、南北左转四个相位。
19、s33:奖励函数设计。
20、智能体的目标为缓解交通拥堵、缩短行人等待时间和减少车辆的尾气排放。因此,建立出行者总延误最小目标、车辆碳排放最小目标、排队长度最小目标、速度最大目标,构建不同目标的权重系数自适应优化模型。
21、定义时刻的奖励函数定义如下。
22、
23、其中表示出行者等待时间奖励函数;表示二氧化碳排放奖励函数;表示排队长度奖励函数;表示车辆速度奖励函数;表示权重系数。
24、s34:惩戒函数设计。
25、通过惩戒函数,引导智能体在未来学习过程中避免采取使用糟糕的动作。当智能体的累计奖励低于某个阈值时,给奖励分配一个惩罚值;当路网中某个车辆等待时间过长,给奖励分配一个惩罚值;当行人的等待时间超过行人可容忍时间时,行人容易出现闯红灯违反交通规则的行为,对行人的过街等待时间设计行人等待时间阈值,当行人等待时间超过阈值时,给奖励分配一个惩戒值,以减少行人闯红灯行为。
26、
27、
28、
29、其中表示累计奖励;表示累计奖励阈值;表示车辆等待时间;表示车辆等待时间阈值;表示行人等待时间;表示行人等待时间阈值。
30、s4:构建多目标多智能体的深度强化学习模型。
31、maddpg(multi-agent deep deterministic policy gradient)算法是一种先进的多智能体强化学习技术,它通过让多个智能体在共享环境中协同学习,解决了多智能体系统中的协作与竞争问题。maddpg算法允许智能体在不需要了解环境动力学模型的情况下,通过相互观察和学习来快速收敛到最优策略,从而在复杂的动态环境中展现出强大的适应性和灵活性。所以,本发明的多目标强化学习模型选择maddpg算法,算法的网络包括:策略网络、价值网络和目标网络,其中价值网络包括:局部价值网络和全局价值网络。模型的输入为路口当前的交通状态,输出为动作的概率分布。局部价值网络用于评估智能体在特定状态下采取动作的价值,同时考虑个体奖励和邻近智能体的影响;全局价值网络从全局视角评估智能体的价值,旨在最大化整个系统的奖励。
32、本发明具有以下效益。
33、(1) 本发明通过实时的交通流信息调节交通信号灯的相位切换,缓解交通拥堵和减少交叉口车辆尾气排放。
34、(2) 本发明考虑到交叉口处行人过街的需求,减少行人的过街等待时间、提高行人过街的安全性。
技术特征:1.基于多目标多智能体的深度强化学习交通信号控制方法,其特征在于该方法包括以下步骤。
技术总结本发明公开了一种基于多目标多智能体的深度强化学习交通信号控制方法。本发明提出的方法包括:基于视频数据的交叉口行人过街需求感知,提取行人过街轨迹;设计考虑碳排放和行人过街的状态空间和奖励函数;路段机动车动态存量估计。针对交通拥堵、环境污染等问题,该方法在满足交叉口行人的过街需求的同时减少车辆在交叉口处的停车次数和等待时间,降低交叉口处的车辆尾气排放,缩短行人的等待时间。技术研发人员:孙恩泽,何春光,唐茜,吐尔逊·买买提,周斌,徐粒,胡霆锋,成思怡,王逸飞受保护的技术使用者:新疆农业大学技术研发日:技术公布日:2024/9/12本文地址:https://www.jishuxx.com/zhuanli/20240914/296747.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表