基于视觉提示的连续学习算法
- 国知局
- 2024-09-19 14:39:41
本发明属于人工智能的计算机视觉连续学习,具体涉及一种基于视觉提示的连续学习算法。
背景技术:
1、与在独立和同分布数据上训练的普通监督学习相反,连续学习解决了在非平稳数据分布上训练单个模型的问题,例如:自动驾驶和医疗场景,不同的分类任务数据是顺序呈现的。然而,由于模型只能在学习周期的单个阶段访问当前数据,因此它很容易对当前可用数据进行过拟合,并且由于灾难性遗忘而导致先前训练数据的性能下降。
2、许多研究主要集中在内存空间开辟缓存区,存储过去任务的数据,与当前任务的数据共同对模型进行训练,但是在内存空间有限以及重视隐私的场景无效。而正则化方法不采用缓存区,其限制模型重要参数的更新,但是在复杂场景此方法效果下降严重。采用结构和参数共享的方法,则是在测试阶段需要预先知道数据任务的标签,但是在现实场景中预先知道任务标签是不切实际的。因此有需要开发一种简单高效、无需存储先前任务数据,并且在测试阶段不需要预先知道任务标签的连续学习方法,从而实现与先进工作相似或更高水平的性能。
3、受自然语言处理领域流行的提示学习方法的影响,附加固定或可学习的提示到大规模预训练语言模型,指导模型处理下游任务。受其启发,将提示学习技术引入计算机视觉领域,相比于利用缓存区,提示方法以一种更简明的方式编码知识,而且不需要在内存中存储过去任务的数据,避免了隐私暴露问题的同时解决了内存紧张问题,从一种全新的角度来解决灾难性遗忘问题。
4、目前的视觉提示连续学习方法会产生训练和测试时分类器不一致问题,表现为利用多层感知机分类器对图像进行分类,其分类器在训练阶段只能看到当前任务数据的类别,但是在测试阶段需要包含当前任务和先前任务的类别,从而导致训练和测试的不一致性,使得模型训练和测试时推理会产生偏差。
技术实现思路
1、为解决现有技术的缺点和不足,本发明提供了一种基于视觉提示的连续学习算法。以精确度,遗忘率为衡量指标评价模型的有效性,对于复杂的目标域和复杂的应用场景,使用实例提示生成器,生成实例水平的提示指导模型进行推理决策。针对于训练和测试阶段分类器的不一致性,引入全局提示池,编码任务之间共享的知识,采用紧凑双线性结构对得到的实例特征和全局特征进行多模态特征融合,从而减少模型训练和测试推理时的不一致性所造成的偏差,并且采用池的操作,可以更加多样的对选择的提示进行组合,编码更加丰富的信息,同时实例水平的提示对于复杂的目标域具有更好的可扩展性,提升模型的鲁棒性,使模型泛化能力增强,有利于模型的推理。
2、为了实现上述发明目的,本发明所采用的技术方案如下:
3、一种基于视觉提示的连续学习算法,包括如下步骤:
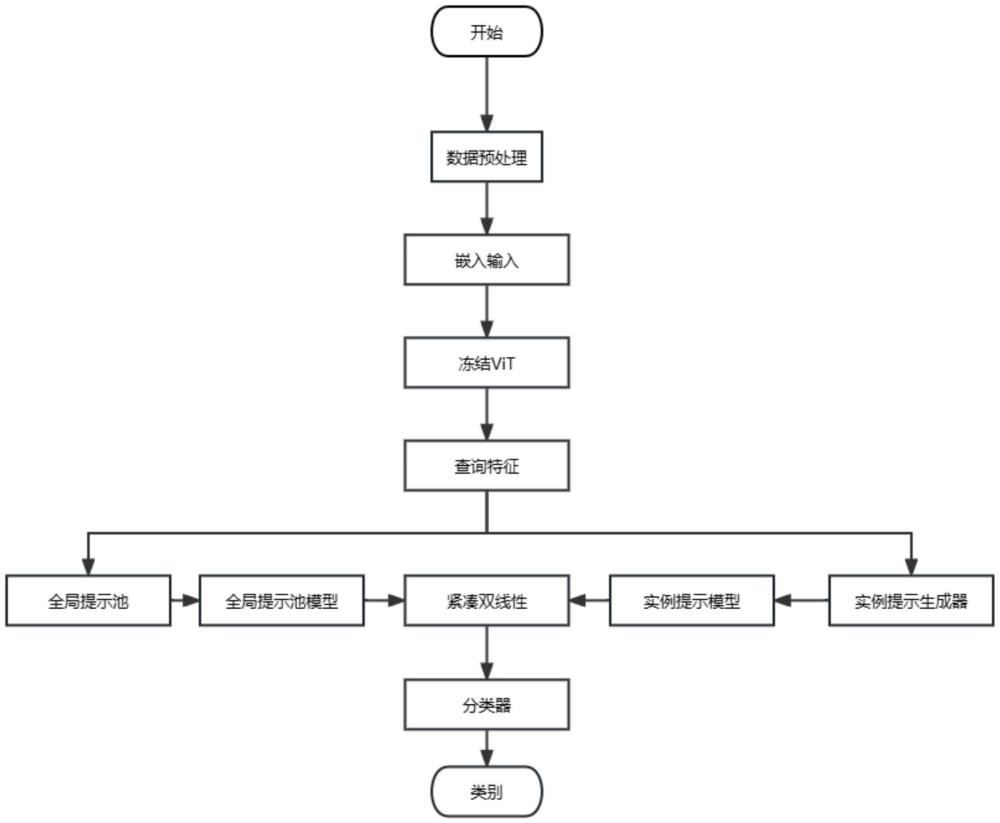
4、步骤1,对目标域图像进行预处理,按比例划分为训练集、验证集,使用类别增量学习的方法对数据集按照任务划分;
5、步骤2,使用冻结的预训练vit模型,得到当前输入图像的查询特征,然后根据键值匹配策略从全局提示池中选择相对应的n个全局提示,将选择的n全局提示进行拼接组合,将其嵌入vit多头注意力层的输入中,指导模型编码目标域的共享知识;
6、步骤3,利用实例提示生成器根据vit多头注意力层的输入生成实例水平的提示,并通过匹配策略根据步骤2的查询特征,得到图像所属的任务,通过查字典操作对生成的实例提示附加额外的任务知识,将实例提示嵌入vit多头注意力层的输入中,从而指导模型更加精确的推理决策;
7、步骤4,对于全局提示池模型的输出和实例提示模型的输出,使用紧凑双线性结构进行多模态特征融合,获取细粒度的表征。将得到的细粒度表征输入分类器中,得到推理结果;
8、步骤5,使用训练阶段得到的权重参数文件对验证集进行验证,验证集评估出来的效果用来调整超参数,最后进行测试并对结果进行评估。
9、进一步的,步骤1中,类别增量设置数据集使得数据是按照任务序列顺序到来的,每个任务包含多个类别,其图像为三通道rgb图形格式,由于采用的基准预训练的模型是vit模型,所以将图像缩放到224×224大小,以适应vit模型的输入尺寸;
10、进一步的,步骤2中,由于特征查询函数的改变可能会导致灾难性遗忘,所以使用冻结的预训练vit模型作为特征查询函数,输入图像通过冻结的vit模型查询到图像所匹配的特征,根据查询的特征和全局提示池中的键进相匹配,键值匹配策略使用余弦相似度作为查询特征和全局池中的键的相似程度的衡量指标,从而从全局提示池中选取合适的全局提示前缀嵌入到vit多头注意力层输入端的键和值上,其中查询输入不嵌入全局提示,指导模型推理。
11、进一步的,步骤3中,实例提示生成器采用vit多头注意力层的输入生成当前实例图像的提示,然后利用步骤2冻结的vit模型生成的查询特征,根据余弦相似度查找当前输入图像所属的任务标签,将生成的实例提示附加任务信息。
12、进一步的,步骤4中,使用多模态紧凑双线性池结构将全局表征知识和实例表征知识进行融合,采用count sketch操作将两个表征向量进行映射,将映射后的两个特征向量分别进行快速傅里叶变换,之后对两个向量进行点积操作生成融合的特征向量,最后将融合的特征向量进行逆快速傅里叶变换,得到两个不同信息水准的融合特征,之后对特征使用有符号根号和l2正则化操作,然后利用多层感知机对图像进行分类。
13、进一步的,步骤5中,验证集评估出来的效果用来搜索调整超参数,如:学习率lr,epochs,momentum,batch_size,全局提示池的大小,提示的长度等参超数。
14、与现有技术相比,本发明的有益技术效果:
15、本发明设计了一种基于视觉提示的连续学习算法。采用实例提示生成器生成针对于输入图像的生成实例提示指导实例提示模型推理,可以很好的适应复杂应用场景,采用全局提示池的操作,可以利用任务共享知识指导全局提示池模型推理,缓解训练和测试阶段分类器不一致性问题。采用池的操作,对于任务数量多的数据域,可以有很好的扩展性,同时能增强模型的鲁棒性。采用多模态紧凑双线性对两个特征向量进行融合,可以充分利用全局知识和实例知识,从而提高精确度和减少遗忘率,同时相比于采用注意力模块进行融合,可以减少模块的参数量。
16、本发明显著的降低了连续学习模型的遗忘率,提高准确率。采用少量可学习的参数可以达到和先进水准模型同样的性能,有效的避免了内存消耗和数据隐私泄露问题,对于复杂场景模型同样适用,并且在推理阶段并不需要预先知道数据任务标签,更符合现实场景的应用。模型的泛化能力更强,同时减少训练和推理时训练器不一致性造成的偏差。
技术特征:1.基于视觉提示的连续学习算法,采用多粒度不同水准的特征信息增强视觉提示模型的性能,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于视觉提示一致性的连续学习算法,其输入图像为三通道rgb图形格式,按照类别增量的方法对目标域数据进行划分,每个任务包含多个类别,使得数据是按照任务序列顺序到来的,由于采用的基准模型是预训练的vit模型,所以将图像缩放到大小,以适应vit模型的输入尺寸。
3.根据权利要求1所述的基于视觉提示一致性的连续学习算法,其特征在于,所述的步骤2中,由于特征查询函数的改变可能会导致灾难性遗忘,所以采用冻结的vit作为查询函数,得到图像的查询特征,键值匹配策略使用余弦相似度作为查询特征和全局池中的键的相似程度的衡量指标,从而从全局提示池中选取合适的全局提示前缀嵌入到vit多头注意力层输入端的键和值上,其中查询输入不嵌入全局提示,指导模型推理。
4.根据权利要求1所述的基于视觉提示一致性的连续学习算法,其特征在于,所述的步骤3中,实力提示生成器采用vit多头注意力层的输入生成当前实例图像的提示,然后利用冻结的vit模型生成查询特征,根据余弦相似度查找当前输入图像所属的任务标签,将生成的实例提示附加任务信息。
5.根据权利要求1所述的基于视觉提示一致性的连续学习算法,其特征在于,所述的步骤4中,紧凑双线性结构将全局表征知识和实例表征知识进行融合,采用count sketch操作将两个表征向量进行映射,将映射后的两个特征向量进行快速傅里叶变换,之后进行点积操作,最后进行逆快速傅里叶变换,得到两个不同信息水准的融合特征,从而利用多层感知机对图像进行分类。
6.根据权利要求1所述的基于视觉提示一致性的连续学习算法,其特征在于,在训练阶段,使用pytorch深度学习框架对训练集进行模型参数的学习,使用验证集在训练的过程中进行精度的计算,并调整超参数。
技术总结本发明公开一种基于视觉提示的连续学习算法,包括:全局提示池模型,实例提示生成器模型以及多模态紧凑双线性特征融合结构。本方法引入全局信息利用任务之间共享的知识指导模型推理训练,合理的对当前实例级表征应用多模态紧凑双线性融入全局知识,从而减少训练和测试时的偏差,并且缓解对过去任务数据的灾难性遗忘。本方法采用少量的可学习提示参数可以帮助深度学习模型更好地理解和利用输入数据不同层次的信息,而且本模型使用实例表征可以更好地适应不同类型和不同变化程度的目标域数据,从而提高模型的泛化能力和鲁棒性。技术研发人员:李仁正,宋博受保护的技术使用者:江苏师范大学技术研发日:技术公布日:2024/9/17本文地址:https://www.jishuxx.com/zhuanli/20240919/299457.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。