一种实时网页数据转换成PDF文件的方法与流程
- 国知局
- 2024-10-09 16:26:16
本发明涉及网页处理应用,具体涉及一种实时网页数据转换成pdf文件的方法,尤其适用于任何站点网页实时转换成pdf的应用领域。
背景技术:
1、目前,在java技术栈中业内常用的html转pdf有itext和wkhtmltopdf两种技术方案。itext是apache组织下使用最广泛的pdf工具,但是有很大的性能瓶颈并且遇到复杂的样式就会转换失败。wkhtmltopdf是github上开源一种框架、性能比itext好遇到复杂样式也能很好转换,但是它需要依赖第三方组件并且不支持html中响应式布局。
2、以上两个框架还有一个共同的问题就是需要先生成行内样式的静态html才能转换,这样无法做到实时html转换。
3、因此,基于现有的技术栈,如何来解决用户的这种困扰,是一个值得关注的技术问题。
4、申请人在思考该问题时发现,大部分移动互联网都是基于react技术做的响应式布局网页,都完美兼容chrome内核浏览器访问,如果能借用chrome内核api的能力来转换pdf,就完美解决性能、复杂样式、响应布局等棘手技术问题。让html转pdf显得非常有价值。
技术实现思路
1、为了解决现有技术在转换过程中普遍存在的问题有内存溢出、字体问题、图像问题、安全性问题、性能问题等的问题,本发明的目的在于提供一种实时网页数据转换成pdf文件的方法,该发明结合app服务端和chrome浏览器的功能,实现了一种可以实时将网页数据转换为pdf文件的有效方法。
2、本发明通过以下技术方案来实现上述目的:
3、一种实时网页数据转换成pdf文件的方法,该方法包括以下步骤:
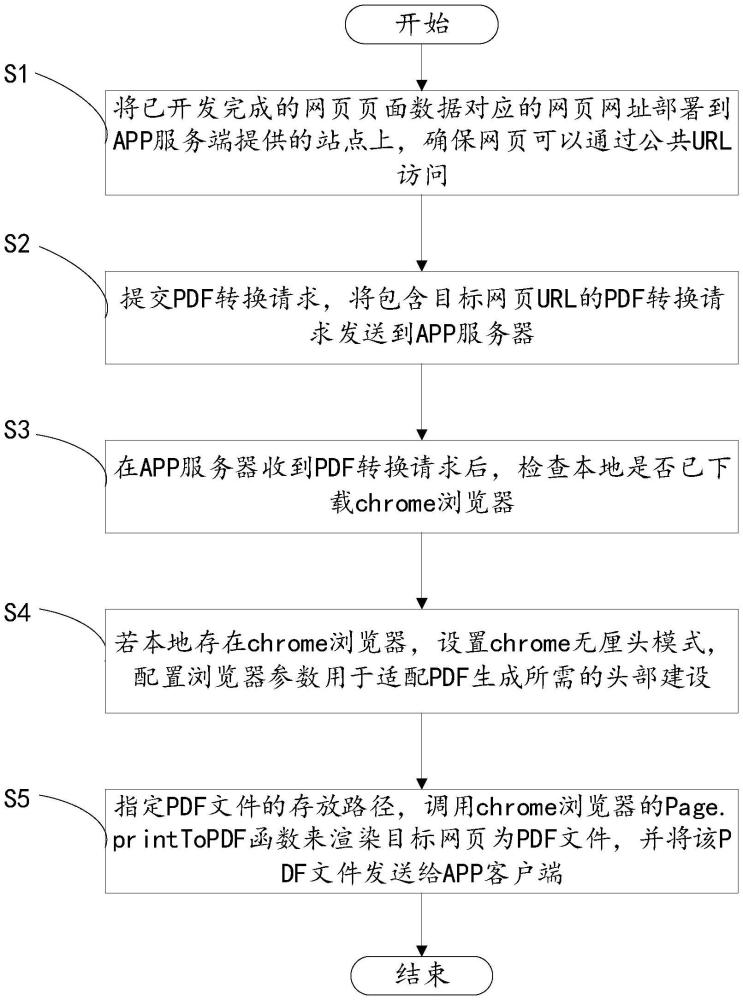
4、将已开发完成的网页页面数据对应的网页网址部署到app服务端提供的站点上,确保网页可以通过公共url访问;
5、提交pdf转换请求,将包含目标网页url的pdf转换请求发送到app服务器;
6、在app服务器收到pdf转换请求后,检查本地是否已下载chrome浏览器;
7、若本地存在chrome浏览器,设置chrome无厘头模式,配置浏览器参数用于适配pdf生成所需的头部建设;
8、指定pdf文件的存放路径,调用chrome浏览器的page.printtopdf函数来渲染目标网页为pdf文件,并将该pdf文件发送给app客户端。
9、根据本发明提供的一种实时网页数据转换成pdf文件的方法,若本地没有下载chrome浏览器,则根据预设的网络地址下载安装包,并安装到指定位置。
10、根据本发明提供的一种实时网页数据转换成pdf文件的方法,在设置chrome无厘头模式时,创建puppeteer代理;设置浏览器启动的参数对象中;创建chrome提取器对象;将chrome提取器对象传入浏览器启动的参数对象中创建浏览器对象;发送target.createtarge获取浏览器中创建好的网页对象。
11、根据本发明提供的一种实时网页数据转换成pdf文件的方法,当chrome浏览器对象创建成功后,设置浏览器上下文id,调用chrome中的target.createtarget方法函数来获取浏览器中创建好的网页对象;
12、基于浏览器中创建好的网页对象,导航到需要转换的html网页地址,等待浏览器导航完成。
13、根据本发明提供的一种实时网页数据转换成pdf文件的方法,在等待浏览器导航完成时,等待导航的阶段结果依次为load事件触发->domcontentloaded事件触发->newworkidle0事件触发->networkidle2事件触发。
14、根据本发明提供的一种实时网页数据转换成pdf文件的方法,当网页创建成功后设置pdf转换参数;
15、在创建pdf文件存放路径后,将该路径传入到创建好的网页对象中;
16、调用chrome浏览器page.printtopdf函数执行pdf转换。
17、根据本发明提供的一种实时网页数据转换成pdf文件的方法,所述pdf转换参数包括转换pdf宽高、上下左右间距、转换模型、是否横屏、隐藏头和脚、头模版、脚模版、是否背后打印、缩放比例、指定pdf文件在页面范围、指定首选的css页面大小、制作范围以及页码范围。
18、根据本发明提供的一种实时网页数据转换成pdf文件的方法,在执行pdf转换之前,清除chrome浏览器的缓存,确保每次都从服务器获取最新的网页内容。
19、根据本发明提供的一种实时网页数据转换成pdf文件的方法,还执行:
20、在启动pdf转换之前,首先检查设备的网络连接状态,确保网络稳定并满足转换需求,并添加网络异常的捕获逻辑,当网络错误发生时,自动重试一定次数,以提高转换成功率。
21、根据本发明提供的一种实时网页数据转换成pdf文件的方法,还执行:
22、当pdf转换请求量很大时,将耗时的pdf转换操作放到后台使用消息队列或任务队列进行异步处理;
23、其中,创建一个或多个消息队列或任务队列来管理pdf转换任务;
24、使用优先级队列来确保重要的或紧急的转换任务能够优先得到处理;
25、实时监控服务器的负载情况和队列的长度,以便及时发现潜在的过载问题;
26、若发现服务器负载过高或队列长度过长,增加服务器资源或使用负载均衡技术将请求分发到多台服务器上。
27、由此可见,相比于现有技术,本发明具有以下有益效果:
28、1、实时性:由于转换过程发生在服务器端,用户可以实时提交网页url并立即获取对应的pdf文件,无需等待长时间的处理或渲染;
29、2、兼容性:使用chrome浏览器进行渲染和转换可以确保网页内容在转换为pdf时能够保持较高的兼容性,因为chrome支持多种网页标准和格式;
30、3、无厘头模式(headless mode):通过设置chrome的无厘头模式,可以在没有图形界面的情况下运行浏览器,这大大减少了系统资源的消耗,提高了转换效率;
31、4、灵活性:通过配置浏览器参数,可以针对pdf生成进行特定的设置,如页眉页脚、页边距、纸张大小等,从而生成符合需求的pdf文件;
32、5、高保真:由于直接使用chrome浏览器进行渲染,所以转换后的pdf文件能够较好地保留原始网页的样式、布局和交互性元素,保证转换的高保真度;
33、6、自动化:整个转换过程可以在服务器端自动完成,无需用户手动操作,大大提高了工作效率;
34、7、可扩展性:该方法可以很容易地集成到现有的app或系统中,通过提供api接口,其他应用或服务也可以方便地调用该转换功能;
35、8、安全性:通过app服务端控制pdf转换过程,可以更好地保护用户数据的安全性,避免在客户端进行敏感操作可能带来的风险;
36、9、跨平台性:由于chrome浏览器支持多种操作系统,因此该方法可以在不同的平台上实现网页到pdf的转换,具有良好的跨平台性;
37、10、可定制性:可以根据具体需求定制pdf文件的输出格式、分辨率、颜色模式等参数,以满足不同场景下的使用需求。
38、11、提升网页渲染速度:网页中样式可复用、无需写行内样式,不会造成代码臃肿,轻量简洁提升网页渲染速度大大提升用户体验。
39、12、在转换pdf时对cpu无要求,移动互联网下前端工程师无需写两份网页来适配pc和手机端样式。
40、下面结合附图和具体实施方式对本发明作进一步详细说明。
本文地址:https://www.jishuxx.com/zhuanli/20240929/313046.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表