一种联邦推荐中集成改进伪标签技术和梯度对齐自适应正则化的数据再平衡方法
- 国知局
- 2024-10-09 15:16:18
本发明涉及大数据处理,尤其是涉及一种联邦推荐中集成改进伪标签技术和梯度对齐自适应正则化的数据再平衡方法。
背景技术:
1、推荐系统利用计算机科学、统计学、机器学习等技术来帮助用户从海量数据中发现有价值的信息或服务,其适用于包括电子商务、社交网络、在线广告平台等各种领域,具有提高企业销售量、用户体验和市场份额等方面的价值。
2、然而,推荐系统要求用户将数据上传至服务器,这引起了人们对于潜在的隐私泄露的担忧。许多国家都颁布了相关法律法规来增强隐私保护(如:欧盟的《general dataprotection regulation》,中国的《中华人民共和国个人信息保护法》)。联邦推荐作为一种能够保护用户隐私的推荐系统范式,受到了来自工业界和学术界的广泛关注。
3、与传统推荐不同,联邦推荐是一种分布式的过程。它允许用户的个人数据留在本地(不上传至服务器)进行模型训练。现有的联邦推荐研究主要关注增强模型的效率和效果:关于效率,一些研究旨在提高模型的收敛速度来减少通信成本,因为在联邦学习中通信成本要比计算成本更珍贵。关于效果,主要是利用不同的加密方法来进一步保护用户隐私,如同态加密、差分隐私、本地差分隐私。
4、尽管现有的联邦推荐研究在效率和效果上取得了显著的成果,但是这些研究仍然受到数据分布的制约,即部分客户端拥有过多数据,另一部分客户端拥有过少的数据,这种数据不平衡损害联邦推荐的性能。
技术实现思路
1、有鉴于此,本发明是一种对联邦推荐系统进行数据重平衡的框架,这种框架适用于任何联邦推荐系统。同时为了增强数据重平衡过程中联邦推荐系统的鲁棒性,提出了一种梯度对齐自适应正则化。
2、以fedavg为联邦聚合算法,本发明的技术方案如下:
3、一种联邦推荐中集成改进伪标签技术和梯度对齐自适应正则化的数据再平衡方法,包括如下步骤:
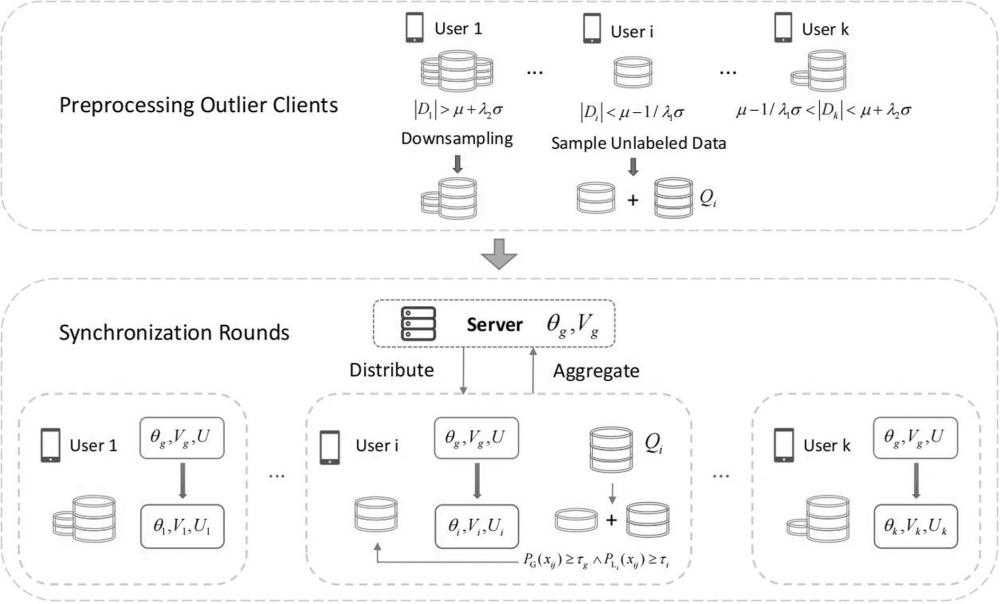
4、步骤s1:对于一个联邦推荐系统,服务器首先预处理离群客户端;根据各个客户端上的数据量计算各个客户端的z分数,用以识别离群客户端,即数据过多的客户端和数据过少的客户端;并对离群客户端进行预处理,包括对数据过多的客户端进行下采样,以及对数据过少的客户端随机采样无标签样本用于后续的数据增强;
5、步骤s2:初始化每个客户端上的平均预测概率,这用于后续计算阈值及正则化权重;其中,阈值用于为数据过少的客户端筛选可靠的伪标签样本以实现数据增强,正则化权重用于各个客户端上计算损失函数时作为正则项的权重;同时计算全局模型对所有客户端上样本的平均梯度;
6、步骤s3:由服务器分发全局模型(包括物品表示和模型参数)至各个客户端,由此各个客户端得到了自己的本地模型(包括物品表示、模型参数以及私有的用户表示),至此进入迭代轮;
7、步骤s4:每个客户端都利用自己的本地数据来计算损失函数,损失函数包括交叉熵损失函数和梯度对齐自适应正则化,然后以梯度下降的方式更新本地模型;并且在这个过程中记录各个本地模型对本地数据的平均预测概率;
8、步骤s5:计算物品表示和模型参数在更新前后的参数值之差,用于后续的全局模型更新;
9、步骤s6:对于数据量过少的客户端,利用s2中提到的阈值,采用改进伪标签技术执行数据增强;对于其他客户端,不做任何处理;
10、步骤s7:各个客户端将物品表示和模型参数在更新前后的参数值之差,以及平均预测概率上传至服务器;
11、步骤s8:将各个客户端的平均预测概率更新为s4中计算得到的平均预测概率,这将用于在下一个迭代轮中计算阈值和正则化权重;
12、步骤s9:利用各个客户端上传的物品表示和模型参数在更新前后的参数值之差,服务器全局模型更新全局物品表示和模型参数;
13、步骤s10:重复步骤s3~s9直至模型收敛。
14、所述步骤s1中的联邦推荐系统由1个服务器和若干个客户端构成,其中每个用户充当一个客户端,服务提供商则提供服务器;服务器根据第i个客户端上的数据量计算其z分数的公式如下:
15、zi=(|di|-μ)/σ (1)
16、其中,|di|表示第i个客户端上本地数据集的样本数量,μ和σ分别表示参与联邦训练的所有客户端的平均数据量和标准差;
17、若zi<-1/λ1,则该客户端被视为数据过少的客户端,将被随机采样q个无标签样本得到qi={xi1,…,xiq},qi被用于后续的数据增强。其中q为超参数,其取值一般为μ~5μ;若zi>λ2,则该客户端被视为数据过多的客户端,将被随机下采样若干个样本直到|di|=μ+λ2σ。λ1和λ2均为超参数且取值范围一般为1~3。
18、所述步骤s2中计算全局模型对所有客户端上样本的平均梯度公式如下:
19、
20、上述公式(2)中,d表示参与训练的所有客户端的集合,|d|表示参与训练的客户端的数量。
21、所述步骤s3中服务器将全局模型分发给客户端是因为:联邦推荐为了保护用户隐私,不要求用户将其个人数据上传至服务器,取而代之的是服务器将模型发送给用户,由用户利用其本地数据来执行本地更新,后续将更新得到的本地模型发送给服务器以更新全局模型。
22、所述的用户利用其本地数据来执行本地更新,更新项为用户向量表示、物品表示和模型参数,具体更新公式如下:
23、
24、其中,的计算公式如下:
25、
26、上述公式(3)中,表示第t轮时第i个客户端上训练得到的用户向量表示,表示第t-1轮时第i个用户的向量表示,α表示学习率,表示当前客户端上根据本地数据集上计算得到的交叉熵损失函数对用户表示u的梯度;
27、上述公式(4)中,vit表示第t轮时第i个客户端上训练得到的物品表示,
28、表示当前客户端的本地数据集上计算得到的交叉熵损失函数对用户表示v的梯度;
29、上述公式(5)中,表示第t轮时第i个客户端上训练得到的模型参数,表示当前客户端的本地数据集上计算得到的损失函数对模型参数θ的梯度;
30、上述公式(6)中,ui表示第i个用户,vj表示第j个物品,rij∈{0,1}表示第i个用户对第j个物品是否发生交互(1表示发生交互,0表示没有)。di表示第i个客户端上的本地数据集,表示模型预测用户i与物品j发生交互的概率。
31、所述步骤s4中,在第i个客户端上计算损失函数的公式如下:
32、
33、上述公式(7)中,γi(a)表示第i个客户端上的正则化权重,该权重是一个动态权重,使得不同的本地模型能够不同程度地受到正则化的影响;某些本地模型对本地数据的预测自信度较高,即模型性能较好,此时降低其正则化权重,鼓励模型更多地从自己的本地数据中学习;某些本地模型对本地数据的预测自信度低,即模型的性能较差,此时增加其正则化权重,鼓励模型更多地接受全局模型的指导;该权重的计算表达式如下:
34、
35、上述公式(8)中,a是一个超参数,取值一般为0.001~0.1,τi表示第i个客户端上的本地阈值,τg表示全局阈值。τg通过以下公式计算得到:
36、
37、上述公式(9)中,pi即为第i个客户端上所记录的本地模型对本地数据的平均预测概率,k表示客户端的数量。而τi由以下公式计算得到:
38、m~beta(β,β) (10)
39、
40、上述公式(10)中,m为从参数为β的贝塔分布中采样得到的实数;β是一个超参数,一般取值为0.1~2。
41、这种梯度对齐自适应正则化鼓励本地模型捕捉跨客户端的一般模式,防止本地模型过多地偏离全局模型,有利于提高全局模型在数据重平衡过程中的鲁棒性,从而更好地应对变化的数据分布。另一方面,为不同的客户端选取不同的正则化权重,可以使性能较弱的本地模型更多地接受全局模型的指导,使性能较强的本地模型更多地从本地数据中学习。
42、所述步骤s5中计算物品表示和模型参数在更新前后的参数值之差,其公式分别如下:
43、△vi=vit-vit-1 (13)
44、
45、所述步骤s6用以数据增强的改进伪标签技术,是一种双模型评估机制;不同于常规伪标签技术中仅使用单个模型预测无标签样本,双模型评估机制利用当前客户端上的本地模型和全局模型来共同预测无标签样本;其中,第i个客户端上的本地模型对当前客户端上第j个无标签样本xij的预测值为第i个客户端上的全局模型对当前客户端上第j个无标签样本xij的预测值为pg(xij);仅当这两个预测值都满足阈值时,无标签样本xij被赋予1的伪标签,采用改进伪标签技术执行数据增强的计算公式如下:
46、
47、上述公式(15)表示,对于xij∈qi,如果全局模型对该样本的预测值pg(xij)≥τg且当前客户端上的本地模型对该样本的预测值则该样本被赋予1的伪标签。联邦推荐系统每个客户端上存在全局模型和本地模型,其中在各个客户端上的全局模型是相同的,而本地模型各不相同。单个客户端上的全局模型和本地模型构成了双模型评估机制,有利于获得更可靠的伪标签样本。
48、全局阈值τg和本地阈值τi是由公式(9)~(12)得到的。在获得τi时,通过随机采样混合比例m,为阈值的选取引入了随机性,可以增强模型应对不确定情况的能力。另一方面,为不同的客户端选择不同的本地阈值,可以防止某些本地模型过于自信而引入大量伪标签样本,也可以防止某些本地模型过于保守从而无法产生伪标签样本。
49、所述步骤s9中全局模型的更新项包括物品向量表示和模型参数,由于联邦推荐保护用户隐私而不要求用户将用户表示上传至服务器。其中,物品向量表示的更新公式如下:
50、
51、上述公式(16)中表示第t轮次的全局物品表示;
52、所述模型参数的更新公式如下:
53、
54、上述公式(17)中表示第t轮次的模型参数,这里的模型可以是任意基于矩阵分解的推荐模型如neumf、svd++等。
55、重复迭代轮步骤s3~s9直至模型收敛,得到训练完成的联邦推荐模型。
56、本发明在本地模型更新时采用了一种梯度对齐自适应正则化,旨在提高联邦推荐系统的鲁棒性,适用于任何联邦推荐模型以应对联邦推荐系统中的数据不平衡。
本文地址:https://www.jishuxx.com/zhuanli/20241009/308161.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。