聚焦关键区域的智慧城市监控视频编码方法与流程
- 国知局
- 2024-10-15 09:29:19
本技术涉及一种智慧城市监控视频编码方法,特别涉及一种聚焦关键区域的智慧城市监控视频编码方法,属于视频监控编码。
背景技术:
1、随着信息技术不断发展,城市信息化水平不断提升,智慧城市建设稳步展开。计算机、网络、图像处理、传输技术飞速进步,视频技术也得到明显的发展和提升,为城市公共安全系统的构建、公共秩序的维持提供了很大的帮助,视频监控技术还可以应用在城市应急、智能交通、安防监管等领域,正在全面迈向数字化、网络化和智能化的时代。
2、城市监控视频网络和智慧城市建设的深入而不断扩大。监控网络的快速发展也带来一些严峻挑战,限制了其在实际生活中的应用。其中最紧迫的问题之一就是监控数据的存储,监控视频的分辨率越来越高,导致产生的数据总量也随之不断增加。长时间储存这些数据会花费大量的人力、物力以及财力,是不切实际的。针对监控系统高清晰度和存储设备高成本之间的矛盾,现有技术是采用更高的压缩比进行视频压缩以节约存储成本,但这导致了监控视频的质量降低,严重影响了对象识别和跟踪的准确度。
3、现有的视频压缩分为有损压缩和无损压缩两类。对监控视频进行有损压缩会丢失大量城市监控线索,而无损压缩虽保全了视频信息,但由于数据量较大,不能满足存储和传输的需求。因此,考虑把监控视频帧划分为包含监控关注对象的roi和不包含监控关注对象的非roi,然后结合有损压缩与无损压缩,对于非感兴趣区域使用较高压缩比的有损压缩,对于感兴趣区域使用较低压缩比的有损压缩甚至是无损压缩,这样既能满足存储与传输的需求也可保证监控关注对象区域的质量。
4、现有技术基于感兴趣区域的视频编码包含两个步骤:1)通过自下而上或自上而下的感知模型提取roi;2)调整roi与非roi比特分配以提升视频主观质量。而在案件调查中,往往更关注具有城市监控价值的目标,如行人、人脸、车辆和车牌等信息,这些目标并不一定是人眼最关注的目标。因此,将现有的roi编码直接应用到监控视频编码中很难达到期望的性能。
5、现有技术的关键区域城市监控视频编码方法需要解决的问题和本技术关键技术难点包括:
6、(1)城市视频监控数据的存储存在较大的技术难点,监控视频的分辨率越来越高,导致产生的数据总量也随之不断增加,长时间储存这些数据会花费大量的人力、物力及财力,是不切实际的。针对监控系统高清晰度和存储设备高成本之间的矛盾,现有技术是采用更高的压缩比进行视频压缩以节约存储成本,但这导致了监控视频的质量降低,严重影响了对象识别和跟踪的准确度。现有技术对监控视频进行有损压缩会丢失大量城市监控线索,而无损压缩虽保全了视频信息,但由于数据量较大,不能满足存储和传输的需求。现有技术未考虑对于非感兴趣区域使用较高压缩比的有损压缩,对于感兴趣区域使用较低压缩比的有损压缩甚至是无损压缩的方法,造成既不能满足存储与传输的需求也无法保证监控关注对象区域的质量。
7、(2)案件调查中往往更关注具有城市监控价值的目标,如行人、人脸、车辆和车牌等信息,这些目标并不一定是人眼最关注的目标,现有技术将roi编码直接应用到监控视频编码中很难达到期望的性能。监控视频与其它多媒体视频的不同在于监控视频的拍摄不是为了欣赏,而是为突发事件和公共案件的分析提供更有价值的线索。现有技术缺少基于该特点对监控视频分析的应用,不能在降低监控数据的存储成本的同时保证原有的线索不丢失,无法满足事件调查的需求,公共事件中,与背景信息相比更关注包含监控关注对象(行人和车辆)或面部信息的区域,而视频分析最重要的先决条件之一就是这些感兴趣区域(roi)的相对高度保真,现有技术缺少面向监控视频的分析,无法根据在视频分析中的感兴趣区域来调整编码的码率分配以解决数据存储问题,无法满足智慧城市监控视频编码大数据快响应的需求。
8、(3)现有技术感兴趣区域的提取主要是基于人类视觉注意机制,不适合面向监控视频分析,现有技术缺少根据监控关注对象不同的空域信息提取出四种监控关注对象(行人、人脸、车辆、车牌)的空域显著图,缺少通过对空域显著图的纠正调合后生成完整的包含所有监控关注对象的空域显著图,不能构建时域运动信息生成的时域显著图,无法通过对空-时显著图的调合,不能很好的区分静止的监控关注对象与动态的监控关注对象,无法将生成的面向分析的显著图融入hevc的编码框架中,无法根据显著图来调整hevc中的码率控制,无法建立加权码率控制方案以强调包含监控关注对象的区域,造成监控视频编码的质量差,无法满足视频分析的需求,同时比特率消耗大,不适合用于存储大型监控数据。
技术实现思路
1、为提升监控关注对象区域的编码质量,本技术提出一种面向分析的监控视频编码技术,以维持监控视频的分析价值。在本技术提出的方法中,将显著性视为对象检测和识别的重要特征,以代替根据人类视觉感知系统所产生的显著图。经过这种修改以后,调查中的所有监控关注对象都将被赋予更高的显著值,而不仅仅是在图像中产生一个或两个显著区域。然后,通过时域运动信息来强调移动的对象,即移动的监控关注对象将获得更高的显著值。最后,基于显著性的码率控制算法被嵌入在hevc中,在固定的比特率下维持编码视频中的监控关注对象的质量。通过两个度量分析性能的指标(特征相似性和对象检测精度)进行实验。实验结果表明,在实现与hevc相同的特征相似性和对象检测精度的情况下,本技术的方法分别可以节省20%和40%的比特率,用于存储智慧城市大型监控数据。
2、为实现以上技术效果,本技术所采用的技术方案以下:
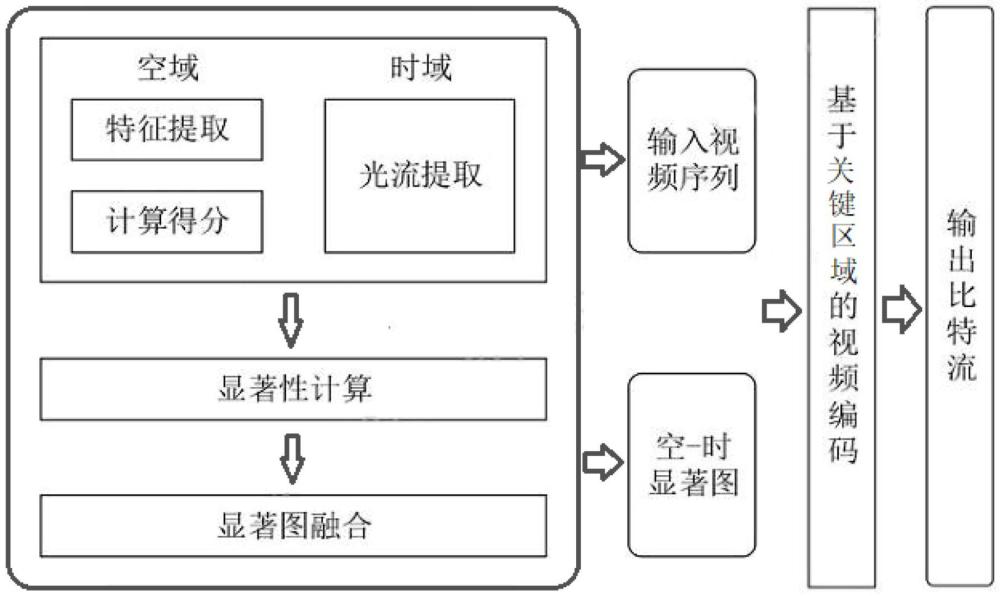
3、聚焦关键区域的智慧城市监控视频编码方法,首先构建空间域中基于特征的显著性检测方法,以打分法评估行人、人脸、车辆和车牌四种监控关注对象的发生概率,基于响应得分生成四种监控关注对象的空域显著图,并通过调合生成最终的空域显著图,然后通过变分运动测量来计算时域显著性,获取时域显著图,在分别获取空域、时域显著图之后,通过加权调合的方法产生最终的空-时显著图,随后,采用基于roi的加权r-λ策略对编码的码率进行控制,采用基于显著性的权重来调整roi中量化参数qp的计算,给具有较高显著性的监控关注对象区域分配更多的比特,提高监控视频分析性能;
4、1)关键区域空域显著性检测:根据四种监控关注对象不同的空域信息进行检测,包括基于分歧特征的人脸显著性检测模型、车牌显著性检测模型,然后对得分图进行处理最终生成空域显著图;
5、2)关键区域时域显著性检测:构建基于变分运动测量提取运动信息的模型,通过所获得的运动信息生成时域显著图;
6、3)面向视频分析的空-时显著图调合:首先纠正空域显著图异常值,然后调合空域显著图,接着采用面向视频分析的调合方法进行关键区域空-时显著图调合;
7、4)关键区域显著性的码率控制模型:采用新型的r-λ模型以及在此基础上改进的面向关键区域视频分析的码率控制模型。
8、优选地,关键区域空域显著性检测:通过改善监控关注对象的显著性以支持在计算机上更快处理分析监控视频中的特定人和车辆,在空域中,用监控关注对象出现的概率度量其显著性,出现概率越高的显著值越高,本技术构建一种评分方法,根据行人、车辆、人脸和车牌四种对象不同的空域信息,通过检测监控关注对象并返回得分图,然后对得分图进行处理生成空域显著图,计算监控关注对象在每幅图像中出现的可能性。
9、优选地,基于分歧特征的人脸显著性检测模型:将整个人脸看作一个显著区域,采用一种新型分歧特征分歧进行检测,分歧特征定义分歧函数f(x,y),其中x和y表示任意两个像素的像素值,当x=y=0时,x和y两点之间不存在灰度差,f(o,0)=0,分歧特征的计算式如下:
10、
11、分歧特征通过一个深层二叉树来学习最优的特征子集和这些子集的结合,以便复杂的面部流形通过学习的规则进行分割,该深层二叉树采用一种新的树内节点分裂方式来构建,新的分裂方式考虑x的一阶、二阶信息:
12、(ax2+bx+c)<t 式2
13、其中a,b,c是常量,x是特征值,t是分裂临界值,函数检测x是否处于[θ1,θ2]中,θ1和θ2是两个已知的临界值;
14、在计算人脸的显著性时,采用分歧特征并通过该模型中的深层二叉树进行学习,通过单个级联分类器检测人脸,人脸的响应得分由级联adaboost分类器产生:
15、scoref=g(x)=g(f(x,y)) 式3
16、在得到检测人脸的得分图scoref之后,对其进行和行人与车辆一样的归一化处理来获取最终的人脸显著图。
17、优选地,车牌显著性检测模型:采用开放源代码easypr3检测车牌,包括车牌定位检测与字符识别,车牌检测platedetect包含车牌的定位,svm的训练,以及车牌的判断三个过程,首先对输入图像是否包含车牌进行分析,定位一些可能是车牌的区域,然后截取这些可能是车牌的图块,通过训练好的svm模型来判别截取的图块是否为真正的车牌,系统中字符识别charsrecognise部分则包含字符的分割、神经网络ann的训练、字符识别三个过程,对在车牌检测步骤中截取的车牌图像进行灰度化处理,然后进行光学字符识别以获取车牌中各个字符的分割图块,在获取车牌字符图块后,进行分类后送入人工神经网络中的多层感知机模型进行训练;
18、把监控视频中车牌出现的可能性视为一个二值问题,即车牌是否存在:
19、
20、获取检测车牌的响应得分之后进行归一化处理。
21、优选地,关键区域时域显著性检测:构建运动信息以改进在空间域中检测到的静态显著性,通过构建变分运动测量来获取监控视频每帧中各像素点的运动矢量信息以确定显著目标,通过描述符匹配解决大位移运动的问题,模型的能量泛函表达为式5:
22、e(w)=ecolor(w)+γegradient(w)+αesmooth(w)+βematch(w,w1)+edesc(w1) 式5
23、其中γ、α、β是通过大量视频分析或真实数据估算得到的调节参数,式5中ecolor(w)是灰度或颜色守恒假设的数据项,计算式如下:
24、ecolor(w)=∫ωψ(|i2(x+w(x))-i1(x)|2)dx 式6
25、式6中w为像素点x的运动矢量,i1和i2为图像序列中的前后两帧,ψ是非平方惩罚函数,
26、模型的能量泛函中egradient(w)是梯度守恒假设的数据项,计算表达式为:
27、
28、能量泛函中esmooth(w)是平滑项,表达式为式8:
29、
30、泛函中的ematch(w,w1)是将描述符匹配点整合到变分法的增加项,其中w1表示在像素点x通过描述符匹配获得的对应的矢量:
31、ematch(w,w1)=∫δ(x)ρ(x)ψ(|w(x)-w1(x)|2)dx 式9
32、当在前一帧中存在可用的描述符时ematch中的δ(x)取值为1,否则为0,泛函中的edese(w1)是在ematch假定的描述符已匹配时的区域匹配项,表达式如式10:
33、edesc(w1)=∫δ(x)|f2(x+w1(x))-f1(x)|2dx 式10
34、在edesc(w1)中的f1和f2分别为前后两帧的特征矢量,ρ(x)是匹配数,其计算表达式为:
35、
36、其中d1和d2分别表示最佳匹配距离和第二佳匹配距离;
37、本技术在检测监控视频中监控关注对象显著性时,首先通过变分运动测量模型来获取每帧中像素点的运动信息,然后利用像素点的运动矢量来计算该点的显著性,利用运动矢量的长度来计算时域中图像的显著性,分别用ux和uy表示运动矢量在水平与垂直方向的分量,在时域中点(x,y)的显著性表示为:
38、
39、对监控关注对象检测的时域显著图即在获得st后归一化为范围是0到255的灰度图。
40、优选地,面向视频分析的空-时显著图调合:完善监控关注对象的空域显著图以纠正异常响应值,然后调合四种监控关注对象的空域显著图,并根据其在事件中所携带信息的价值将输入帧划分成三个粗略的等级:级别1为包含车牌和人脸区域的输入帧,级别2为包含行人和车辆区域的输入帧,级别3为包含除去这四种监控关注对象以外区域的输入帧,在调合空域显著图之后,构建时域运动信息以补充监控关注对象的显著性,并根据监控关注对象在案件侦查中的吸引力将输入帧精细划分为四个区域:包含运动的监控关注对象的区域、包含静态的监控关注对象的区域、包含运动的非监控关注对象的区域、包含静态的非监控关注对象的区域。
41、优选地,空域显著图的纠正:利用行人和车辆的空域显著图纠正人脸及车牌的空域显著图以提高其准确性;
42、在纠正人脸异常响应值之前,将设定行人和人脸显著临界值δp和δf来去除背景及其它物体带来的噪声影响,在纠正人脸异常值时,当人脸区域的中心在行人的区域内时,将人脸与行人进行匹配,在获取所有的行人-人脸匹配对后,将人脸显著图进行修改:
43、s′f=sf·i 式13
44、
45、上式中sf’为修正后的空域人脸显著图,i为人脸与行人匹配区域的二进制掩码,rpair表示人脸-行人匹配对,当像素点属于人脸-行人匹配区域时i取值为1,否则为0。
46、优选地,空域显著图的调合:基于空域信息获得四种监控关注对象的显著图:人脸显著图sf、行人显著图sp、车辆显著图sv、车牌显著图s1,在纠正异常的响应值后,四种显著图表现监控关注对象出现可能性大小,本技术基于四种显著图存在相关性和互补性,通过相互调合以提升通过单个特征检测的显著性,并且通过调合获得同时包含四种监控关注对象的显著图;
47、在调合时首先调合人脸和行人的显著图生成行人-人脸显著图sp,f,并调合车牌和车辆的显著图生成车辆-车牌显著图sv,1,调合采用线性加权的方法:
48、sp,f=αp,f·s′f+(1-αp,f)·sp 式14
49、sv,l=αv,l·s′l+(1-αv,l)·sv 式15
50、式14与式15中αp,f和αv,l分别是行人-人脸显著图调合和车辆-车牌显著图调合的权重系数,取值范围是[0,1],人脸和车牌包含的信息量多于行人和车辆,且这些信息是关键线索,并且人脸和车牌作为行人和车辆区域的一部分,其显著性对行人和车辆区域显著性的影响积极,调合时赋予人脸和车牌区域更高的权重,αp,f和αv,l取值近似等于1,通过加强人脸和车牌在s′f和s′l中的显著性使其大于行人和车辆显著图中的最大值,并在s′f和sp中提升人脸区域的显著性,在s′l和sv中提升车牌区域的显著性,获得的调合图中人脸和车牌信息更显著;
51、在分别获取行人-人脸显著图sp,f及车辆-车牌显著图sv,1之后,将这个两种显著图进行调合以获取最终的显著图ss,基于监控关注对象在一幅图中的某个区域不可能同时为行人/人脸和车辆/车牌,体现显著图基于监控关注对象出现概率所生成,调合采用最大值法:
52、ss=max(sp,f(x,y),sv,l(x,y)) 式16
53、最终的显著图ss中像素点(x,y)的显著性将选取sp,f与sv,1在该点显著值的较大值。
54、优选地,空-时显著图调合:将时域显著图与空域显著图进行调合使其相互补充以获取更为精准的空-时显著图ss,t;
55、基于静止监控摄像机,对空-时显著图的调合采用线性加权的方法来获取最终的显著图以区分静态对象与运动对象:
56、ss,t=αs,t·ss+(1-αs,t)·st 式17
57、式中ss为空域显著图,st为时域显著图,αs,t为调合空-时显著图的加权系数,当αs,t较小时,空-时显著图的显著性源于时域显著图,当αs,t=0.5时,空域显著图与时域显著图呈现平衡状态,在调合时给予时域显著图更高的权重,确保在最终的空-时显著图中运动的监控关注对象显著于静态监控关注对象。
58、优选地,关键区域显著性的码率控制模型:通过检测监控关注对象的显著性来提取用于视频分析的关键区域,建立基于r-λ的码率控制模型来提升感兴趣区域的重构质量;
59、本技术提出一种建立码率与拉格朗日乘子λ的关系,并r-λ模型的基础上进行改进以适用于视频分析的码率控制模型;
60、码率控制分两个步骤:对每级编码单元进行比特分配以及设法达到预先设定的目标比特;
61、比特分配包含三个层次,图像组gop级,图像级以及基本编码单元级,每帧的比特平均为:
62、
63、其中rtar为目标比特,f为帧率,根据预先的信息或缓冲区状态对平均比特进行调整,在理想情况下,图像组gop级的实际编码比特正好等于预先分配好的比特,gop的分配比特targetgop等于gop中帧数ngop与每帧平均比特rpicavg的乘积,即:
64、tgop=ngop×rpicavg 式19
65、在图像级中,则根据每帧的权重来分配比特:
66、
67、即根据每帧的权重给剩余的帧分配该gop中剩余的比特,而在基本单元级中,根据基本单元的权重将每帧中剩余的比特分给剩余的基本单元:
68、
69、其中式21的bith是预先估算的图像头信息的比特,通过之前编码的属于同一级图像的头信息的比特均值估算得到,lcu的权重由mad确定,mad根据之前编码的属于同级图像中的同一位置的基本单元的预测误差得到,每个lcu的mad计算式22如下:
70、
71、其中n为当前lcu中像素的数目,porg为原始像素值,ppred是预测像素值,每个lcu的权重计算为:
72、
73、对r-λ模型中最大编码单元的比特分配进行调整,在监控关注对象区域使用较小的qp保证重构质量,在r-λ模型中最大编码单元的比特权重由mad计算得到,通过对比较敏感目标的显著性与周围区域的显著性来改进mad,进而提升敏感对象区域编码比特的权重分配。
74、与现有技术相比,本技术的创新点和优势在于:
75、(1)为提升监控关注对象区域的编码质量,本技术提出一种面向分析的监控视频编码技术,以维持监控视频的分析价值。在本技术提出的方法中,将显著性视为对象检测和识别的重要特征,以代替根据人类视觉感知系统所产生的显著图。经过这种修改以后,调查中的所有监控关注对象都将被赋予更高的显著值,而不仅仅是在图像中产生一个或两个显著区域。然后,通过时域运动信息来强调移动的对象,即移动的监控关注对象将获得更高的显著值。最后,基于显著性的码率控制算法被嵌入在hevc中,在固定的比特率下维持编码视频中的监控关注对象的质量。通过两个度量分析性能的指标(特征相似性和对象检测精度)进行实验。实验结果表明,在实现与hevc相同的特征相似性和对象检测精度的情况下,本技术的方法分别可以节省20%和40%的比特率,用于存储智慧城市大型监控数据。
76、(2)监控视频与其它多媒体视频的不同在于监控视频的拍摄不是为了欣赏,而是为突发事件和公共案件的分析提供更有价值的线索。基于这个特点,本技术新的监控视频编码方法以对监控视频的分析为目的,在降低监控数据的存储成本的同时保证原有的线索不丢失,以满足事件调查的需求,公共事件中,与背景信息相比往往更关注包含监控关注对象(行人和车辆)或面部信息的区域。而视频分析最重要的先决条件之一就是这些感兴趣区域(roi)的相对高度保真。本技术方法面向监控视频的分析,根据在视频分析中的感兴趣区域来调整编码的码率分配以解决数据存储问题,存储成本的显著降低,有效解决了监控数据快速膨胀与存储成本之间的矛盾,高效压缩了数据量同时不降低监控视频的分析价值,是当前更有效的针对监控视频的压缩编码方法。
77、(3)由于本技术方法面向监控视频分析,所以本技术提出的方法中感兴趣区域的提取不再是基于人类视觉注意机制,而是基于案件分析的显著特征。首先根据四种监控关注对象不同的空域信息提取出四种监控关注对象(行人、人脸、车辆、车牌)的空域显著图,然后再通过对空域显著图的纠正调合后生成完整的包含所有监控关注对象的空域显著图,再构建时域运动信息生成的时域显著图,通过对空-时显著图的调合,来更好的区分静止的监控关注对象与动态的监控关注对象,最后将生成的面向分析的显著图融入hevc的编码框架中,根据显著图来调整hevc中的码率控制,建立加权码率控制方案以强调包含监控关注对象的区域。通过对比实验,本技术方法在保证与hevc编码相同的分析性能的前提下,节约比特率,同时监控视频编码的质量高,充分满足视频分析的需求。
本文地址:https://www.jishuxx.com/zhuanli/20241015/314303.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表