一种多源异构实验数据融合与管理方法及系统
- 国知局
- 2024-10-21 14:29:55
本发明属于材料实验数据库以及材料基因工程领域,具体涉及一种多源异构实验数据融合与管理方法及系统。
背景技术:
1、材料基因工程是一种将基因工程技术应用于材料科学领域的前沿技术,旨在结合基因组学、计算机模拟和实验验证的方法,加速新材料的发现、设计和优化过程。材料基因工程需要大量的材料基因组信息、功能和性能信息作为研究和分析的基础。这些数据通常来源于公开的材料数据库或大量的实验积累,其中后者是研究特定材料功能和性能最重要的手段。然而,对材料完整功能和性能指标的获取需要经过多台试验设备进行大量实验才能完成,而这些设备由于其物理位置、功能定位以及品牌厂商的差异,导致了实验结果分布零散、格式不一。这即增加了实验的管理成本,也增加了数据的使用成本。因此,构建能够融合多设备、多源异构材料数据的统一材料实验管理技术是十分必要的。1.分布零散的问题:新材料的研发过程需要大量的试验数据作为支撑。而传统的试验设备只能针对某一项功能或性能测试,若要获取多个指标,实验就需要在多个设备上进行。由于各设备之间缺乏统一的标准和协调,导致数据过于零散,难以有效的维护和使用。这种分散的数据不仅增加了数据整合的复杂性,还可能造成数据重复采集、冗余存储等问题,从而影响对新材料性能的全面评估和优化设计。2.格式不一的问题:不同试验设备和实验方法产生的实验结果数据格式可能不同,涉及文件类型(如csv、excel、json、xml等)、数据库类型(例如mysql、postgresql等),也存在数据类型等方面的差异。这种不一致性增加了结果解读的难度,同时,不一致的数据格式可能导致数据质量问题,如数据丢失、错误,影响数据分析和决策的准确性。3.属性变化的问题:实验数据的定义不是静态的,而是随着研究的深入和不同设备的使用而变化。这意味着无法预先为每个设备设计固定的输出属性格式(如固定表结构),这种属性变化使数据获取、处理和存储的过程需要额外的时间对设备属性对齐。4.联合分析的问题:数据存储位置和格式的不一致性,使得实验数据之间的业务关联变得困难,进而影响了数据的整合和综合分析。传统需要在不同平台上进行数据检索,然后再进行人工整合,这降低了数据的共享和交流的失效性。5.统一存储的问题:传统将数据全部收集统一存储的方法会导致存储资源的浪费,特别是针对多种设备、多种格式的大量数据。统一存储会占用额外的存储空间,且不同类型的数据可能需要不同的存储结构和处理方式,这也会造成管理上的困难。
2、由于缺乏跨设备、多源异构实验数据的融合管理方法,传统对材料功能和性能的研究需要先使用各类设备如电子材料试验机、液压材料试验机、冲击试验机、拉伸试验机等进行离散的材料实验。每种设备产生的实验结果都会以数字化形式保存,包括csv、excel、json、xml,或mysql、postgresql等数据库中。随后,用户还需要耗费大量的精力对这些数据进行处理,如数据整合、格式转换、统一的检索、融合、分析和可视化。这无疑都影响了数据管理和分析的时效性。
技术实现思路
1、为了解决现有技术中存在的问题,本发明提供一种多源异构实验数据融合与管理方法及系统,涉及材料数据库、材料基因工程等领域。该发明主要采了动态元数据技术、数字孪生技术及数据虚拟集成技术,解决材料基因工程领域实验数据分布零散,结果数据格式不一,数据属性动态变化,跨机器难以统一管理,跨实验无法联合分析等问题。
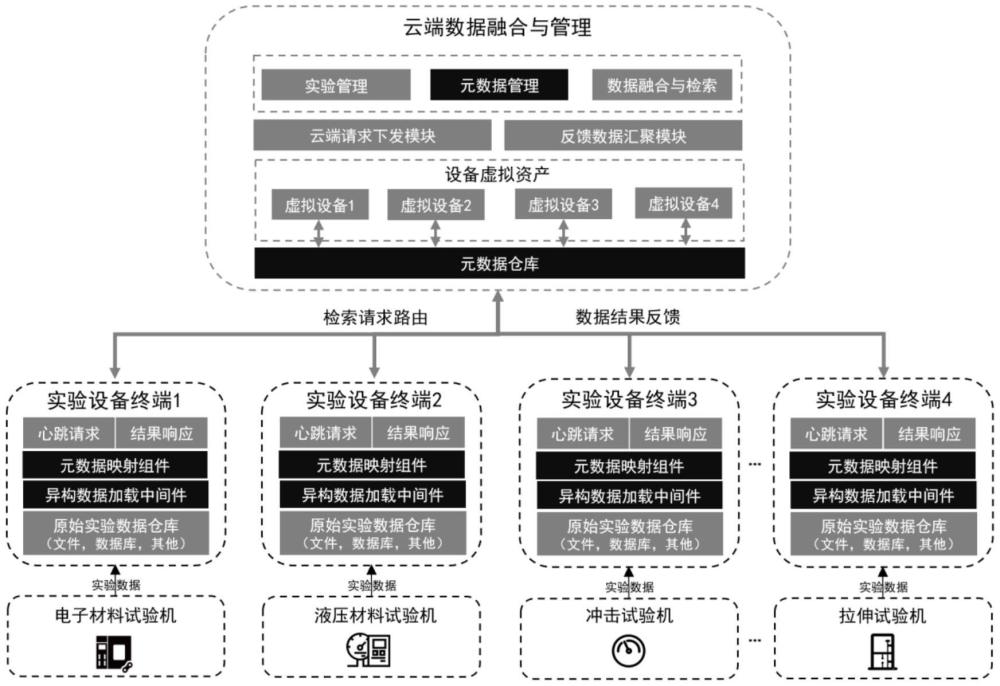
2、为了实现上述目的,本发明采用的技术方案是:一种多源异构实验数据融合与管理系统,包括云端服务系统和设备终端主机,云端服务系统包括实验管理模块、元数据管理模块、数据融合与检索模块、云端请求发送模块、反馈数据汇聚模块;设备终端主机绑定在试验设备上的控制和数据采集的主机,设备终端主机的管理系统中有元数据映射组件和异构数据加载中间件;实验管理模块用于创建新实验,并选择实验所需的虚拟设备;元数据管理模块用于管理元数据仓库,向元数据仓库发送数据更新和调用指令;数据融合与检索模块用于生成融合检索条件,云端请求发送模根据融合检索条件向虚拟设备对应的物理设备中发送数据检索信息;异构数据加载中间件根据配置访问设备原始实验数据仓库,加载最新的实验数据;元数据映射组件根据元数据中定义的属性列表、属性类型和属性单位,对加载的数据进行属性过滤和类型转换反馈;数据汇聚模块检查确认所有参与实验的虚拟设备的反馈数据,将所述反馈数据合并,将不同类型设备数据根据检索请求关联后作为输出数据。
3、进一步的,异构数据加载中间件基于python语言实现,包含13种异构数据:5个文件类csv、excel、txt、xml、json;4个数据库类postgresql、mysql、oracle、sqlserver;2个大数据类hive、hbase;2个外部接口类http、sftp的访问,所述异构数据加载中间件部署于设备终端,初始化时根据终端产生的数据源类型配置加载参数,设备端接收到云端数据加载请求后,读取异构数据的源的配置参数,执行pandas对应类型数据源的加载接口实现原始实验数据的加载,将文本、数据库、大数据类及外部接口类数据统一转化为dataframe类型并输出,所加载的数据行列和数据类型均为实验设备所产生的原始数据。
4、进一步的,元数据映射组件在异构数据加载中间件所加载的统一dataframe类型原始数据结果基础上,首先读取最新元数据定义的属性列表、属性类型和属性单位,再通过pandas框架中的字段过滤和条件筛选接口实现原始数据结果进行归一化处理,同时根据云端请求中的检索条件对数据内容进行过滤,使最终的数据结果满足元数据的定义以及云端的检索条件。
5、进一步的,云端数据融合与检索模块基于虚拟设备向物理设备下发检索请求,请求参数通过http心跳下发到物理设备,通过元数据向物理设备下发检索的数据格式详细定义,物理设备元数据的更新通过http心跳下发,检索请求经过设备端的异构数据加载及元数据映射处理后,设备端将结果以统一的json格式反馈给云端,云端收到设备端反馈的标准化json数据后,再将json数据反向转换为dataframe,将同类型设备数据按行合并,将不同类型数据根据检索条件定义的关联方式进行关联。
6、本发明同事提供一种多源异构实验数据融合与管理方法,包括以下步骤:
7、将每一个物理设备映射为云端的虚拟设备,虚拟设备与物理设备一一绑定;
8、创建新的实验,选择本次实验所需某个虚拟设备或多个虚拟设备,并获取实验参数,为本次实验创建唯一的跟踪id,记录本次实验的设备和参数信息,并将参数信息通过心跳发送至所选虚拟设备对应的物理设备中,参数确认后执行该次实验;
9、加载并展示用户所选虚拟设备所绑定的最新元数据,通过心跳将元数据更新下发到具体的试验设备主机,使虚拟设备绑定的元数据与物理设备本地元数据保持一致;
10、虚拟设备标识出参与本次实验的所有物理设备执行状态,在全部执行结束后,能执行多设备实验结果数据的融合检索;
11、云端系统生成融合检索请求,融合检索请求通过心跳发送到对应的物理设备设备;
12、根据配置访问设备原始实验数据仓库,加载最新的实验数据;根据元数据中定义的属性列表、属性类型和属性单位,进一步对加载的数据进行属性过滤和类型转换,得到格式完全一致的同类型试验设备数据;
13、根据云端融合请求中单设备检索条件对格式完全一致的同类型试验设备数据进行过滤,再反馈至云端系统;
14、收到所有参与实验的虚拟设备的反馈数据后,将同类型设备数据合并,并将不同类型设备数据根据检索请求关联,形成最终的结果数据。
15、进一步的,虚拟设备中包含了物理设备对应的设备id、设备类型,设备实验状态,设备当前实验参数以及设备所绑定的元数据,虚拟设备与物理设备通过心跳建立连接,从上到下更新物理设备实验参数和最新元数据,同时从下到上更新云端虚拟设备的实时操作状态。
16、进一步的,加载并展示用户所选虚拟设备所绑定的最新元数据时,能根据本次实验需求来定制该元数据信息,所述元数据信息包括本次实验需要加载的数据属性、数据类型和取值范围。
17、进一步的,设备主机将更新后元数据存储在本地,用于本地数据加载时的属性映射和类型转换。
18、进一步的,融合检索请求参数中包括接收到的虚拟设备id列表、实验数据的检索条件以及多设备之间的关联方式。
19、进一步的,最终的结果数据通过用户界面输出,在用户界面提供汇聚后的实验结果接口以及每一台虚拟设备对应的物理设备实验结果。
20、与现有技术相比,本发明至少具有以下有益效果:本发明采动态元数据技术、数字孪生技术及数据虚拟集成技术,解决材料基因工程领域实验数据分布零散,结果数据格式不一,数据属性动态变化,跨机器难以统一管理,跨实验无法联合分析等问题;动态元数据技术用于实现数据属性的灵活定义和跨格式的数据加载,为数据融合提供统一的数据格式;本发明可实现一次实验中多试验设备的集中管理及实验过程的集中监控;可实现多设备、多源异构数据的统一访问和联合分析;可实现多设备实验数据的整合和管理,无需占用额外的存储空间。
本文地址:https://www.jishuxx.com/zhuanli/20241021/318381.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表