基于机器学习预测SSD故障的方法、装置、设备及介质
- 国知局
- 2024-10-21 14:50:57
本发明涉及一种基于机器学习预测ssd故障的方法、装置、设备及介质,属于分布式存储。
背景技术:
1、系统可靠性是存储系统重要的方面之一,因此存在大量关于存储设备可靠性的工作。许多较早的工作都集中在硬盘驱动器 (hdd)上,但随着越来越多的数据存储在固态硬盘 (ssd) 上,重点转移到了 ssd 的可靠性上。与hdd相比,基于nand闪存的ssd具有更高的性能和更低的功耗,因此在企业存储系统和大型数据中心中越来越受欢迎。然而,为了降低成本,ssd的存储密度不断增加,这降低了ssd的耐久性和可靠性。大型数据中心通常拥有数十万甚至数百万个ssd。如此大规模的ssd部署对数据中心的可靠性提出了挑战。
2、尽管冗余机制(如复制和 raid)已被用于保护数据免遭丢失,但ssd故障仍然会导致两个主要问题。首先,即使数据中心采用冗余保护方案。在优先考虑一致性的ceph系统设计中,ssd故障依然会大大影响存储系统的性能和在线服务的稳定性。其次,ssd故障时需要故障定位、故障恢复等措施导致额外的维护成本。因此,ssd故障预测作为一种主动容错机制,近年来越来越受到关注。与被动冗余机制相比,它可以提前识别并主动处理潜在的ssd故障,从而提高存储系统的可靠性,降低故障定位和恢复的成本。在大规模存储系统中,监控ssd故障的症状并提前预测故障具有重要意义。
3、hdd 和 ssd现代存储设备的常见监控解决方案是 smart信息,它可以监控和记录驱动器的内部可靠性相关属性。smart信息通常是定期采集的,例如,每个设备每天采集一个或多个 smart信息。smart 属性值在硬盘的自我监控、分析和报告技术监控系统下生成和记录,该系统检测并报告驱动器可靠性的各种指标。但是,可用smart属性数超过50,并非所有磁盘都始终记录所有属性,无法对所有磁盘都进行ssd故障预测。因此,本发明提出了一种基于机器学习预测ssd故障的方法。
技术实现思路
1、为了解决上述问题,本发明提出了一种基于机器学习预测ssd故障的方法、装置、设备及介质,能够更有效地预测ssd故障。
2、本发明为解决其技术问题所采取的技术方案是:
3、第一方面,本发明实施例提供的一种基于机器学习预测ssd故障的方法,包括如下步骤:
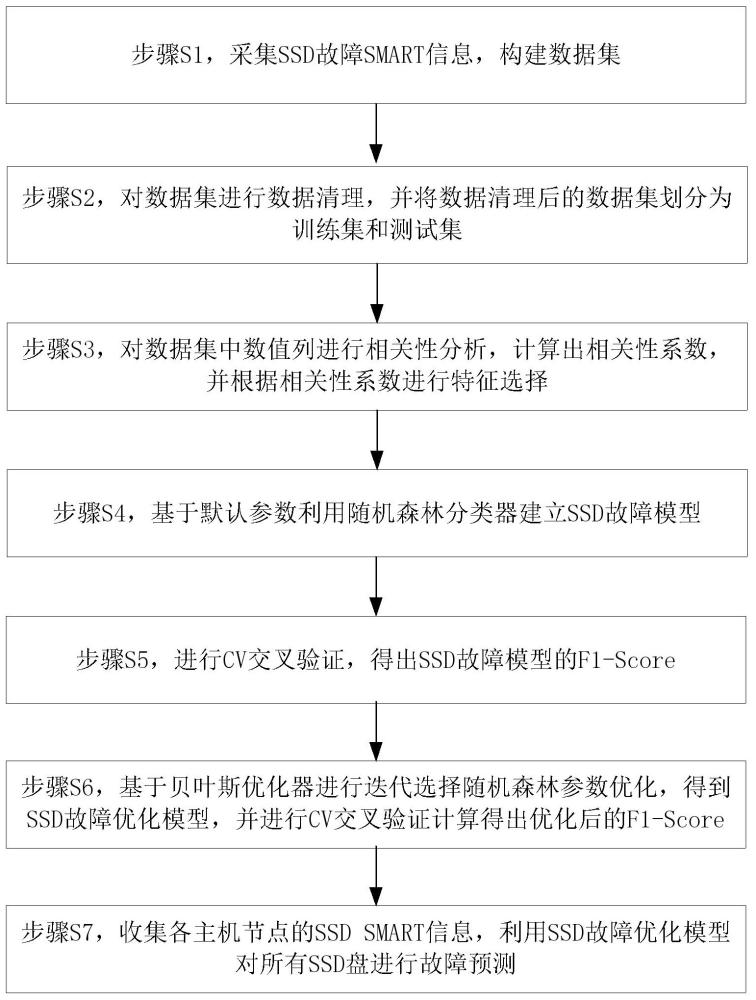
4、步骤s1,采集ssd故障smart信息,构建数据集;
5、步骤s2,对数据集进行数据清理,并将数据清理后的数据集划分为训练集和测试集;
6、步骤s3,对数据集中数值列进行相关性分析,计算出相关性系数,并根据相关性系数进行特征选择;
7、步骤s4,基于默认参数利用随机森林分类器建立ssd故障模型;
8、步骤s5,进行cv交叉验证,得出ssd故障模型的f1-score;
9、步骤s6,基于贝叶斯优化器进行迭代选择随机森林参数优化,得到ssd故障优化模型,并进行cv交叉验证计算得出优化后的f1-score;
10、步骤s7,收集各主机节点的ssd smart信息,利用ssd故障优化模型对所有ssd盘进行故障预测。
11、作为本实施例一种可能的实现方式,所述步骤s1,采集ssd故障smart信息,构建数据集,包括:
12、定义ssd故障smart信息的字段信息;
13、调用smartctl-a/dev/sdx获取smartinfo,解析出对应字段的值,根据生成的信息构建数据集。
14、作为本实施例一种可能的实现方式,所述对数据集进行数据清理,包括:
15、在jupyter中通过pandas加载csv;
16、加载返回的对象调用describe进行数据描述;
17、调用dropna对缺省值进行过滤删除。
18、作为本实施例一种可能的实现方式,所述步骤s3,对数据集中数值列进行相关性分析,计算出相关性系数,并根据相关性系数进行特征选择,包括:
19、筛选出数值列并依据数值列构建数据框,根据述pearson相关系数计算公式计算出一个相关系数矩阵:
20、,
21、其中,表示变量 x和 y之间的相关系数,和分别表示变量 x和 y的均值,和分别表示变量 x和 y的第 i个观测值;相关系数矩阵中的每个元素表示对应两个数值列之间的相关性;
22、提取目标变量isfault与其他数值列之间的相关性系数,并按照绝对值从大到小进行排序;
23、根据相关系数矩阵绘制出热图,得到可视化相关系数矩阵;
24、通过相关性系数分析,选择相关特征作为模型构建特征。
25、作为本实施例一种可能的实现方式,所述步骤s4,基于默认参数利用随机森林分类器建立ssd故障模型;
26、采用默认的随机森林分类器参数建立ssd故障模型,使用训练集数据进行预训练,并对测试集数据进行预测;
27、使用精确率、召回率和f1-score来评估预测结果的准确性。
28、作为本实施例一种可能的实现方式,所述步骤s6,基于贝叶斯优化器进行迭代选择随机森林参数优化,得到ssd故障优化模型,并进行cv交叉验证计算得出优化后的f1-score,包括:
29、定义一个随机森林评估函数,这个函数接收四个超参数[n_estimators,min_samples_split,max_features,max_depth],并返回这些参数进行5折交叉验证后的f1-score平均值;
30、创建一个贝叶斯优化对象,并定义超参的迭代范围:n_estimators:(10,250),min_samples_split:(2,25),max_features:(0.1,0.999),max_depth:(5,15);
31、通过maximize()调用找到最大的f1-score和对应的超参数组合,并根据最优的超参数组合构建出最优随机森林分类器模型,得到ssd故障优化模型。
32、作为本实施例一种可能的实现方式,所述步骤s7,收集各主机节点的ssd smart信息,利用ssd故障优化模型对所有ssd盘进行故障预测,包括:
33、每隔1min收集一次主机节点上的所有ssd的smart信息,并汇聚成一张ssd全集表;
34、利用ssd故障优化模型对所有ssd盘进行故障预测,并发送故障告警信息。
35、第二方面,本发明实施例提供的一种基于机器学习预测ssd故障的装置,包括:
36、数据采集模块,用于采集ssd故障smart信息,构建数据集;
37、数据清理模块,用于采对数据集进行数据清理,并将数据清理后的数据集划分为训练集和测试集;
38、相关性分析模块,用于采对数据集中数值列进行相关性分析,计算出相关性系数,并根据相关性系数进行特征选择;
39、故障模型建立模块,用于采基于默认参数利用随机森林分类器建立ssd故障模型;
40、cv交叉验证模块,用于采进行cv交叉验证,得出ssd故障模型的f1-score;
41、故障模型优化模块,用于采基于贝叶斯优化器进行迭代选择随机森林参数优化,得到ssd故障优化模型,并进行cv交叉验证计算得出优化后的f1-score;
42、故障预测模块,用于采收集各主机节点的ssd smart信息,利用ssd故障优化模型对所有ssd盘进行故障预测。
43、第三方面,本发明实施例提供的一种计算机设备,包括处理器、存储器和总线,所述存储器存储有所述处理器可执行的机器可读指令,当所述计算机设备运行时,所述处理器与所述存储器之间通过总线通信,所述处理器执行所述机器可读指令,以执行如上述任意基于机器学习预测ssd故障的方法的步骤。
44、第四方面,本发明实施例提供的一种存储介质,该存储介质上存储有计算机程序,该计算机程序被处理器运行时执行如上述任意基于机器学习预测ssd故障的方法的步骤。
45、本发明实施例的技术方案所产生的有益效果如下:
46、本发明实施例的技术方案的一种基于机器学习预测ssd故障的方法,以粗粒度的方式区分ssd故障的预测,提前识别故障问题,并发出告警提示二线工程师介入,大大提升了系统性能的稳定性。本发明利用多年收集到的故障ssd smart信息并通过相关性分析选择多个smart属性作为训练模型的特征,基于这些与故障相关的特征,并有效结合监督学习算法,更有效地预测ssd故障。
47、本发明实施例的技术方案的一种基于机器学习预测ssd故障的装置,与本发明实施例的技术方案的一种基于机器学习预测ssd故障的方法具有相同的有益效果。
本文地址:https://www.jishuxx.com/zhuanli/20241021/319529.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表