一种基于大模型的变量提取方法、装置、设备及存储介质与流程
- 国知局
- 2024-10-21 14:50:25
本发明涉及医学数据处理,具体涉及一种基于大模型的变量提取方法、装置、设备及存储介质。
背景技术:
1、现有变量抽取方法,尤其是那些高度依赖于手工编写正则表达式的策略,虽然在处理特定格式和结构的文本数据时展现了一定的有效性,但在面对更加广泛、复杂且多变的实际应用场景时,其局限性便日益凸显。
2、一方面,对于复杂的文本模式,如嵌套结构、不规则分隔符或多种可能的变量格式,编写一个精确匹配所有情况的正则表达式可能需要耗费大量时间进行反复测试和调整。正则表达式的语法复杂且容易出错,即使是经验丰富的开发者也可能因为一个小小的疏忽(如遗漏了一个转义字符、错误的量词使用等)而导致整个表达式无法正确工作。此外,正则表达式的调试过程也相对繁琐,因为错误可能并不直观,而是隐藏在复杂的匹配逻辑之中。另一方面,正则表达式的通用性较差。由于不同数据源或不同领域的文本数据往往具有独特的格式和结构,因此很难设计出一个能够普遍适用的正则表达式来抽取所有类型的变量。这意味着,每当遇到新的文本数据时,开发者都需要根据数据的具体特点重新编写或调整正则表达式,这无疑增加了工作的复杂性和重复性。
3、随着大数据时代的到来,文本数据的规模和复杂性都在不断增加。这不仅体现在数据量的激增上,还体现在数据格式的多样性和动态变化上。对于这样的数据环境,手工编写和维护正则表达式的成本将急剧上升。一方面,需要投入更多的时间和人力资源来编写和测试正则表达式;另一方面,随着数据格式的变化,原有的正则表达式可能需要频繁地进行更新和调整,手工维护和更新正则表达式的成本也随之增加。
技术实现思路
1、解决手工编写正则表达式效率低、容易出错以及维护复杂的问题。本发明提供一种基于大模型的变量提取方法、装置、设备及存储介质。
2、第一方面,本发明技术方案提供一种基于大模型的变量提取方法,包括如下步骤:
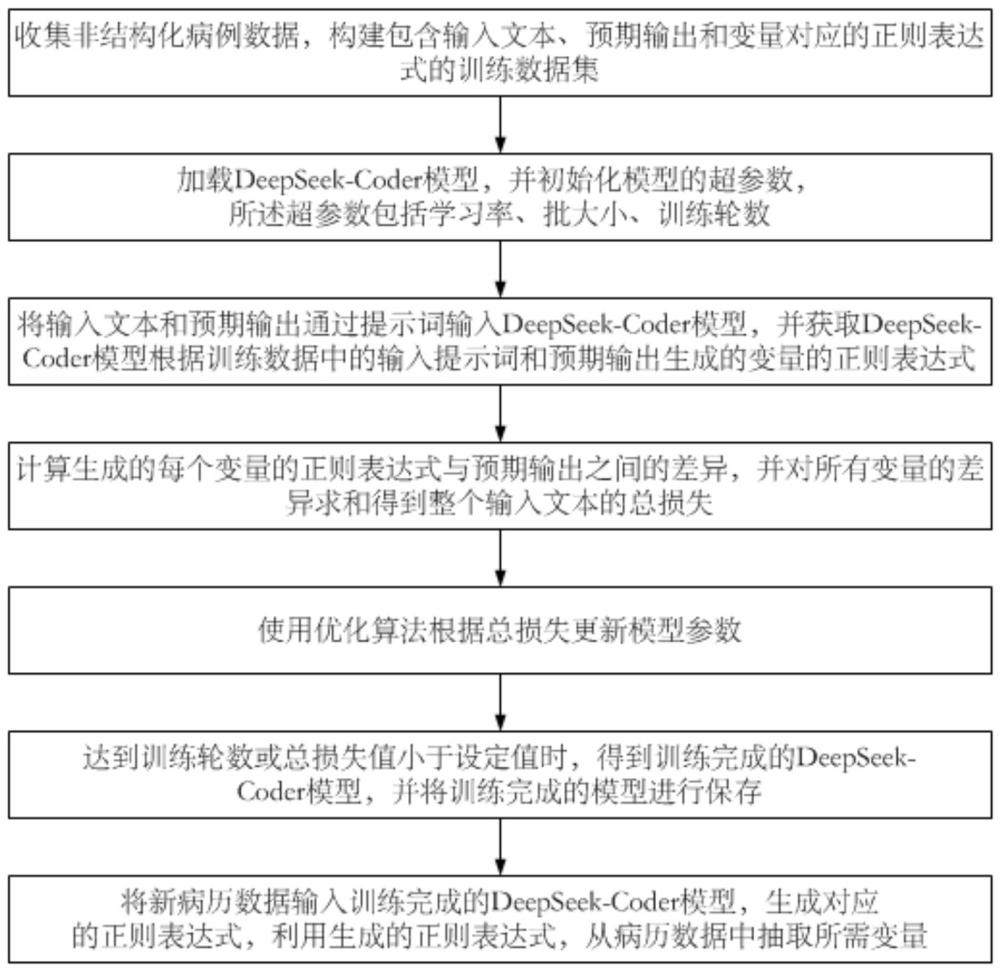
3、收集非结构化病例数据,构建包含输入文本、预期输出和变量对应的正则表达式的训练数据集;
4、加载deepseek-coder模型,并初始化模型的超参数,所述超参数包括学习率、批大小、训练轮数;
5、将输入文本和预期输出通过提示词输入deepseek-coder模型,并获取deepseek-coder模型根据训练数据中的输入提示词和预期输出生成的变量的正则表达式;
6、计算生成的每个变量的正则表达式与预期输出之间的差异,并对所有变量的差异求和得到整个输入文本的总损失;
7、使用优化算法根据总损失更新模型参数;
8、达到训练轮数或总损失值小于设定值时,得到训练完成的deepseek-coder模型,并将训练完成的模型进行保存;
9、将新病历数据输入训练完成的deepseek-coder模型,生成对应的正则表达式,利用生成的正则表达式,从病历数据中抽取所需变量。
10、作为本发明技术方案的进一步限定,收集非结构化病例数据,构建包含输入文本、预期输出和变量对应的正则表达式的训练数据集的步骤包括:
11、收集非结构化病历数据;
12、确定变量提取字段定义与医学人工标注变量;
13、根据医学人工标注数据,生成对应的正则表达式;
14、构建包含输入文本、预期输出和变量对应的正则表达式的数据集;
15、将数据集格式转化为模型训练所需的格式,将输入文本、预期输出和正则表达式组织成json;
16、将格式转化后的数据集按照设定比例划分成训练集和验证集。
17、作为本发明技术方案的进一步限定,将输入文本和预期输出通过提示词输入deepseek-coder模型,并获取deepseek-coder模型根据训练数据中的输入提示词和预期输出生成的变量的正则表达式的步骤之前包括:
18、将训练集中的输入和输出文本进行拼接;
19、使用glm4-9b-chat模型的tokenizer将拼接后的文本转换为token ids。
20、作为本发明技术方案的进一步限定,计算生成的每个变量的正则表达式与预期输出之间的差异,并对所有变量的差异求和得到整个输入文本的总损失的步骤包括:
21、对于每个正则表达式,匹配函数从文本中提取相应的信息;
22、若正则表达式正确并与文本部分匹配,匹配函数将返回匹配的字符串;
23、若没有找到匹配项,匹配函数返回空值;
24、对每个变量,将匹配函数输出的匹配值与预期输出进行对比,并计算编辑距离来衡量匹配函数得到的匹配值与预期输出之间的差异;
25、对所有变量,将各自的编辑距离求和,得到整个输入文本的总损失。
26、作为本发明技术方案的进一步限定,通过编辑距离计算损失函数:
27、
28、式中,n表示变量的数量,表示第个变量的生成匹配值,表示第个变量的预期输出值。
29、作为本发明技术方案的进一步限定,使用优化算法根据总损失更新模型参数的步骤中参数更新公式:
30、
31、式中,表示模型参数,表示学习率,表示损失函数对模型参数的梯度,表示第t次训练的模型参数,表示第t+1次训练的模型参数。
32、作为本发明技术方案的进一步限定,使用优化算法根据总损失更新模型参数的步骤之后包括:
33、在验证集上评估模型性能,调整超参数和训练策略;若损失大于设定范围,则降低学习率,若损失下降幅度小于设定阈值,增加学习率或使用学习率预热和衰减策略优化训练效果;
34、模型评估公式:
35、
36、式中,m表示验证集样本数量,表示第个验证样本的损失。
37、第二方面,本发明技术方案还提供一种基于大模型的变量提取装置,包括数据收集模块、模型初始化模块、训练模块、训练结果处理模块、优化模块、模型获取模块和变量提取执行模块;
38、数据收集模块,用于收集非结构化病例数据,构建包含输入文本、预期输出和变量对应的正则表达式的训练数据集;
39、模型初始化模块,用于加载deepseek-coder模型,并初始化模型的超参数,所述超参数包括学习率、批大小、训练轮数;
40、训练模块,用于将输入文本和预期输出通过提示词输入deepseek-coder模型,并获取deepseek-coder模型根据训练数据中的输入提示词和预期输出生成的变量的正则表达式;
41、训练结果处理模块,用于计算生成的每个变量的正则表达式与预期输出之间的差异,并对所有变量的差异求和得到整个输入文本的总损失;
42、优化模块,用于使用优化算法根据总损失更新模型参数;
43、模型获取模块,用于达到训练轮数或总损失值小于设定值时,得到训练完成的deepseek-coder模型,并将训练完成的模型进行保存;
44、变量提取执行模块,用于将新病历数据输入训练完成的deepseek-coder模型,生成对应的正则表达式,利用生成的正则表达式,从病历数据中抽取所需变量。
45、作为本发明技术方案的进一步限定,数据收集模块包括收集单元、变量确定单元、表达式生成单元、数据集构建单元、格式处理单元和划分单元;
46、收集单元,用于收集非结构化病历数据;
47、变量确定单元,用于确定变量提取字段定义与医学人工标注变量;
48、表达式生成单元,用于根据医学人工标注数据,生成对应的正则表达式;
49、数据集构建单元,用于构建包含输入文本、预期输出和变量对应的正则表达式的数据集;
50、格式处理单元,用于将数据集格式转化为模型训练所需的格式,将输入文本、预期输出和正则表达式组织成json;
51、划分单元,用于将格式转化后的数据集按照设定比例划分成训练集和验证集。
52、作为本发明技术方案的进一步限定,该装置还包括训练集处理模块,用于将训练集中的输入和输出文本进行拼接;使用glm4-9b-chat模型的tokenizer将拼接后的文本转换为token ids。
53、作为本发明技术方案的进一步限定,训练结果处理模块,用于对于每个正则表达式,匹配函数从文本中提取相应的信息;若正则表达式正确并与文本部分匹配,匹配函数将返回匹配的字符串;若没有找到匹配项,匹配函数返回空值;对每个变量,将匹配函数输出的匹配值与预期输出进行对比,并计算编辑距离来衡量匹配函数得到的匹配值与预期输出之间的差异;对所有变量,将各自的编辑距离求和,得到整个输入文本的总损失。
54、作为本发明技术方案的进一步限定,通过编辑距离计算损失函数:
55、
56、式中,n表示变量的数量,表示第个变量的生成匹配值,表示第个变量的预期输出值。
57、作为本发明技术方案的进一步限定,使用优化算法根据总损失更新模型参数的步骤中参数更新公式:
58、
59、式中,表示模型参数,表示学习率,表示损失函数对模型参数的梯度,表示第t次训练的模型参数,表示第t+1次训练的模型参数。
60、作为本发明技术方案的进一步限定,该装置还包括模型验证模块,用于在验证集上评估模型性能,调整超参数和训练策略;具体的,若损失大于设定范围,则降低学习率,若损失下降幅度小于设定阈值,增加学习率或使用学习率预热和衰减策略优化训练效果;
61、模型评估公式:
62、
63、式中,m表示验证集样本数量,表示第个验证样本的损失。
64、第三方面,本发明技术方案还提供一种电子设备,所述电子设备包括:至少一个处理器;以及与所述至少一个处理器通信连接的存储器;存储器存储有可被至少一个处理器执行的计算机程序指令,所述计算机程序指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行如第一方面所述的基于大模型的变量提取方法。
65、第四方面,本发明技术方案提供一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令使所述计算机执行如第一方面所述的基于大模型的变量提取方法。
66、从以上技术方案可以看出,本发明具有以下优点:该方法通过构建包含输入文本、预期输出及变量对应正则表达式的训练数据集,实现了对非结构化病例数据的高效自动化处理。相比传统的人工提取方式,极大地提高了数据处理的效率和准确性,降低了人力成本。利用deepseek-coder模型,结合深度学习的强大能力,能够准确理解输入文本中的语义信息,并生成与预期输出高度匹配的正则表达式。这种基于上下文的变量提取方式,确保了提取结果的准确性和针对性,有助于后续数据分析的准确性和可靠性。通过调整模型的超参数(如学习率、批大小、训练轮数等),可以灵活控制模型的训练过程,以适应不同规模和复杂度的数据集。同时,随着新数据的不断加入,模型可以持续学习并优化,不断提升其变量提取的精度和泛化能力。通过计算生成的正则表达式与预期输出之间的差异,并据此更新模型参数,该方法能够不断减少提取过程中的错误,提高变量提取的准确率。这种基于反馈的迭代优化机制,有助于模型在复杂多变的病例数据中保持稳定的性能。
67、此外,本发明设计原理可靠,结构简单,具有非常广泛的应用前景。
本文地址:https://www.jishuxx.com/zhuanli/20241021/319487.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。