一种基于枢轴语言语义映射的汉越语音翻译方法
- 国知局
- 2024-10-21 15:01:30
本发明涉及一种基于枢轴语言语义映射的汉越语音翻译方法,属于语音翻译领域。
背景技术:
1、汉越语音翻译任务中汉语音频和越南语文本间不仅存在较大的模态差异,还存在较大的跨语言差异,汉语和越南语在语法、词汇和句法结构上有很大差异,这可能导致翻译系统在理解和生成目标语言文本时出现错误或不自然的现象,同时两种语言在表达同一概念时的表达方式和习惯可能不同,导致翻译性能的下降。
2、针对以上问题,在汉越端到端语音翻译跨模态对齐工作的基础上,还需要建立两种语言的跨语言统一映射,将提取出的语义和语法信息映射到统一的语义空间,以提升翻译的准确性和自然性。
3、在文本翻译领域,利用与源语言和目标语言均有良好支持的语言作为枢轴语言构架两种语言的中间统一语义表示,可以有效缓解两种语言语义表示差异问题,传统的利用枢轴语言进行文本翻译的模型结构与级联的语音翻译模型结构相似,利用枢轴语言的文本翻译方法先将源语言翻译为枢轴语言再将枢轴语言翻译为目标语言,级联语音翻译则是先将源语言音频先识别为源语言文本。在端到端语音翻译中通常将源语言文本用作多任务训练中的辅助输入或用于预训练,使端到端模型学习到源语言文本的知识。在汉越语音翻译任务中也可以将枢轴语言作为多任务训练的输入,使端到端语音翻译模型学习到枢轴语言中的跨语言映射关系。
4、基于汉语到越南语跨语言语义差异较大导致模型映射困难的现状,可以使用英语作为枢轴语言来统一汉语和越南语的语义表示,可以通过预训练、对比学习与多任务学习的方式来使端到端语音翻译模型学习到来自不同语料间的跨语言映射,同时通过对比学习的方式缓解语音文本间的跨模态差异,从而提高汉语到越南语语音翻译模型的性能。
技术实现思路
1、本发明通过提供一种基于枢轴语言语义映射的汉越语音翻译方法,解决汉语越南语跨语言语义映射困难的问题,提高汉语到越南语语音翻译模型的性能,
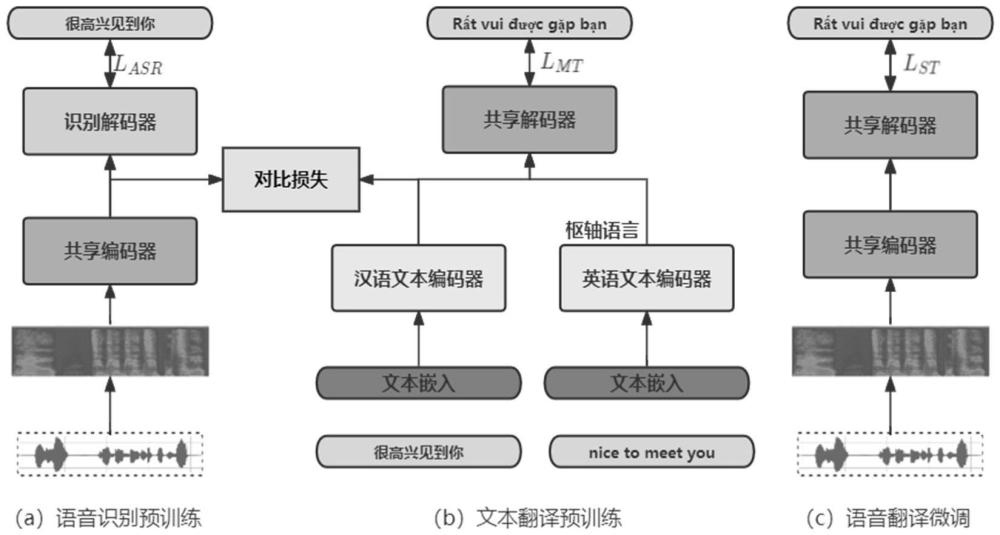
2、本发明技术方案是:一种基于枢轴语言语义映射的汉越语音翻译方法,首先在语音识别预训练阶段通过汉语语音识别任务训练得到语音编码器,将训练得到的语音编码器用作语音翻译模型的编码器,同时预训练得到的语音识别模型也可用于辅助模型推理。在文本翻译预训练阶段进行汉语到越南语与汉语到英语的文本翻译任务进行一对多的多任务训练,在此训练阶段使用对比损失约束文本翻译模型中编码器与语音编码器输出的一致性,以缓和在下一阶段训练过程中存在的模态差异问题。在第三个阶段的训练过程则在前两个预训练的基础上进行,在第一阶段训练得到的编码器与第二阶段训练得到的解码器的基础上进行语音翻译任务的微调。
3、所述方法包括如下步骤:
4、step1:数据的选择。使用aishell公开数据集作为fastspeech2语音合成模型的训练语料,该数据集中,训练集的时长为150小时,说话人数量为340;验证集的时长为10小时,说话人数量为40;测试集的时长为5小时,说话人数量为20。以opus汉越文本翻译公开数据集的汉语文本为基础合成对应的音频,该数据集中,训练集中的汉越文本对数量为60k,验证集中的汉越文本对数量为5k,测试集中的汉越文本对数量为5k。
5、step2:构建语音识别预训练模块,进行语音识别预训练,在语音识别预训练阶段通过汉语语音识别任务训练得到语音编码器,将训练得到的语音编码器用作语音翻译模型的编码器,同时预训练得到的语音识别模型也用于辅助模型推理;
6、语音识别预训练在已有的whisper模型上进行微调。训练阶段主要通过语音识别任务使模型的编码器具有跨模态映射能力,汉越语音翻译模型的编码器将在此阶段训练得到的编码器上进行微调。训练数据为s={(m,s)},其中m=[m1,m2…,mlm]为汉语音频序列,lm为序列长度,s=[s1,s2…,sls]为汉语文本序列,ls为序列长度,微调阶段使用的语料为通过语音翻译语料中的汉语音频和汉语文本对进行;
7、该训练阶段通过语音识别任务使模型的编码器具有跨模态映射能力,汉越语音翻译模型的编码器将在此阶段训练得到的编码器上进行微调;语音识别预训练模块,即微调后的whisper模型包括声学特征提取模块、编码器、解码器;声学特征提取模块使用filterfbank()方法提取音频的梅尔频谱特征,输入为汉语音频序列m,输出梅尔频谱特征序列z:
8、z=filterfbank(m)
9、其中编码器需要在下一训练阶段中使用,称为共享编码器sharedencoder(),梅尔频谱特征序列z经共享编码器编码得到编码语义特征序列ze:
10、ze=sharedencoder(z)
11、编码语义特征序列ze由解码器decoderasr()进行解码,得到汉语文本概率特征序列zf,解码器的output输入为汉语文本序列s;
12、zf=decoderasr(ze,s)
13、模型训练损失函数为交叉熵损失,语音识别任务损失lasr计算过程:
14、
15、step3:构建文本翻译预训练模块;进行文本翻译预训练,在文本翻译预训练阶段进行汉语到越南语与汉语到英语的文本翻译任务进行一对多的多任务训练,在此训练阶段使用对比损失约束文本翻译模型中编码器与语音编码器输出的一致性,以缓和在下一阶段训练过程中存在的模态差异问题;文本翻译预训练模块由两个编码器与一个解码器构成,编码器主要分别对汉语和英语的文本嵌入输入进行语义编码,解码器对越南语作为目标语言进行翻译任务的解码。训练数据为s1={(m,s,t,e)},其中m=[m1,m2…,mlm]为汉语音频序列,lm为序列长度,s=[s1,s2…,sls]为汉语文本序列,ls为序列长度,t=[t1,t2…,tlt]为越南语文本序列,lt为序列长度,e=[e1,e2…,ele]为英语文本序列通过汉语文本翻译得到,le为序列长度,使用汉语到越南语和汉语到英语进行多任务预训练,
16、step4:构建语音翻译微调模块,进行语音翻译微调,在语音翻译微调阶段以汉语音频作为输入,越南语作为目标语言进行训练。
17、训练数据为s2={(m,t)},其中m=[m1,m2…,mlm]为汉语音频序列,ls为序列长度,t=[t1,t2…,tlt]为越南语文本序列,使用filterfbank()方法提取音频的梅尔频谱特征,输入为汉语音频序列m,输出梅尔频谱特征序列z;使用共享编码器sharedencoder()提取编码语义特征序列ze;最后由共享解码器shareddecoder()解码得到越南语文本概率特征yz,如下式所示,共享解码器的output输入为越南语文本序列t;
18、yz=shareddecoder(sb,t)
19、解码器由文本翻译预训练中得到的越南语解码器为基础进行微调,该阶段的训练损失lst:
20、
21、本发明还提供一种基于枢轴语言语义映射的汉越语音翻译系统,包括:
22、语音识别预训练模块:用于进行语音识别预训练,在语音识别预训练阶段通过汉语语音识别任务训练得到语音编码器,将训练得到的语音编码器用作语音翻译模型的编码器,同时预训练得到的语音识别模型也用于辅助模型推理;
23、文本翻译预训练模块:用于进行文本翻译预训练,在文本翻译预训练阶段进行汉语到越南语与汉语到英语的文本翻译任务进行一对多的多任务训练,在此训练阶段使用对比损失约束文本翻译模型中编码器与语音编码器输出的一致性,以缓和在下一阶段训练过程中存在的模态差异问题;
24、语音翻译微调模块:用于进行语音翻译微调,在语音翻译微调阶段以汉语音频作为输入,越南语作为目标语言进行训练。
25、本发明的有益效果是:
26、1、本发明通过提供一种基于枢轴语言语义映射的汉越语音翻译方法,语音识别、文本翻译、语音翻译的多任务联合训练框架进行训练,以此来解决汉语越南语跨语言语义映射困难的问题;提高汉语到越南语语音翻译模型的性能。
27、2、在语音识别预训练阶段通过汉语语音识别任务训练得到语音编码器,将训练得到的语音编码器用作语音翻译模型的编码器,同时预训练得到的语音识别模型也可用于辅助模型推理;
28、3、在文本翻译预训练阶段进行汉语到越南语与汉语到英语的文本翻译任务进行一对多的多任务训练,在此训练阶段使用对比损失约束文本翻译模型中编码器与语音编码器输出的一致性,以缓和在下一阶段训练过程中存在的模态差异问题。在第三个阶段的训练过程则在前两个预训练的基础上进行,在第一阶段训练得到的编码器与第二阶段训练得到的解码器的基础上进行语音翻译任务的微调。
本文地址:https://www.jishuxx.com/zhuanli/20241021/320209.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。