自动驾驶场景挖掘方法、装置、设备、存储介质和程序产品与流程
- 国知局
- 2024-10-21 15:03:36
本技术涉及机器学习,特别是涉及一种自动驾驶场景挖掘方法、装置、计算机设备、计算机可读存储介质和计算机程序产品。
背景技术:
1、场景挖掘在自动驾驶技术中起着至关重要的作用,旨在从海量自动驾驶采集的数据中,搜索和筛选出符合要求的场景数据,通过持续补充模型的训练集,不断提高自动驾驶系统在各类实际应用场景的处理和响应能力。
2、目前一般采用基于规则的数据挖掘方法,具体是通过预设的一系列规则对采集的数据进行匹配,从而筛选出符合规则的数据。但是这种方式依赖于预先定义的规则,无法全面覆盖所有潜在场景;由于图像信息的不确定性,当出现未知的类别或信息,基于规则的方式无法挖掘出有效的信息。
3、另外,传统的方式中还采用数据合成方法来处理数据集中长尾场景不足的问题。具体方式为利用数学变换、随机扰动或基于统计模型的方法,对现有的数据样本进行合成或变异,以生成新的数据样本;在数据合成或变异过程中,针对长尾类别,增加其样本量,以期改善数据集的平衡性。但是这种方式中合成的数据可能无法完全模拟真实数据的统计特性和分布规律,导致数据质量下降;合成过程中可能产生噪声和异常值,这些非真实性的数据样本可能对模型训练产生负面影响。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种自动驾驶场景挖掘方法、装置、计算机设备、计算机可读存储介质和计算机程序产品,能够挖掘出与场景挖掘条件相似的自动驾驶场景,从而增加该自动驾驶场景的训练数据量,提升模型的迭代效率。
2、第一方面,本技术提供了一种自动驾驶场景挖掘方法,包括:
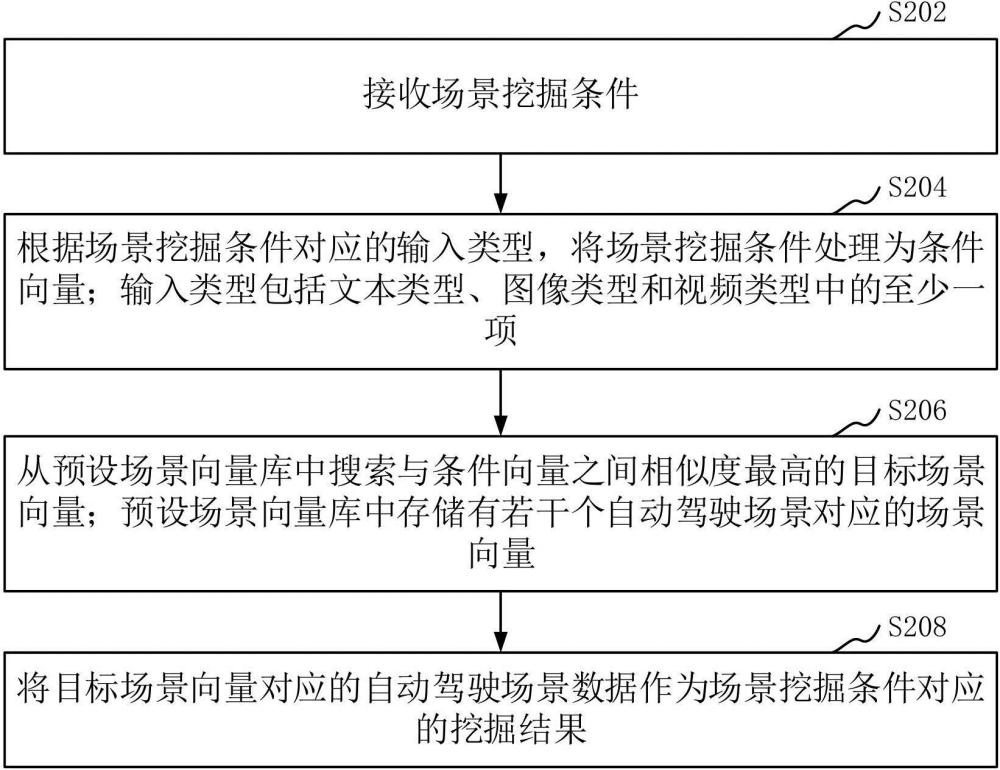
3、接收场景挖掘条件;
4、根据场景挖掘条件对应的输入类型,将场景挖掘条件处理为条件向量;输入类型包括文本类型、图像类型和视频类型中的至少一项;
5、从预设场景向量库中搜索与条件向量之间相似度最高的目标场景向量;预设场景向量库中存储有若干个自动驾驶场景对应的场景向量;
6、将目标场景向量对应的自动驾驶场景数据作为场景挖掘条件对应的挖掘结果。
7、在其中一个实施例中,接收场景挖掘条件之前,所述方法还包括:
8、从自动驾驶系统读取数据文件;
9、对数据文件进行解析,提取出至少一个图像数据;
10、按照驾驶场景对图像数据进行分类,并确定各类图像数据对应的自动驾驶场景数据;
11、从图像数据中提取出图像特征向量;
12、将图像特征向量作为场景向量,并将场景向量和自动驾驶场景数据对应存储至预设场景向量库中。
13、在其中一个实施例中,从图像数据中提取出图像特征向量,包括:
14、对图像数据进行分辨率调整和归一化处理,得到图像输入向量;
15、加载图像编码器;图像编码器包括卷积神经网络和视觉编码器;
16、利用卷积神经网络对图像输入向量进行卷积处理和池化处理,得到图像嵌入向量;
17、利用视觉编码器对图像嵌入向量进行编码处理,并将编码处理后的向量映射至设定长度的向量空间中,得到图像特征向量。
18、在其中一个实施例中,在输入类型为文本类型的情况下,根据场景挖掘条件对应的输入类型,将场景挖掘条件处理为条件向量,包括:
19、对场景挖掘条件进行分词处理,得到文本输入向量;
20、加载文本模型;文本模型包括嵌入处理单元和文本编码器;
21、利用嵌入处理单元针对文本输入向量添加位置编码信息,得到文本嵌入向量;
22、利用文本编码器对文本嵌入向量进行编码处理,并将编码处理后的向量映射至设定长度的向量空间中,得到条件向量。
23、在其中一个实施例中,在输入类型为图像类型的情况下,根据场景挖掘条件对应的输入类型,将场景挖掘条件处理为条件向量,包括:
24、对场景挖掘条件进行分辨率调整和归一化处理,得到条件输入向量;
25、加载图像编码器;图像编码器包括卷积神经网络和视觉编码器;
26、利用卷积神经网络对条件输入向量进行卷积处理和池化处理,得到条件嵌入向量;
27、利用视觉编码器对条件嵌入向量进行编码处理,并将编码处理后的向量映射至设定长度的向量空间中,得到条件向量。
28、在其中一个实施例中,在输入类型为视频类型的情况下,根据场景挖掘条件对应的输入类型,将场景挖掘条件处理为条件向量,包括:
29、将场景挖掘条件解析为若干个帧图片;
30、分别对每个帧图片进行分辨率调整和归一化处理,得到多个输入向量;
31、加载图像编码器;图像编码器包括卷积神经网络和视觉编码器;
32、利用卷积神经网络分别对每个输入向量进行卷积处理和池化处理,得到多个嵌入向量;
33、根据若干个帧图片的帧位置信息,为多个嵌入向量添加时序信息,得到多个目标嵌入向量;
34、利用视觉编码器分别对每个目标嵌入向量进行编码处理,并将编码处理后的各向量映射至设定长度的向量空间中,得到多个条件向量。
35、第二方面,本技术还提供了一种自动驾驶场景挖掘装置,包括:
36、接收模块,用于接收场景挖掘条件;
37、处理模块,用于根据场景挖掘条件对应的输入类型,将场景挖掘条件处理为条件向量;输入类型包括文本类型、图像类型和视频类型中的至少一项;
38、搜索模块,用于从预设场景向量库中搜索与条件向量之间相似度最高的目标场景向量;预设场景向量库中存储有若干个自动驾驶场景对应的场景向量;
39、输出模块,用于将目标场景向量对应的自动驾驶场景数据作为场景挖掘条件对应的挖掘结果。
40、第三方面,本技术还提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
41、接收场景挖掘条件;
42、根据场景挖掘条件对应的输入类型,将场景挖掘条件处理为条件向量;输入类型包括文本类型、图像类型和视频类型中的至少一项;
43、从预设场景向量库中搜索与条件向量之间相似度最高的目标场景向量;预设场景向量库中存储有若干个自动驾驶场景对应的场景向量;
44、将目标场景向量对应的自动驾驶场景数据作为场景挖掘条件对应的挖掘结果。
45、第四方面,本技术还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
46、接收场景挖掘条件;
47、根据场景挖掘条件对应的输入类型,将场景挖掘条件处理为条件向量;输入类型包括文本类型、图像类型和视频类型中的至少一项;
48、从预设场景向量库中搜索与条件向量之间相似度最高的目标场景向量;预设场景向量库中存储有若干个自动驾驶场景对应的场景向量;
49、将目标场景向量对应的自动驾驶场景数据作为场景挖掘条件对应的挖掘结果。
50、第五方面,本技术还提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现以下步骤:
51、接收场景挖掘条件;
52、根据场景挖掘条件对应的输入类型,将场景挖掘条件处理为条件向量;输入类型包括文本类型、图像类型和视频类型中的至少一项;
53、从预设场景向量库中搜索与条件向量之间相似度最高的目标场景向量;预设场景向量库中存储有若干个自动驾驶场景对应的场景向量;
54、将目标场景向量对应的自动驾驶场景数据作为场景挖掘条件对应的挖掘结果。
55、上述自动驾驶场景挖掘方法、装置、计算机设备、计算机可读存储介质和计算机程序产品,接收场景挖掘条件;根据场景挖掘条件对应的输入类型,将场景挖掘条件处理为条件向量;输入类型包括文本类型、图像类型和视频类型中的至少一项;从预设场景向量库中搜索与条件向量之间相似度最高的目标场景向量;预设场景向量库中存储有若干个自动驾驶场景对应的场景向量;将目标场景向量对应的自动驾驶场景数据作为场景挖掘条件对应的挖掘结果。通过上述方式,能够从若干个自动驾驶场景中,快速挖掘出与场景挖掘条件相似的自动驾驶场景,从而增加该自动驾驶场景的训练数据量,提升模型的迭代效率;提供了多模态的挖掘条件输入方式,能够将多模态的场景挖掘条件转换为统一的向量表示,以便基于向量进行高精度地相似度搜索,增强了场景挖掘的灵活性和适应性,扩大了场景挖掘的应用范围。
本文地址:https://www.jishuxx.com/zhuanli/20241021/320344.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表