基于继承联邦学习的异构软件缺陷预测方法
- 国知局
- 2024-11-06 14:23:44
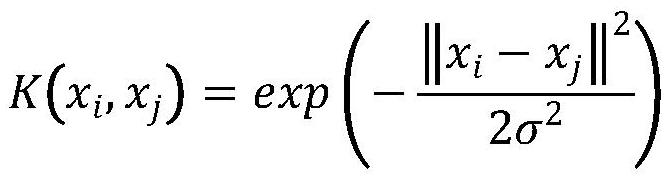
本发明涉及联邦学习、异构软件缺陷预测。
背景技术:
1、深度学习的优势需要建立在大量的数据基础之上,在实际中往往无法提供足够的数据对模型进行训练,导致模型的性能不能达到理想的效果。在大数据的时代下,现代社会正逐渐意识到数据所有权的重要性,随着隐私安全相关法律的健全,软件缺陷数据成为各方的合法隐私,进而形成“数据孤岛”,因此通过收集各方数据来扩大训练数据量就变得十分困难。“联邦学习”(federatedlearning,fl)正是在这种背景下提出和发展的,它能使各参与方无需共享数据资源,即在数据不出本地的情况下进行联合训练,建立共享模型,以隐私安全的方式有效地解决了数据孤岛问题,加速了大数据时代下深度学习技术在各行各业的应用落地。
2、另一方面,由于编译语言、度量元、开发人员的经验习惯等诸多因素的影响,软件缺陷源项目和目标(待测)项目数据存在天然的特征分布差异与数据类不平衡问题,即数据异构,严重影响联邦学习网络模型的性能。因此本发明提出了继承联邦学习算法,在本地训练(个性化)阶段加入继承私有模型(inheritedprivatemodels,ipm)算法,保留了所有历史个性化模型中的知识,用于监督下一轮本地模型的个性化,缓解了模型漂移导致的知识遗忘问题;在全局聚合阶段加入差异感知协作(discrepancy-awarecollaboration,dc)算法,根据全局和本地数据的分布差异重新赋予不同客户端聚合权重,缓解数据异构在服务器端产生的客户端漂移问题,与本地阶段的继承私有模型算法形成训练的正向循环,高效提高预测模型的收敛速度和精度。
技术实现思路
1、本发明以联邦学习为理论基础,为解决软件缺陷预测中单一数据集的数据不充分问题以及多源数据带来的数据异构和隐私性问题,提出了一种基于继承联邦学习的异构软件缺陷预测方法。该方法以联邦学习为框架,在互不侵犯隐私的条件下实现多个参与方协同构建缺陷预测模型。在本地训练阶段加入了继承私有模型算法,以权值动态更新的形式加权平均保存历史训练中所有个性化模型,在下一轮本地模型训练的同时进行知识迁移,在模型初步收敛后停止历史模型的继承;在全局聚合阶段加入了差异感知协作算法,在本地数据量大小占比的基础上,将本地和全局数据分布的差异水平纳入聚合权值的计算中,使拥有较大数据量和较小分布差异的客户端具有大权重。此外,加入了ranger算法更有效地优化目标函数同时生成联邦通信的参数,由于ranger算法在参数更新上加入了多种新型的不可逆的混合运算,因此在联邦通信过程中无法对传输参数进行反演获取原始梯度信息,起到了隐私保护的作用。
2、本发明的目的是这样实现的:
3、一种基于联邦学习的异构软件缺陷预测算法,包括以下步骤:
4、步骤一:对参与方的本地数据集采用综合过采样synthetic minority over-sampling technique combined with tomek links(smotetomek)算法进行数据增强与清洗,得到近似平衡的本地数据;
5、步骤二:对近似平衡的各本地数据集采用核主成分分析(kernel principalcomponent analysis,kpca)算法进行最优特征筛选,达到特征维度一致;
6、步骤三:各参与方将特征维度一致的数据集划分本地训练数据和测试数据。中央服务器采用额外选择的数据集用作全局测试,并构建初始卷积神经网络模型;
7、步骤四:首轮通信中,参与方计算本地与全局数据分布差异,连同数据量大小上传至中央服务器。服务器计算各参与方差异聚合权重并下发初始模型;
8、步骤五:参与方将本地训练数据输入模型进行个性化,同时将包含历史本地模型知识的ipm用于监督模型更新。训练结束后,本地模型与ipm以权值动态更新的形式加权平均更新ipm;
9、步骤六:各参与方将经过ranger算法更新得到的模型参数以隐私保护的形式上传至中央服务器,并将本地测试数据输入模型,计算其混淆矩阵以及auc、g-mean指标;
10、步骤七:中央服务器将各参与方的模型参数通过差异权重进行聚合,获得新一轮的全局模型下发给每个参与方,并将全局测试数据输入该模型,计算全局测试混淆矩阵以及auc、g-mean指标。重复步骤五到步骤七直至达到最大训练轮数;
11、步骤八:将各参与方与服务器将每轮测试得到的auc、g-mean指标绘制成收敛曲线,并画出末轮模型预测的混淆矩阵以直观展现出训练过程与模型性能的变化趋势。
12、进一步地,本发明中,步骤一中,对参与方的本地数据集采用综合过采样smotetomek算法进行数据增强与清洗的过程为:
13、步骤一一:在基于联邦学习的异构软件缺陷预测方法中一共包含5个参与方,所拥有的数据集各不相同,互为异构。各参与方首先对本地数据进行smote过采样,其核心思想是对所有少数类样本使用k近邻寻找邻近样本进行直线随机插值,实现样本的合成。其中,插值的位置是随机的,每个样本点插值的数量是均等的,极度类不平衡样本将过采样为近似平衡。而smote过采样存在局限性,新合成的样本会与周围的多数类样本产生大部分重叠,成为重叠噪声样本,致使分类困难,因此在过采样之后对样本进行清洗是有必要的;
14、步骤一二:采用tomek link欠采样来实现数据清洗的要求,其方法是标记来两个最相邻的不同类别的样本为一对tomek link,则要么其中一个是噪声数据,要么两个样本都在边界附近。通过移除tomek link就能“清洗”类间重叠的噪声样本,使得互为最近邻的样本皆属于同一类别,使分类边界清晰。且由于先经过了smote过采样的数据增强,tomeklink欠采样的信息损失问题也同时得以解决。
15、进一步地,本发明中,步骤二中,对近似平衡的各本地数据集采用kpca算法进行最优特征筛选的过程为:
16、步骤二一:通过径向基函数核函数,利用核技巧实现数据从低维空间到高维特征空间的映射,可以大大降低计算复杂度,同时可以处理软件缺陷数据的非线性可分问题,使得在该空间中数据的线性可分性更强;
17、步骤二二:使用pca对数据进行降维处理,将数据的协方差矩阵特征以重要评分重排,按照25维度的要求选择最优特征子集,将各客户端特征维度统一,为输入联邦学习框架奠定基础。
18、进一步地,步骤二一中,径向基函数核函数的数学表达式为:
19、
20、其中,xi和xj表示输入样本,σ是控制核函数形状的参数。
21、进一步地,本发明中,步骤三中,对不同参与方特征维度一致的软件缺陷数据集的划分以及建立全局cnn网络模型的过程为:
22、步骤三一:5个软件缺陷数据集在经过预处理后,分别根据标签随机分配25%的数据成为本地测试数据集,75%为本地训练数据集;
23、步骤三二:将5组划分好的数据进行归一化与标准化处理,其中训练数据从一维向量转化为二维张量,使其能够符合网络的输入尺寸,即从25个特征维度的一维数据折叠为5×5的二维数据;
24、步骤三三:将5个处理完毕的数据集按照批大小为128的尺寸进行打包,分配到相应参与方的客户端中,为本地数据输入做准备。为体现泛化性能,全局测试数据集采用额外选择的项目数据,经过同样的打包为全局数据输入做准备;
25、步骤三四:构建适合各参与方训练数据的初始cnn模型,具体结构为:输入层→卷积层→relu激活函数→最大池化层→dropout层-1→flattent层→全连接层-1→relu激活函数→dropout层-2→全连接层-2→logsoftmax分类器。
26、进一步地,本发明中,步骤四中,首轮通信服务器计算各参与方差异聚合权重的过程为:
27、步骤四一:设定全局数据分布为均匀分布,均匀分布可以自然地促进所有类别之间的公平性和全局模型的泛化能力;
28、步骤四二:各参与方在本地采用kl散度进行差异度量,根据本地数据分布和全局数据分布计算其差异值。该过程无需额外的数据共享,能够有效防止隐私信息泄露;
29、步骤四三:各参与方将数据量大小与本地差异值上传至服务器。中央服务器分配不同权重到全局聚合阶段不同客户端的通信参数上,每个客户端的聚合权重应根据本地数据量大小占比及本地差异水平共同决定。
30、进一步地,步骤四一中,kl散度度量分布差异的方法为:
31、
32、其中c为总类数,dk和t分别表示本地和全局的数据类分布。
33、进一步地,步骤四三中,差异感知聚合权重计算公式为:
34、
35、其中relu(·)为考虑到负值的非线性激活函数。a为平衡nk和dk的超参数,b为调节权重的另一个超参数。
36、进一步地,本发明中,步骤五中,各参与方本地训练的过程为:
37、步骤五一:设定最大训练轮数和本地模型更新轮数,参与方将训练数据输入模型,同时通过知识蒸馏对ipm的模型参数进行学习,在共同输入下得到损失值,损失值经过ranger算法高效地优化目标函数,得到更新的模型参数。在达到本地更新轮数后,模型个性化结束;
38、步骤五二:完成本地更新后,各参与方将得到的本轮个性化模型与ipm进行加权聚合,权值将会根据训练轮数进行动态调整,得到新的ipm监督下一轮的本地更新过程;
39、步骤五三:当模型初步收敛后,ipm停止聚合更新,减少冗余计算量。
40、进一步地,步骤五一中,ranger算法对模型参数更新的方法为:
41、gt=gt-mean(gt)
42、mt←β12mt-2+(1-β12)gt
43、
44、其中gt为当前模型参数的梯度;mt、vt分别为历史梯度的一阶和二阶动量,为偏置纠正后的动量;超参数β0、β1、β2负责控制动量;
45、
46、其中ut为参数更新矢量,由一二阶动量确定;η为学习率,可以进行自适应调整,tmax为迭代次数,twarmup为学习率预热迭代次数;
47、
48、θt=θt-1-ηtut-ηtdt
49、lt/k←βlookaheadlt/k-1+(1-βlookahead)θt
50、θt←lt/k
51、其中θt代表当前待优化的模型参数,dt为权值衰减项;∈用于数值稳定,一般设置为e-8,βlookahead为慢权重步长,一般为0.5。由于ranger优化器在参数更新上加入了二阶项、偏置纠正、权值衰减、权值融合等多种新型的不可逆的混合运算,并伴随多个自行设置的超参数,因此在联邦通信过程中无法对上传的模型参数进行逆向运算获取原始梯度信息。同时,lookahead算法在最优参数搜索上的思想完全独立于梯度下降法,因此与梯度下降为内核的相关方法相比,常采用的差分分析获取隐私信息也无法对lookahead算法有效果。
52、进一步地,步骤五二中,本轮个性化模型与ipm加权聚合的方法为:
53、
54、其中,为本轮的ipm参数,为聚合后的ipm参数,为本轮个性化模型参数;为第k个参与方的加权系数;t为全局最大训练轮数,μ为控制变量,取默认值0.9。训练轮数越大,ipm中的模型知识越丰富,聚合权值越大。当时,ipm停止聚合更新,保留既有的历史模型知识,退化为独立的私有模型。
55、进一步地,本发明中,步骤六中,计算混淆矩阵以及auc、g-mean指标的过程为:
56、步骤六一:各参与方在一轮训练结束后,根据模型预测结果和样本的真实标签生成混淆矩阵,获得模型对缺陷数据直观的预测情况。
57、步骤六二:根据生成的混淆矩阵计算出本轮监督学习的测试auc、g-mean指标。在达到最大训练轮次后将根据每一轮训练得到的auc、g-mean指标绘制本地测试auc及g-mean关于训练轮数的收敛曲线,用于观察模型的训练走向。
58、进一步地,本发明中,步骤七中,中央服务器通过差异权重进行聚合,得到新一轮全局模型的过程为:
59、
60、其中,为第k个参与方上传到中央服务器的模型参数,pk为步骤四中计算得到的差异感知聚合权重,k为参与方总数,wt+1为聚合参与方模型后得到的全局模型。
61、本发明通过基于继承联邦学习算法,参与方利用ipm算法聚合历史训练中所有个性化模型,在本轮模型更新过程中进行知识迁移,有效地解决了本地训练中模型漂移导致的知识遗忘问题,在多源异构的数据环境下提升了模型的收敛速度、精确度和鲁棒性,并可以在模型初步收敛后及时停止模型的继承;中央服务器利用dc算法以数据量大小占比和差异水平相结合的方式,重新赋予不同数据分布的客户端不同的聚合权重,对计算和通信开销可以忽略不计,对于隐私安全问题不构成威胁,通过这种最佳聚合方案从根源缓解数据异构带来的客户端漂移问题。两个阶段的方法相互协同,产生了训练的正向循环,为异构软件缺陷预测问题提供两种改进的最佳效果;此外,在模型更新过程中,采用了ranger算法优化目标函数,在更高效地达到全局最优解的同时,得到隐私保护形式的模型参数用于与中央服务器之间的安全通信。从实验的结果来看,本发明所提出方法的预测auc、g-mean指标和收敛速度比传统深度学习和联邦学习方法更高,可适用于复杂多样的异构软件缺陷预测场景,具有一定的应用前景。
本文地址:https://www.jishuxx.com/zhuanli/20241106/321796.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表