一种基于机器学习的膀胱肿瘤预后预测方法
- 国知局
- 2024-11-06 14:39:25
本发明涉及数据预测,具体涉及一种基于机器学习的膀胱肿瘤预后预测方法。
背景技术:
1、膀胱肿瘤在预后存在复发的可能性,通过膀胱肿瘤患者的病情档案信息实现膀胱肿瘤预后的复发预测,对膀胱肿瘤患者的肿瘤救治有着重要的影响意义。
2、现有的对膀胱肿瘤患者预后预测,往往基于机器学习算法,通过机器学习算法自身的分类逻辑对样本进行预后预测,但由于不同的膀胱肿瘤患者的个体性差异使得预后的表现不同,在将膀胱肿瘤患者的病情档案作为样本时,机器学习算法忽略了不同样本与预测结果的多维特征联系,导致在分类时错分率较高,进而训练的机器学习预测模型难以有效对于样本分类,造成机器学习预测模型对膀胱肿瘤患者的预测肿瘤复发率预测值预测准确性不足。
技术实现思路
1、为了解决相关技术中预测模型准确性不高,基分类器对病情档案样本的分类效果较差,集成预测模型中基分类器训练迭代对病情档案样本错分率较高,集成预测模型中基分类器迭代收敛速度较慢的技术问题,本发明提供一种基于机器学习的膀胱肿瘤预后预测方法,所采用的技术方案具体如下:
2、本发明提出了一种基于机器学习的膀胱肿瘤预后预测方法,方法包括:
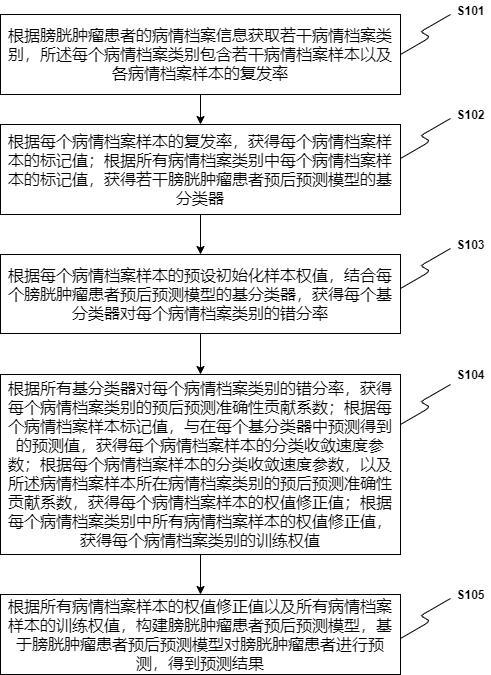
3、根据膀胱肿瘤患者的病情档案信息获取若干病情档案类别,所述每个病情档案类别包含若干病情档案样本以及各病情档案样本的复发率;
4、根据每个病情档案样本的复发率,获得每个病情档案样本的标记值;根据所有病情档案类别中每个病情档案样本的标记值,获得若干膀胱肿瘤患者预后预测模型的基分类器;
5、根据每个病情档案样本的预设初始化样本权值,结合每个膀胱肿瘤患者预后预测模型的基分类器,获得每个基分类器对每个病情档案类别的错分率;
6、根据所有基分类器对每个病情档案类别的错分率,获得每个病情档案类别的预后预测准确性贡献系数;根据每个病情档案样本标记值,与在每个基分类器中预测得到的预测值,获得每个病情档案样本的分类收敛速度参数;根据每个病情档案样本的分类收敛速度参数,以及所述病情档案样本所在病情档案类别的预后预测准确性贡献系数,获得每个病情档案样本的权值修正值;根据每个病情档案类别中所有病情档案样本的权值修正值,获得每个病情档案类别的训练权值;
7、根据所有病情档案样本的权值修正值以及所有病情档案样本的训练权值,构建膀胱肿瘤患者预后预测模型,基于膀胱肿瘤患者预后预测模型对膀胱肿瘤患者进行预测,得到预测结果;
8、进一步地,所述病情档案样本的复发率的具体获取方式为:
9、将任意一个病情档案类别记为目标病情档案类别,将目标病情类别中任意一个病情档案样本记为目标病情档案样本,将所有膀胱肿瘤患者的病情档案信息中,与目标病情档案样本中的数据相同的病情档案样本数量记为目标病情档案样本的同体征样本数量,将与目标病情档案样本中的数据相同的膀胱肿瘤发生复发的病情档案样本的数量,记为目标病情档案样本的复发样本数量,将所述复发样本数量与所述同体征样本数量的比值,记为目标病情档案病例的复发率。
10、进一步地,所述病情档案样本的标记值的具体获取方式为:
11、将每一个病情档案类别中每一个病情档案样本的复发率,作为每一个病情档案样本的标签值,获得每一个病情档案类别中所有病情档案样本的标签值;
12、将每一个病情档案类别中每一个病情档案样本的标签值升序排列,得到每一个病情档案类别的标签值序列;
13、以多阈值分割算法otsu对每一个病情档案类别的标签值序列进行自适应多段分割,获得每一个病情档案类别的标签值序列的若干分割序列;
14、将每一个病情档案类别的每个分割序列中标签值的最大值,作为该分割序列中每一个病情档案样本的标记值,得到所有膀胱肿瘤患者的病情档案信息中每个病情档案类别下每一个病情档案样本的标记值。
15、进一步地,所述根据所有病情档案类别中每个病情档案样本的标记值,获得若干膀胱肿瘤患者预后预测模型的基分类器,包括:
16、将所有病情档案类别中所有病情档案样本作为第一输入数据,输入至决策树算法;
17、根据预设比例将第一输入数据划分为训练集和验证集,以每个病情档案样本的标记值作为决策树的叶节点,利用决策树进行训练分类获得基分类器。
18、进一步地,所述每个基分类器对每个病情档案类别的错分率的具体获取方式为:
19、将任意一个病情档案类别记为目标病情档案类别,将任意一个基分类器记为目标基分类器;
20、将目标病情档案类别中所有的病情档案样本的数值和初始化样本权值作为第二输入数据,输入至膀胱肿瘤患者预后预测模型的目标基分类器中进行预测,获得目标基分类器对于目标病情档案类别中每个病情档案样本的复发率预测值;
21、将目标基分类器对于目标病情档案类别中每个病情档案样本的复发率预测值,与对应病情档案样本的标记值的差值的绝对值,记为目标基分类器对于目标病情档案类别中每个病情档案样本的预测差异值;
22、预设错分阈值;获取目标基分类器对于目标病情档案类别的所有病情档案样本中,满足预测差异值大于错分阈值的病情档案样本数量,记为目标基分类器对于目标病情档案类别的错分样本数量,将目标基分类器对于目标病情档案类别的错分样本数量与目标病情档案类别的病情档案样本的总数的比值,记为目标基分类器对于目标病情档案类别的错分率。
23、进一步地,所述根据每个病情档案类别的错分率,获得每个病情档案类别的预后预测准确性贡献系数,包括:
24、将所有基分类器对于目标病情档案类别的错分率的均值,与所有基分类器对于所有病情档案类别的错分率均值的和的比值,记为目标病情档案类别的预后预测准确性贡献系数。
25、进一步地,所述根据每个病情档案样本在每个基分类器中预测值与标记值,获得每个病情档案样本的分类收敛速度参数,包括:
26、将目标病情档案类别中目标病情档案样本在目标基分类器中的预测差异值,与目标病情档案类别在目标基分类器中所有病情档案样本的预测差异值的最大值的比值,记为目标病情档案类别中目标病情档案样本在目标基分类器中的错分程度;
27、将目标病情档案类别中目标病情档案样本在所有基分类器中的错分程度,根据基分类器训练过程中的更新顺序进行排列,获得目标病情档案类别中目标病情档案样本的错分程度序列;
28、构建目标病情档案类别中目标病情档案样本的二维降维空间,其中横轴为错分程度序列的次序,纵轴为错分程度的数值;
29、使用主成分分析算法对目标病情档案类别中目标病情档案样本的二维降维空间进行降维,获得目标病情档案类别中目标病情档案样本的若干主成分方向,将所述主成分方向中特征值最大的主成分方向的投影向量,记为目标病情档案类别中目标病情档案样本的收敛向量;
30、将目标病情档案类别中目标病情档案样本的收敛向量的模值,与目标病情档案类别中目标病情档案样本在所有基分类器中的错分程度的极差,记为目标病情档案类别中目标病情档案样本的分类收敛速度参数。
31、进一步地,所述病情档案样本的权值修正值的具体获取方式为:
32、将目标病情档案样本所在病情档案类别的预后预测准确性贡献系数,与目标病情档案样本的分类收敛速度参数的乘积,记为目标病情档案样本的权值修正值。
33、进一步地,所述病情档案类别的训练权值的具体获取方式为:
34、将每个病情档案类别中所有病情档案样本的权值修正值的中值,作为每个病情档案类别的训练权值。
35、进一步地,所述膀胱肿瘤患者预后预测模型的具体获取方式为:
36、将所有的基分类器以adaboost迭代算法进行集成,获得膀胱肿瘤患者预后预测初始模型;
37、根据预设比例将所有病情档案样本划分为模型训练集和模型验证集,模型训练集和模型验证集构成膀胱肿瘤患者预后预测初始模型的第三输入数据;
38、将病情档案类别的训练权值作为迭代算法adaboost算法中的类别权值,病情档案样本的权值修正值作为病情档案样本在adaboost算法中的样本权值,获得膀胱肿瘤患者预后预测初始模型的迭代参数;
39、将膀胱肿瘤患者预后预测初始模型的第三输入数据输入至膀胱肿瘤患者预后预测初始模型中,结合膀胱肿瘤患者预后预测初始模型的迭代参数进行训练,直至膀胱肿瘤患者预后预测初始模型的分类精度达到预设分类精度时停止训练,获得膀胱肿瘤患者预后预测模型。
40、本发明具有如下有益效果:
41、本发明根据膀胱肿瘤患者的病情档案信息获取若干病情档案类别以及包含的若干病情档案样本及其复发率;根据每个病情档案样本的复发率,获得每个病情档案样本的标记值;根据所有病情档案类别中每个病情档案样本的标记值,获得若干膀胱肿瘤患者预后预测模型的基分类器,通过对复发率进行分割融合避免基分类器中叶节点过多导致基分类器构建效率降低的问题;根据每个病情档案样本的预设初始化样本权值,结合每个膀胱肿瘤患者预后预测模型的基分类器,获得每个基分类器对每个病情档案类别的错分率;根据所有基分类器对每个病情档案类别的错分率,获得每个病情档案类别的预后预测准确性贡献系数,用于衡量每个病情档案类别与预后病情的关联情况;根据每个病情档案样本标记值,与在每个基分类器中预测得到的预测值,获得每个病情档案样本的分类收敛速度参数,得到每个病情档案样本在进行分类时样本中所包含项目对分类的决策速度影响情况;根据每个病情档案样本的分类收敛速度参数,以及所述病情档案样本所在病情档案类别的预后预测准确性贡献系数,获得每个病情档案样本的权值修正值,得到每个病情档案样本在进行膀胱肿瘤患者预后预测模型的训练过程中,对预测模型构建的影响权重;根据每个病情档案类别中所有病情档案样本的权值修正值,获得每个病情档案类别的训练权值,得到每个病情档案类别在进行膀胱肿瘤患者预后预测模型的训练过程中,对预测模型构建的影响权重;根据所有病情档案样本的权值修正值以及所有病情档案样本的训练权值,构建膀胱肿瘤患者预后预测模型,基于膀胱肿瘤患者预后预测模型对膀胱肿瘤患者进行预测,得到预测结果,本发明旨在通过权值修正值筛除所有病情档案样本中对预后预测模型构建的参考意义不大的样本,以及通过训练权重对不同病情档案类别施加不同的参考权重,从而使得构建膀胱肿瘤患者预后预测模型后,对不同患者的病情档案信息进行快速决策,得到更准确的膀胱肿瘤患者的预后复发率的预测。
本文地址:https://www.jishuxx.com/zhuanli/20241106/323349.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。