一种液体火箭发动机起动过程控制方法及系统
- 国知局
- 2024-12-26 14:49:18
本发明涉及液体火箭发动机领域和强化学习算法,更具体地说,特别涉及一种液体火箭发动机起动过程控制方法及系统。
背景技术:
1、2024年3月14日,spacex的重型可重复使用运载火箭星舰,在经历了前两次发射失败之后,在第三次发射中成功入轨,将航天技术推向新的发展高度。液体火箭发动机的起动过程是一个极其复杂且关键的阶段,涉及到多个系统和子系统的精确协调与控制。传统的控制方法依赖于经验设计的控制策略和固定参数,这虽然在一定程度上保证了发动机的启动性能,但常常因缺乏适应性而难以应对多变的外部环境和内部状态变化。
2、随着人工智能技术的发展,强化学习作为一种能够通过与环境的交互学习最优策略的算法,为动态复杂系统的控制提供了新的解决方案。强化学习通过不断试错来优化控制策略,使得系统能够在未知和变化的环境中找到性能最优化的操作方式。基于强化学习的控制方法已近在航空航天领域的控制中进行了一些初步的研究与应用,并取得较好的结果。因此,强化学习成为一种为液体火箭发动机控制提供一种新的思路和技术途径。
技术实现思路
1、本发明的目的在于提供一种液体火箭发动机起动过程控制方法及系统,以克服现有技术所存在的缺陷。
2、为了达到上述目的,本发明采用的技术方案如下:
3、一种液体火箭发动机起动过程控制方法,包括以下步骤:
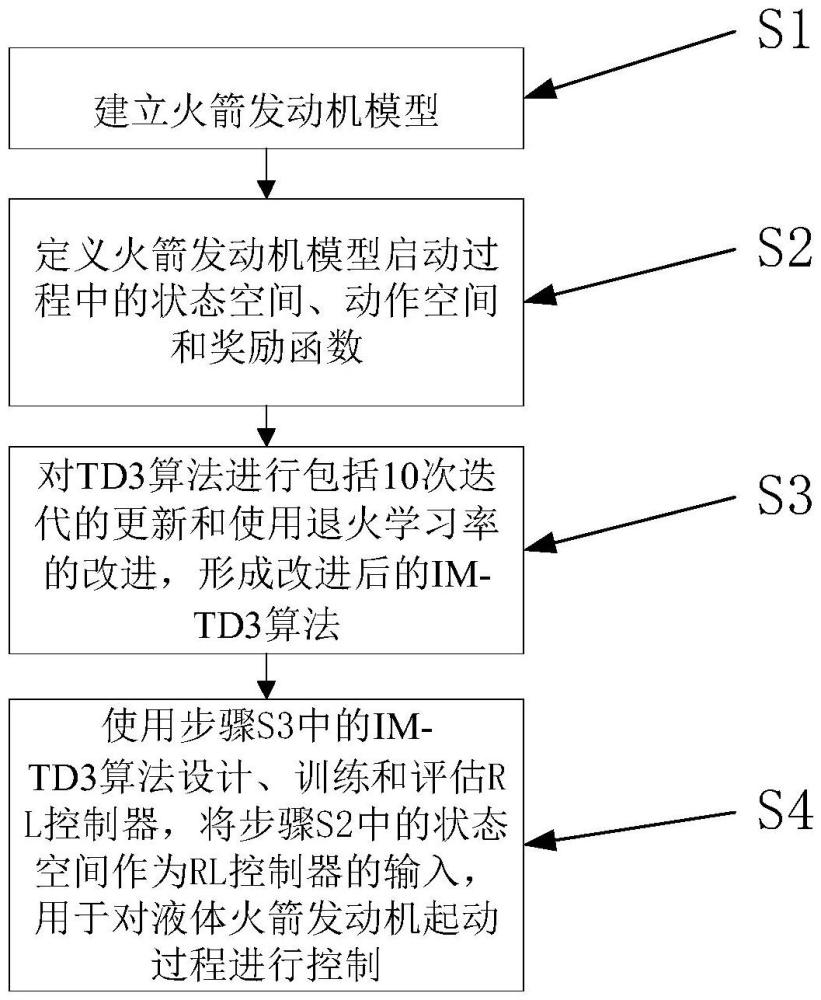
4、s1、建立火箭发动机模型;
5、s2、定义火箭发动机模型启动过程中的状态空间、动作空间和奖励函数;
6、s3、对td3算法进行包括10次迭代的更新和使用退火学习率的改进,形成改进后的im-td3算法;
7、s4、使用步骤s3中的im-td3算法设计、训练和评估rl控制器,将步骤s2中的状态空间作为rl控制器的输入,用于对液体火箭发动机起动过程进行控制。
8、进一步地,所述步骤s1采用仿真软件或编程语言建立火箭发动机模型,该火箭发动机模型可使需要分析的变量能够输出。
9、进一步地,所述步骤s2的状态空间包括涡轮转速、燃烧室压力、混合比和阀门开度,所述动作空间包括启动过程中控制的阀门,所述奖励函数包括启动成功后达到稳态的目标值、导致发动机损坏或启动失败的因素、影响发动机性能的因素。
10、进一步地,所述观察空间s的公式定义为:
11、s=[pg,pc,f,nt,nfpp,mrgg,posvgo,posvgf,posvcf]
12、式中,pg,pc,f,nt,nfpp,mrgg分别为燃气发生器压力、主燃烧室压力、推力大小、主涡轮转速、燃料预压泵转速、燃气发生器混合比,posvgo,posvgf,posvcf为所控制的阀门的开度;
13、所述动作空间a的公式定义为:
14、a=[posvgo,posvgf,posvcf]
15、所述奖励函数的公式定义为:
16、reward=r1+r2+r3+r4+r5
17、式中,εi∈[pg,pc,f,nt,nfpp]对目标值靠近的奖励;
18、r2=1-clip(f-fref/fref|,1);
19、
20、acti∈[posvgo,posvgf,posvcf]分别表示三个阀门的开度,s表示阀门前后两个时间步长之间阀门位置的变化;
21、at表示阀门的开启时间。
22、进一步地,所述步骤s3中改进后的im-td3算法具体包括以下步骤:
23、s30、初始化评价网络qθ1、qθ2和行动者网络πφ,参数θ1、θ2、φ随机赋值;
24、s31、初始化目标网络θ1′←θ1、θ2′←θ2、φ′←φ;
25、s32、初始化回放缓冲区b和学习率调度器;
26、s33、对于t=1至t,执行10次迭代训练更新。
27、进一步地,所述步骤s33中执行10次迭代训练更新具体包括:
28、s330、从回放缓冲区中抽样得到转移(s,a,r,s′,d);
29、s331、禁用目标更新的梯度计算:
30、计算目标动作a′=πφ′(s′)+clip(n(0,σ),-c,c)
31、计算目标动作a′=πφ′(s′)+clip(n(0,σ),-c,c)
32、计算目标qtarget=r+(1-d)·γ·q′
33、s332、使用mse损失更新评价网络:mse(qθ(s,a),qtarget);
34、s333、若i modpolicy_freq=0,通过最大化评价网络的q值来更新行动者网络、软更新目标网络θi′和φ′;
35、s334、使用调度器调整学习率;
36、其中,qθ1,qθ2:由参数θ1和θ2参数化的评价网络;
37、πφ:由参数φ参数化的行动者网络;
38、θ1′,θ2′,φ′表示评价和行动者网络的目标网络;
39、b表示用于存储转移元组的回放缓冲区;
40、s,a,r,s′,d表示从回放缓冲区抽样得到的状态、动作、奖励、下一状态和完成标志;
41、a′表示使用目标行动者网络和噪声剪切计算的目标动作;
42、q′表示使用目标评价网络计算的目标q值;
43、qtarget表示q值更新的目标;
44、γ表示未来奖励的折扣因子;
45、σ,c表示动作空间中噪声生成和剪切的参数;
46、mse表示用于更新评价网络的均方误差损失;
47、policy_freq表示策略更新相对于评价更新的频率。
48、进一步地,所述步骤s4中基于matlab-simulink仿真平台,使用python代码实现基于im-td3算法的rl控制器。
49、本发明还提供一种用于实现上述的液体火箭发动机起动过程控制方法的系统,包括:
50、建模模块,用于建立火箭发动机模型;
51、参数定义模块,用于定义火箭发动机模型启动过程中的状态空间、动作空间和奖励函数;
52、算法改进模块,用于对td3算法进行包括10次迭代的更新和使用退火学习率的改进,形成改进后的im-td3算法;
53、rl控制器设计模块,用于使用步骤s3中的im-td3算法设计、训练和评估rl控制器,将步骤s2中的状态空间作为rl控制器的输入,用于对液体火箭发动机起动过程进行控制;
54、所述建模模块、参数定义模块、算法改进模块和rl控制器设计模块依次连接。
55、与现有技术相比,本发明的优点在于:本发明通过在建立的发动机模型上,确定状态空间、动作空间和奖励函数,使用im-td3算法,设计、训练和评估rl控制器,用于对火箭发动机起动过程进行控制。本发明实现火箭发动机的智能化控制,与传统的开环、闭环控制方法相比,本发明不需要大量的地面试车经验,不需要设计复杂的控制逻辑,通过设计合适的奖励函数能实现复杂的目标,并且与td3算法相比,该方法的在火箭发动机的控制问题上,模型训练的稳定性和收敛性更好。
本文地址:https://www.jishuxx.com/zhuanli/20241226/343543.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表