一种基于多实例学习和多尺度特征提取的胃癌亚型分类方法
- 国知局
- 2025-01-10 13:32:26
本发明涉及病理图像分析挖掘领域,尤其涉及一种基于多实例学习和多尺度特征提取的胃癌亚型分类方法。
背景技术:
1、胃癌是迄今为止全球人类死亡的主要原因之一,死亡率高居世界第二。尽管世界上一些地区的发病率有所下降,但由于大多数病例诊断较晚,预后差,治疗选择有限,胃癌仍然是一个重大的临床挑战。世界卫生组织以癌的组织结构、细胞形状和分化程度为依据,主要把胃癌分为普通腺癌(gastric adenocarcinoma,gac)、粘液腺癌(mucinousadenocarcinoma,muc)和印戒细胞癌(signet ring cell carcinoma,src)。其中,gac最为常见,与其相比,muc的临床病理特征具有显著差异:体积较大;侵袭更深;淋巴结转移率较高。此外,作为muc的一种变异体src也产生大量的黏蛋白,但在临床上表现为恶性度较高的低分化腺癌,易在胃壁呈弥漫浸润性生长,侵袭力强,转移率高,核被挤压于胞质一侧呈“印戒”样,经常到了晚期才被发现。据报道,胃癌的早期准确检测可压倒性的将5年生存率提高约90%。因此,针对muc、gac和src的准确形态学分类在临床诊断中非常有必要的,而病理检测是诊断胃癌各种亚型的金标准,检测结果对治疗计划有很大的影响。
2、在临床环境中,病理学家通常根据观察到的不同尺度下的组织病理图像的形态特征,并参考医学报告进行诊断,而人工诊断过程耗时且具有主观性和不可重复性。目前,研究人员提出了数字病理学领域专用的深度学习方法—多实例学习(multiple instancelearning,mil)。
3、但是,现有的多实例学习受限于单一尺度、过高的计算成本以及未能有效整合病理图像的上下文信息等问题,这往往会导致在亚型分类任务中耗时较长、检测结果误判,不能满足临床辅助诊断的需求。
技术实现思路
1、本发明提供了一种基于多实例学习和多尺度特征提取的胃癌亚型分类方法,以用于胃癌亚型病理图像检测。本发明采用resnet骨干网络提取病理图像在不同放大倍数下的特征;然后,通过并行注意力模块和可微分模块获得较低放大倍数下信息丰富的子图像(tile),并将其与更高放大倍数下的组织病理图像结合,以获取上下文关联信息;最终,通过聚合不同放大倍数下的特征来实现胃癌亚型分类任务。在减少对计算需求的同时,用于普通腺癌、粘液腺癌和印戒细胞癌图像的分类,提高对胃癌亚型检测的准确率,能够满足临床辅助诊断的需要。
2、本发明的技术方案是:一种基于多实例学习和多尺度特征提取的胃癌亚型分类方法,包括:
3、s1、采集胃癌患者组织病理图像和对应的临床标签数据;
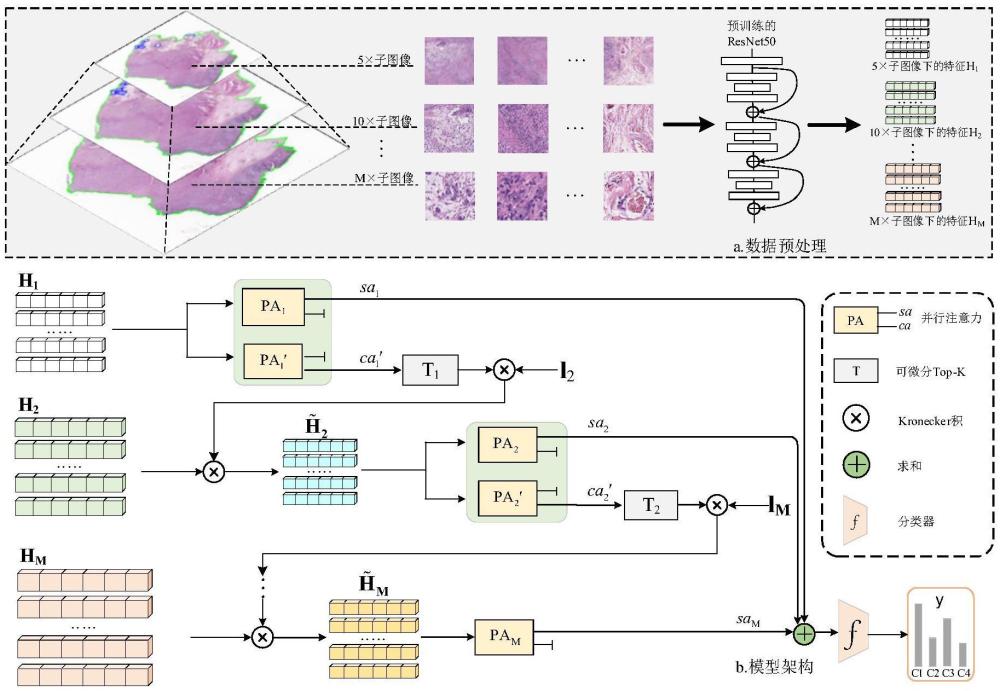
4、s2、对每张原始组织病理图像wsi进行预处理,获得不同放大倍数下组织病理图像的子图像tile;
5、s3、针对s2得到的子图像tile,通过在imagenet数据集上预训练好的resnet骨干网络来提取不同放大倍数下的tile特征,最后把提取后的特征打包成一个.h5文件,并按照8:1:1的比例划分为训练集、验证集和测试集;
6、s4、将s3所得低放大倍数下的病理图像特征送入一个多实例学习并行注意力模块,获得该放大倍数下的通道注意力分数和空间注意力分数;
7、s4中的多实例学习并行注意力模块构建过程如下:
8、s4.1多实例学习是后续任务的基础,输入x是一个由多个实例组成的包,记为x={x1,...,xn};给定一个有c类标签的分类任务,每个实例都有一个未知标签yi∈c,x有一个已知标签y∈c;将原始组织病理图像wsi作为输入,实例表示提取的tile集合;其中,切片级tile-level特征提取器h将每个tile xi映射为特征向量表示张量中每个元素都是d维实数,然后,池化算子g(·)将特征向量hi=1:n,n为特征向量的个数,聚合以生成单张wsi的特征表示;最后,分类器f(·)使用聚合后的特征表示来预测wsi级(wsi-level)的标签所述过程可以总结为:
9、
10、其中,avgpool为平均池化运算;maxpool为最大池化运算;f7×7为7×7的卷积运算;σ为sigmoid激活函数;mlp为共享权重的全连接层;最后,将获得的tile-level的注意力分数si、ci与特征矩阵中对应的特征向量hi分别相乘累加得到wsi-level的空间注意力特征图或空间注意力分数sa和通道注意力特征图或通道注意力分数ca;
11、s5、将s4得到的通道注意力分数通过可微分模块获得放大倍数m倍下信息丰富的tile,并与s3所得的m+1倍数下的特征进行多尺度concat拼接操作;
12、s6、针对s5结合后的结果,进行与s4和s5相同的操作,获得在此放大倍数下的空间注意力分数和信息丰富的tile;
13、s7、上述过程s3-s6重复进行,直至达到最大放大倍数m+n倍为止,最后聚合各个放大倍数下的所有特征进行输出预测;
14、s8、将s3的训练集数据输入多实例学习并行注意力模块,并结合s5中多尺度concat拼接进行训练,之后使用s3的验证集对每一批次训练得到的模型性能进行验证,并保存最好在验证集上取得最好的指标的模型参数作为最终分类模型的权重;最终,在s3的测试集上验证所保存的模型对胃癌亚型病理图像分类的性能。
15、作为对上述方案的进一步描述:s2原始全视野数字切片图像wsi的处理过程包括以下步骤:
16、剔除不匹配数据,对组织病理图像在不同放大倍数下的图片使用滑动窗口裁剪为预设尺寸的子图块,并且过滤掉空白背景超过第一预设阈值的子图块;将所有的子图块进行颜色标准化,上述操作完成后,将剪裁后的子图块按对应的组织病理图像单独保存。
17、作为对上述方案的进一步描述:所述s3中通过在imagenet数据集上预训练好的resnet骨干网络来提取不同放大倍数下的tile特征,具体包括以下步骤:
18、多尺度tile生成:从原始胃癌病理切片图像中提取不同放大倍数下的图像tile,以获取多尺度的信息;
19、resnet预训练:使用在imagenet数据集上预训练好的resnet作为特征提取的骨干网络,预训练好的resnet已经学到了大量通用图像特征,有助于提高特征提取的有效性;
20、特征提取:将不同放大倍数下的tile输入预训练好的resnet网络,提取其对应的特征向量;这些特征向量能够捕捉到tile在不同放大倍数下的细胞、纹理和结构信息;最后,将一整张病理图像所有放大倍数下提取的特征保存为一个.h5文件,方便后续使用。
21、作为对上述方案的进一步描述:将s4得到的通道注意力分数通过可微分模块获得放大倍数m倍下信息丰富的tile,具体过程描述为:
22、当一张wsi在多个放大倍率下可访问时,这些倍数由m∈{1,2,...,m}表示,其中m表示最高的放大倍数,假设当m+1时wsi的放大倍数是m时放大倍数的两倍,为了识别放大倍数为m下的信息tile,需先计算wsi-level通道注意力特征图其中包含了模型对每个tile的通道注意力分数,然后,选择具有最高注意力分数的前k个tile,即top-k运算,并在更高的放大倍数下进一步处理;选择tile的特征矩阵可以表示为:
23、
24、其中,tm∈{0,1}n×k为指示矩阵,hm∈rn×d为放大倍数等于m时tile的特征矩阵;
25、通过分类器f(·)的预测输出来直接进行m处的tile选择,分类器f(·)为由一个全连接层组成的分类头,这可以通过从分类器f(·)的输出到m处的注意力模块反向传播来实现,而不需要引入任何额外的损失或相关超参数;然而,公式(4)并不能直接进行微分操作,因为它涉及到了top-k运算,top-k运算在数学上不是处处可微的;故通过扰动最大值方法来让top-k的选择可微分化,并将其应用于放大倍数为m处的注意力分数cam;具体来说,首先通过添加均匀高斯噪声然后针对这些扰动的注意力权重分别求解一个线性程序,并对结果进行平均,因此,可微分top-k模块的前向传递可以写成:
26、
27、其中,<·>是矩阵矢量化之前的标量乘积;因此表示将扰动后的注意力分数(cam+σz)在第二维度上重复k次,形成一个大小为n×k的矩阵,以便后续运算;对应的雅可比矩阵定义为:
28、
29、其中,表示优化目标,表示决策变量,σ表示噪声标准差,为高斯噪声z的转置矩阵;
30、可微分的top-k运算能够在具体放大倍数下,学习对tile进行加权的注意力分数;这意味着可以让模型自动地学习如何选择有意义的tile,而不依赖预先定义的规则;此外,本发明还保持所有放大倍数下选取的tile大小不变,即不会因为放大倍数而改变;这样可以保持tile数量与放大倍数成正比,使得模型能够捕获各种上下文信息,这对于分析组织病理切片非常重要,因为它们通常包含众多细胞核、细胞质、组织间质与诊断相关的成分;为了结合其他尺度下的tile,把指示矩阵tm进行扩展,以便从tile特征(其中m'>m)中选择有意义的信息;通过计算tm和单位矩阵之间的kronecker积,得到了扩展的指标矩阵;与公式(3)类似,使用来自较低放大倍数m下的注意力权重,在较高放大倍数m'下进行tile的选择:
31、
32、其中,hm'为在放大倍率m'下的特征矩阵,为所选择的特征矩阵;
33、通过上述计算,可以生成一个包含更多信息的指示矩阵,以便在更高放大倍数下进行更细致的tile选择,同时也能够与较低放大倍数下的注意力权重相对应,有助于提升模型对输入数据的处理能力。
34、作为对上述方案的进一步描述:所述s7中聚合各个放大倍数下的所有特征进行输出预测具体描述为:
35、当放大倍数m=1时,特征矩阵h1通过并行注意力模块pam;pam由空间注意力模块pa1和通道注意力模块pa1'组成,pa1用于获取低放大倍数下的最佳池化wsi-level表示sa1;pa1'旨在提供有意义的通道注意力分数ca1,以用于更高放大倍数下tile的选择;然后,使用可微分的指示矩阵t1来选择最具有信息量的tile,并通过公式(7)得到了更高放大倍数的tile特征矩阵上述过程重复进行,直至达到最高放大倍数m为止;随后,在m处选择的tile特征通过最后一个并行注意力模块pam,生成最高放大倍数下的特征表示sam;此外,由于病理图像中不同尺度下的特征密切相关,并且求和利用了特征之间的互补性,因此将所有放大倍数的注意力池化特征表示sa1,sa2,…,sam通过求和池化进行聚合,来获得多尺度、上下文感知的wsi-level表示;最终分类器f(·)将wsi-level的表示映射到相应的标签y∈c,并输出模型预测此过程可以看作是对公式(1)的扩展,在多个放大倍数下进行求和池化:
36、
37、本发明还提供一种基于多实例学习和多尺度特征提取的胃癌亚型分类系统:包括上述方法中的模块。
38、与现有技术相比,本发明的有益效果是:本发明至少解决了多实例学习组织病理图像分类方法中的三个难点问题:现有的mil方法受限于单一尺度、过高的计算成本以及未能有效整合病理图像的上下文信息。针对这些问题,本发明首先使用resnet骨干网络提取病理图像在不同放大倍数下的特征;然后,通过并行注意力模块(parallel attentionmodule,pam)和可微分模块获得较低放大倍数下信息丰富的子图像(tile),并将其与更高放大倍数下的组织病理图像结合,以获取上下文关联信息;最终,通过聚合不同放大倍数下的特征来实现胃癌亚型分类任务。相对于目前先进方法,本发明仅需要更少的计算资源就能达到一个更佳的识别精度,以满足临床辅助诊断的需要。
本文地址:https://www.jishuxx.com/zhuanli/20250110/353798.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
TBM围岩分类方法与流程
下一篇
返回列表